Table of Contents
推荐系统01-常见的业务指标#
广告投放中的ROI是如何计算的?#
ROI:Return on investment(投资回报率),广告投放效果回报和成本投入比。
用谷歌官方的例子:某产品成本100刀,卖200刀,你卖了6件,销售收入1200刀,广告花费是200刀。
赚的利润:1200 - 100 * 6 - 200 = 400
成本投入:6 * 100 + 200 = 800
ROI = \(\frac{(1200 - (6 * 100 + 200))}{(6 * 100 + 200)} = 0.5\),即投资回报率是50%。
广告计算常见的模型评估指标有哪些?#
点击率(CTR)#
广告点击率,是指广告曝光期间,广告的点击比例。
转化率(CVR)#
转化率是指广告点击后,订单成交的成功率,广告转化是否良好,能够直接看出一则广告的成效如何。
常见的广告计费模式有哪些?#
CPM#
CPM(Cost Per Mille)按照展示计费,表示广告每展现给1000个人所花的成本,所以也叫千人展现成本。例如某个广告千次曝光的价格为10元,则CPM=10
CPC#
CPC(Cost Per Click)按照每次点击广告的价格付费。如果一个广告单次点击价格为0.1元,则CPC=0.5
假设你设置广告竞价为0.1元(用户每次点击付费0.3元),广告展现了500次,点击了100次,那么你只需要为这100次点击付费,应该支付的费用为0.1*100=10元
CPC收费模式的好处与弊端:
只为点击付费
广告费用一般会逐年升高(竞价)
无法避免恶意点击
CPA#
CPA(Cost Per Action)按行动付费,即按转化付费。这里的行动可以是表单、加购、下单等,需要与广告主约定好。
CPA总广告费=出价*行动次数
oCPX#
