Table of Contents
推荐系统02-技术基础#
beam search#
推荐阅读⭐️⭐️⭐️⭐️⭐️
简介#
Beam Search(集束搜索)是一种启发式图搜索算法,通常用在图的解空间比较大的情况下,为了减少搜索所占用的空间和时间,在每一步深度扩展的时候,剪掉一些质量比较差的结点,保留下一些质量较高的结点。这样减少了空间消耗,并提高了时间效率,但缺点就是有可能存在潜在的最佳方案被丢弃,因此Beam Search算法是不完全的,一般用于解空间较大的系统中。
贪心搜索(greedy search)#
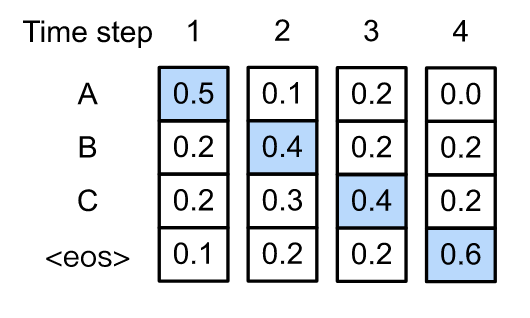
贪心搜索最为简单,每一个时间步都取出了条件概率最大一个结果。
集束搜索(beam search)#
而beam search是对贪心策略一个改进。思路也很简单,就是稍微放宽一些考察的范围。在每一个时间步,不再只保留当前分数最高的1个输出,而是保留num_beams个。当num_beams=1时集束搜索就退化成了贪心搜索。
下图是一个实际的例子,每个时间步有A、B、C、D、E共5种可能的输出,图中的num_beams=2,也就是说每个时间步都会保留到当前步为止条件概率最优的2个序列。
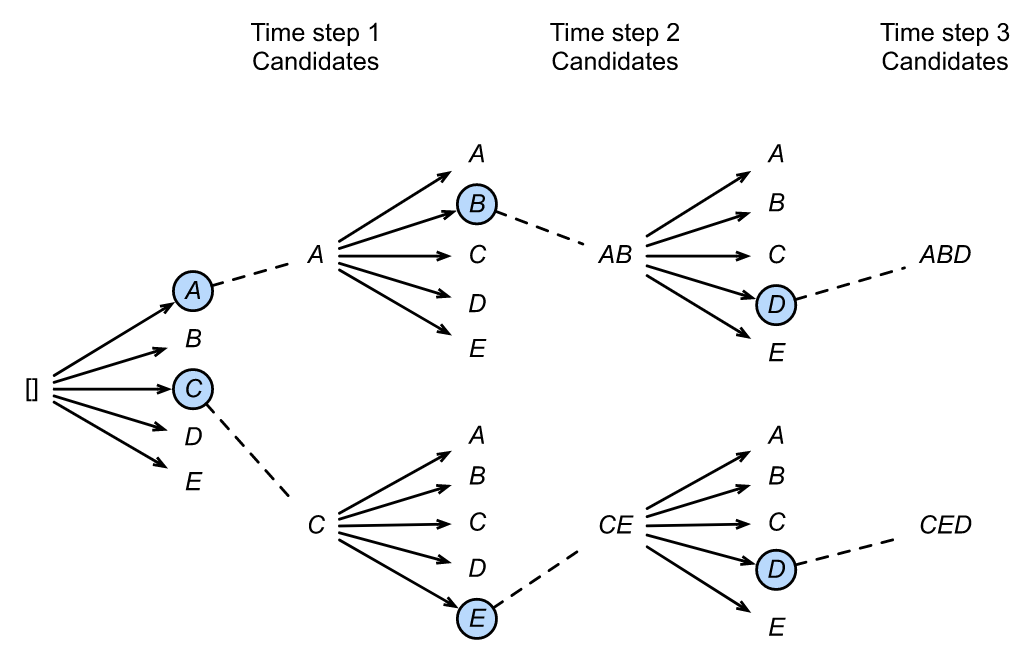
第 1 个时间步,A和C是最优的两个序列,因此得到了两个结果
[A],[C],其他三个就被丢弃了;第 2 个时间步,得到10个候选
[AA],[AB],[AC],[AD],[AE],[CA],[CB],[CC],[CD],[CE],对这10个序列进行统一排名,再保留最优的两个序列,即[AB]和[CE];第 3 个时间步,得到10个候选
[ABA],[ABB],[ABC],[ABD],[ABE],[CEA],[CEB],[CEC],[CED],[CEE],对这10个序列进行统一排名,再保留最优的两个序列,即[ABD],[CED]。
可以发现,beam search在每一步需要考察的候选人数量是贪心搜索的num_beams倍,因此是一种牺牲时间换性能的方法。
SimHash#
推荐阅读⭐️⭐️⭐️⭐️⭐️
在许多场景中,都会遇到海量数据相似度计算的问题,如:电商场景中根据商品embedding计算相似度,取出相似的topk个商品。然而,这种计算相似度需要笛卡尔积的时间复杂度,在数据量较小时,时间还可以接受,但是当数据量达到几十万甚至几百几千万时,是没有办法接受的,这个时候就需要想其他办法。本文主要介绍海量item之间相似度计算问题——局部敏感哈希(Locality-Sensitive Hashing, LSH)之SimHash算法原理。