oCPX是Facebook先推,后为各移动广告平台广泛采用的一种计费模式,这里的X可能是M,也能是C,也就是说广告平台仍然按照CPX计费模式进行计费,但会根据后续的转化目标进行优化。也就是说,虽然计费模式仍然是CPX,但是供给方(媒体、变现平台)会承担点击率和点击价值估计的任务。
常见的业务指标:LT、LTV、CAC、ARPU?#
推荐阅读⭐️⭐️⭐️⭐️⭐️
各指标的含义是什么?#
LT、LTV、CAC、ARPU这几个业务指标的含义如下:
LT:Life Time,用户生命周期,用户首次访问至末次访问期间的活跃天数
LTV:Life Time Value,用户生命周期价值,用于衡量用户对产品产生的价值
CAC:Customer Acquisition Cost,用户获取成本
ARPU:Average Revenue Per User,用户平均收益
LTn的计算方式#
LTn计算方式:
例如:
ARPU的计算方式#
ARPU计算公式:
LTV的概念及算法#
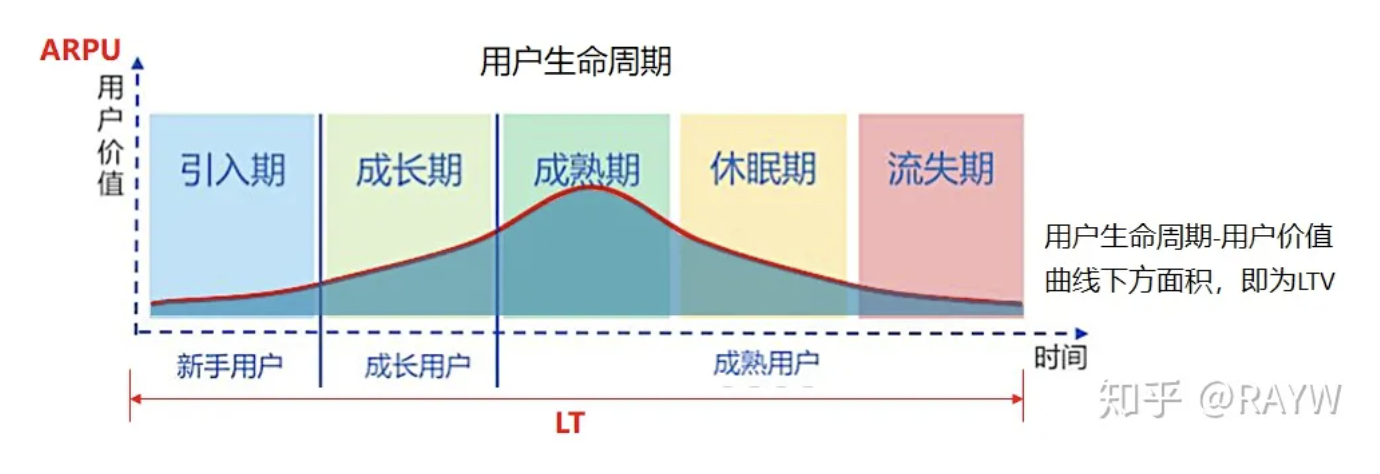
LTV与CAC的关系:要保证产品不亏损,就需要保证用户在整个生命周期中给产品带来的价值大于获取用户所耗费的成本,即LTV>CAC(CAC为获得单个客户的平均费用)。从最本质的角度来说,LTV 的计算公式非常质朴,就是:
但绝大部分情况下需要的是平均LTV,所以公式应为:
同时大部分情况下付费都是阶段性(这里以周为例)统计的,所以LTV最常见而又最本质的计算公式为:
表面上看只是一个简单的数学变换,但其中的重要意义是将计算指标回归到产品本身。如何理解?像用户数、收入等数据,本质上只是统计结果,并不能反映产品本身的属性(比如同一个产品在快速上升期时,周用户数会有很大增幅,但产品本身并无太大变化),而相比之下,留存率和ARPU这两个指标都是直接描述产品的现状,这样的好处在于:
做预测的时候有更强的时效性;
留存率和ARPU能通过更多更准确的方式被预测和建模,甚至能联动或排除实际业务的影响;
计算过程为:
收集足够的留存率和ARPU
分别对留存率和ARPU进行建模拟合
根据拟合结果预估生命周期(留存率为零时或ARPU为零时)
代入数据和公式计算结果
LTV的估算方式:
其中LT是用户平均生命周期天,ARPU是用户日人均收入,经验证,在公式中参数估算较准确的情况下,长期来看总收入与\(LTV \codt 总用户数\)差距不大,LTV能准确的衡量用户价值。
计算用户生命周期价值实战案例#
目标:以2021.12.01 ~ 2021.12.07之间的七天留存率来预估14日留存、30日留存等。
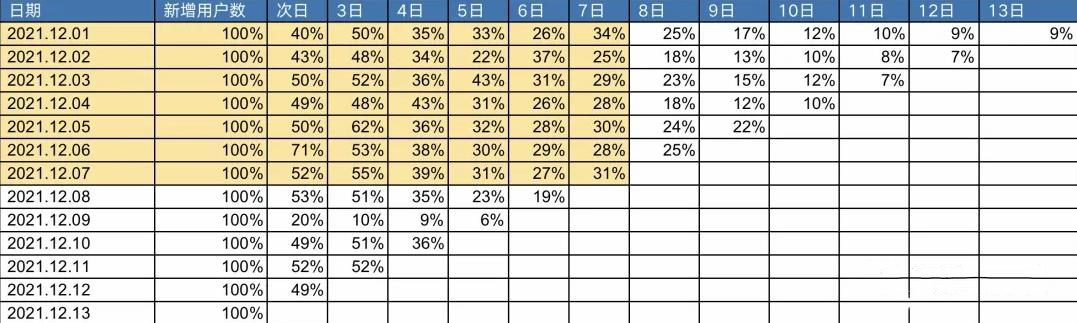
先将黄色部分的七天的留存率取均值,得到图上最下方的留存平均值。
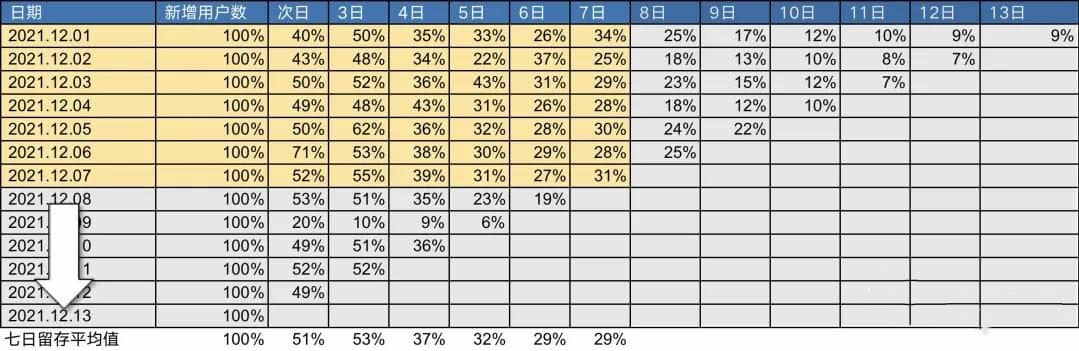
然后按照留存率的均值做拟合,拟合后的结果如下图所示。
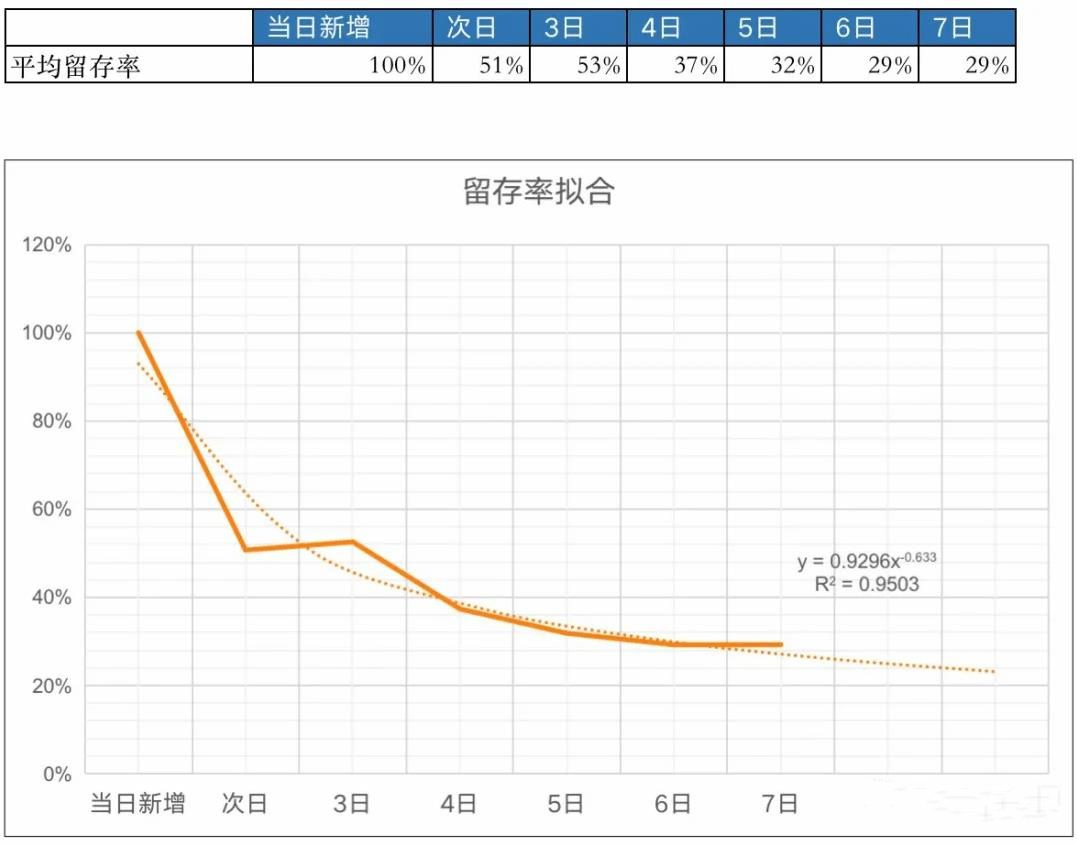

首先计算LT14:LT14=100%+51%+53%+37%+32%+29%+29%+25%+23%+22%+20%+19%+18%+17% = 4.75天,下一步就是计算ARPU了。ARPU值直接取日均值就可以了,假如ARPU日均值是¥60,则LTV14=4.75*60=285。
AUC#
推荐阅读⭐️⭐️⭐️⭐️⭐️
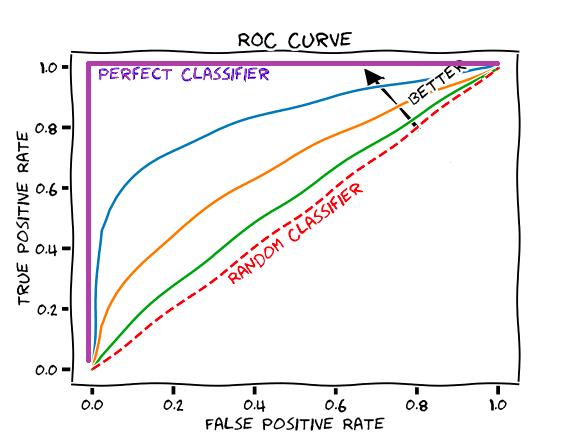
AUC评估的是模型的排序能力,表示随机选一个正样本和一个负样本,模型打分正样本高于负样本的概率,AUC对具体的score不敏感,AUC越大,模型的排序能力越强。
ROC曲线:
横轴:假正率(False Positive Rate),表示负样本被预测为正样本的比例
纵轴:真正率(True Positive Rate),表示正样本被预测为正样本的比例
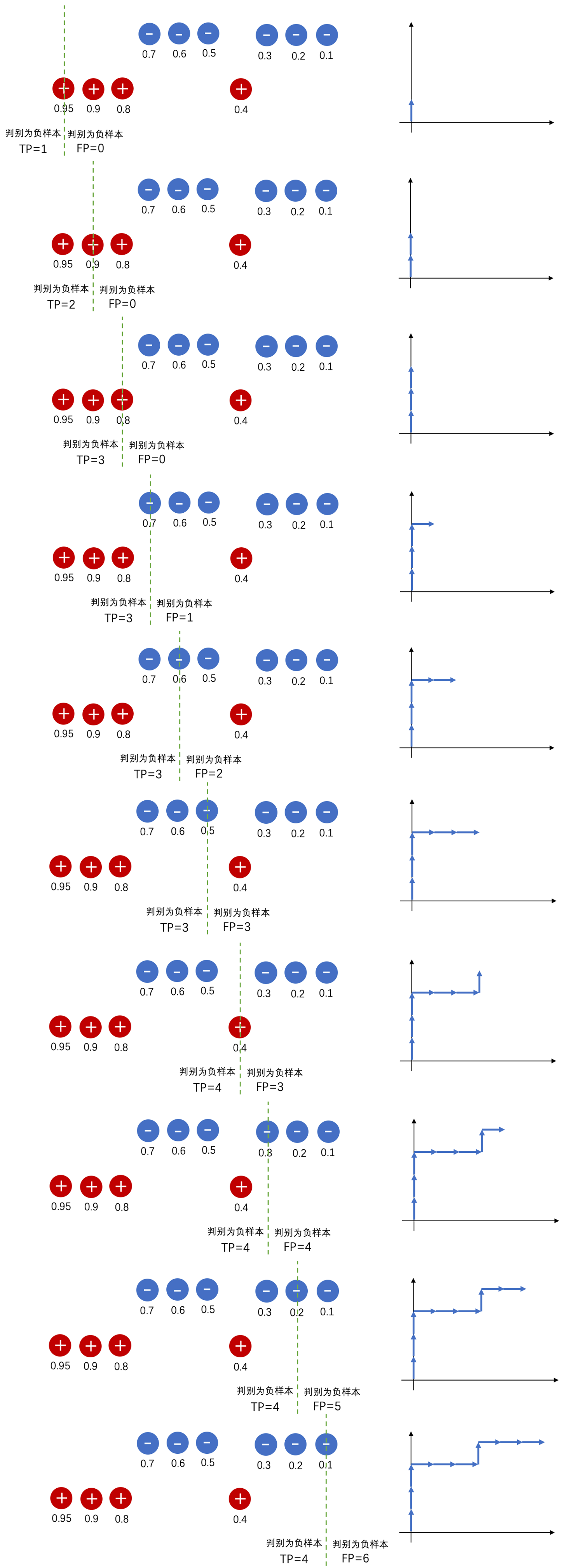
绘制ROC曲线(遍历过程):
将所有样本按照模型打分的score进行降序排列