假设有3个商品,即:item1、item2和item3,每个商品用二维的embedding来表示,同时随机初始化6个超平面,即:s1、s2、s3、s4、s5和s6,每个超平面也是一个二维的embedding,这时可以在二维平面直角坐标系下表示,如下图:
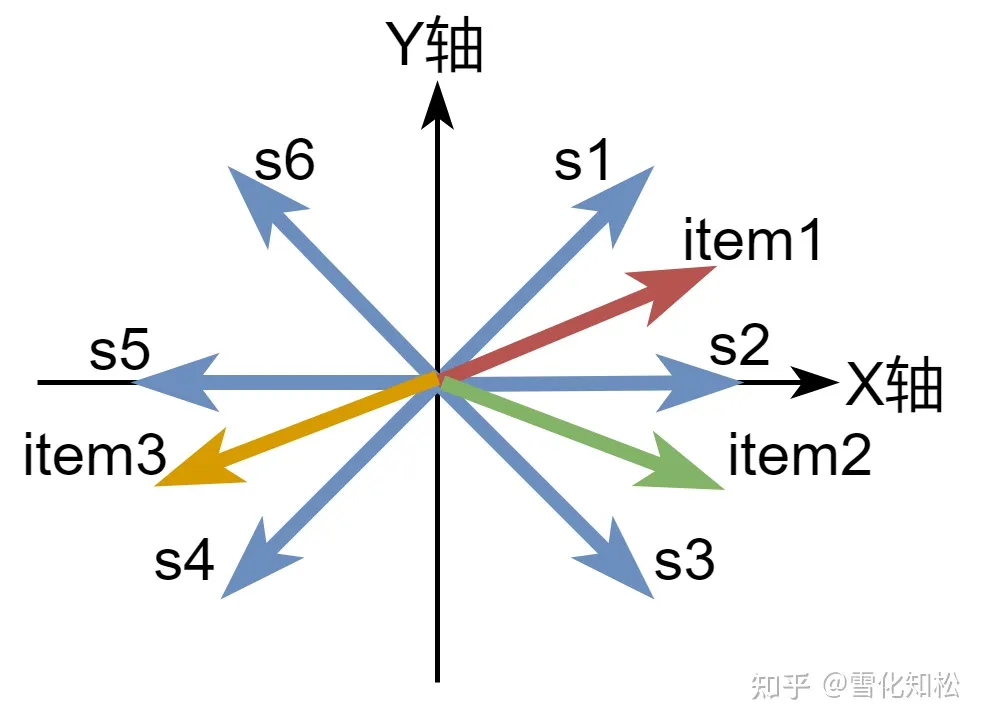
接下来,我们让每个item分别与6个超平面进行向量点积(相似度计算的一种方式),如果结果大于0,则结果为1,否则结果为0。因此会有如下结果表格:
s1 |
s2 |
s3 |
s4 |
s5 |
s6 |
SimHash |
|
|---|---|---|---|---|---|---|---|
item1 |
1 |
1 |
1 |
0 |
0 |
0 |
111000 |
item2 |
1 |
1 |
1 |
0 |
0 |
0 |
111000 |
item3 |
0 |
0 |
0 |
1 |
1 |
1 |
000111 |
通过上面的表格,item1、item2和超平面s1、s2、s3的相似度(向量点积)大于0,对应表格中的值1;与s4、s5、s6的相似度小于0,对应表格中的值0。同理,item3和超平面s1、s2、s3的相似度小于0,对应表格中的值0;与s4、s5、s6的相似度大于0,对应表格中的值1。这时,把每个超平面叫做哈希函数,SimHash值是每个item与各个超平面向量点积后的二进制结果。我们发现item1与item2的SimHash值是一样的,而与item3的SimHash值不同。这时把SimHash值相同的放在一个桶里面,如下图:
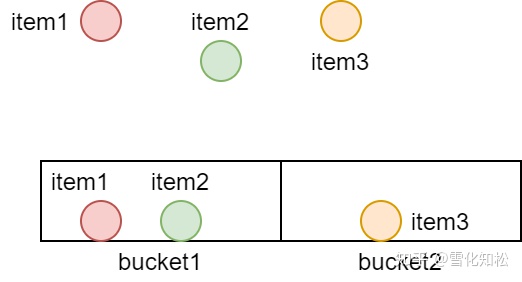
如果有几十万这样的item,SimHash算法计算后,每个桶都会有一定数量的item。这时计算item的topk个相似item时,只需要将此item与对应桶中其他item进行相似度计算,然后找到其topk个相似的item。下面是SimHash算法伪代码:

TF-IDF#
TF-IDF算法通常用于提取一篇文章的关键词,算法的核心思想比较简单,我们也可以加以拓展应用到推荐系统中。
词频 TF 计算方式#
词频的计算方式有多种,比较常见的为方式一,在提取文章关键词的场景下,方式一和方式二是等价的(计算每个词的TF-IDF值,方式二相对于方式一相当于都除了同一个常数,而后按照TF-IDF值倒排取TOPN个词作为文章的关键词)。