遍历所有阈值,并计算该阈值下的TP和FP,从而得到原始ROC曲线上的一个点
最后坐标轴归一化至[0,1]
对原始ROC曲线进行坐标轴进行归一化,得到ROC曲线,以及AUC:
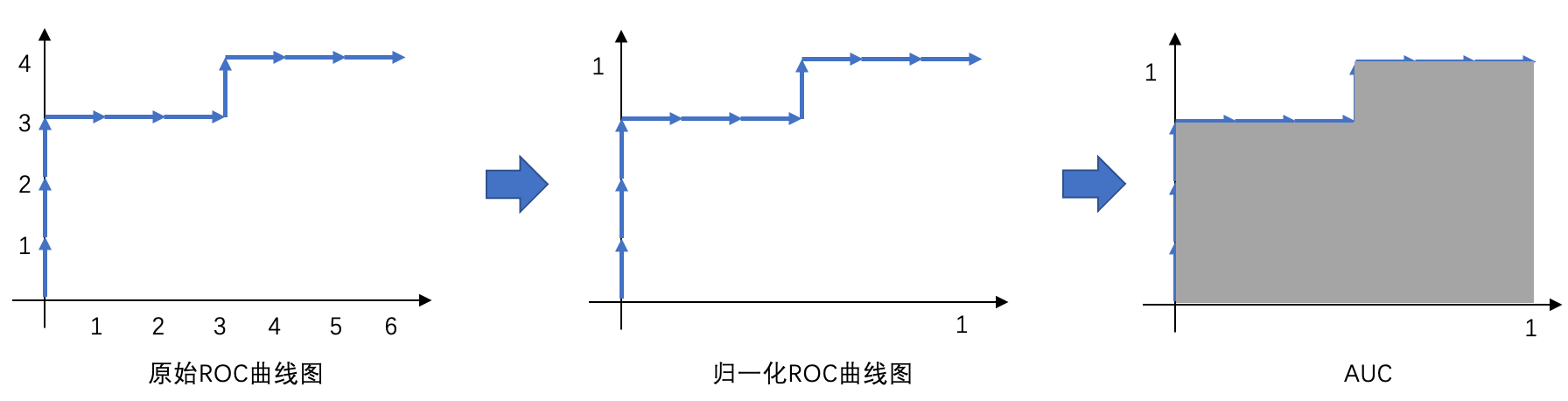
AUC即归一化后ROC曲线下的面积:
大厂海量数据实现方式如下:
# encoding: utf-8
data = {
"0.95": [0, 1, 1],
"0.90": [0, 1, 1],
"0.80": [0, 1, 1],
"0.70": [0, 1, 0],
"0.60": [0, 1, 0],
"0.50": [0, 1, 0],
"0.40": [0, 1, 1],
"0.30": [0, 1, 0],
"0.20": [0, 1, 0],
"0.10": [0, 1, 0]
}
def cal_auc(data):
"""
cal_auc
"""
data_sort = sorted(data.items(), key=lambda x: x[0], reverse=True)
ack = [x[1][1] for x in data_sort]
clk = [x[1][2] for x in data_sort]
sample_num = sum(ack)
pos = sum(clk)
neg = sample_num - pos
if pos < 1 or neg < 1:
return 0
roc_arr = []
tp = fp = 0
for i, j in zip(ack, clk):
tp += j
fp += (i - j)
roc_arr.append((float(fp) / neg, float(tp) / pos))
auc = 0
prev_x = 0
for x, y in roc_arr:
auc += (x - prev_x) * y
prev_x = x
return round(auc, 5)
print(cal_auc(data))
0.875
GAUC#

其中,u1和u2表示两个用户,+和-分别表示正、负样本。按照上一小节的公式计算两个模型AUC如下:
模型1:0.50
模型2:0.67
从AUC来看,模型2要优于模型1。但当针对单个用户来看时,发现模型2和模型1的排序结果是一样的。因此,模型的全局AUC提升,并不能带来单个用户的Item排序的提升。2017年,阿里妈妈精准定向检索及基础算法团队在Deep Interest Network(DIN)中提出了Group AUC(GAUC),用于评估模型对不同用户之间的item排序的效果。
GAUC的思想可以简单理解为:将样本进行分组(Group),然后在采用AUC来评估各组内的排序,最后对各组的AUC进行加权,得到GAUC:
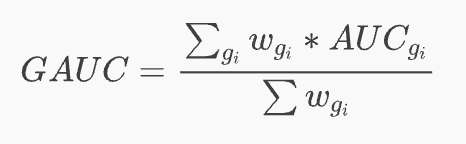
其中\(g_i\)表示第i个样本组,\(w_{g_i}\)表示第i个样本组的权重,\(AUC_{g_i}\)表示第i个样本组的AUC,各用户组的权重可以是曝光、点击、观看时长等,需根据实际业务做调整。
推荐系统召回侧精确率和召回率#

如上图所示,要了解各个评价指标,首先需要知道混淆矩阵,混淆矩阵中的P表示Positive,即正例或者阳性,N表示Negative,即负例或者阴性。表中:
FP表示实际为负但被预测为正的样本数量
TN表示实际为负被预测为负的样本的数量
TP表示实际为正被预测为正的样本数量
FN表示实际为正但被预测为负的样本的数量
TP+FP表示所有被预测为正的样本数量
FN+TN为所有被预测为负的样本数量
TP+FN为实际为正的样本数量
FP+TN为实际为负的样本数量
评估召回模型的准召时:
TP:当前召回路有召回,用户有点击
FP:当前召回路有召回,用户无点击
FN:当前召回路无召回,用户有点击
TN:当前召回路无召回,用户无点击