方式一:
方式二:
逆文档频率 IDF 计算方式#
TF-IDF 计算方式#
代码实现#
# -*- coding: utf-8 -*-
import math
from collections import defaultdict
# 示例文档
documents = [
"The quick brown fox jumps over the lazy dog.",
"Never jump over the lazy dog quickly.",
"A quick brown dog outpaces a quick fox."
]
def preprocess(doc):
"""预处理文档"""
return doc.lower().replace('.', '').split()
def compute_tf(doc):
"""计算词频TF"""
tf_dict = defaultdict(int)
for word in doc:
tf_dict[word] += 1
doc_len = len(doc)
for word in tf_dict:
tf_dict[word] /= float(doc_len)
return tf_dict
def compute_idf(docs):
"""计算逆文档频率IDF"""
N = len(docs)
idf_dict = defaultdict(int)
all_words = set(word for doc in docs for word in doc)
for word in all_words:
containing_docs = sum(1 for doc in docs if word in doc)
# math.log 计算出来的值可能会是负数,尤其是当词频很高时(例如,词出现在所有文档中)
# 添加1到最终的IDF值:避免负值并确保所有IDF值都是正的
idf_dict[word] = math.log(N / (1 + containing_docs)) + 1
return idf_dict
def compute_tfidf(tf, idf):
"""计算TF-IDF值"""
tfidf = {}
for word, tf_val in tf.items():
tfidf[word] = tf_val * idf[word]
return tfidf
preprocessed_docs = [preprocess(doc) for doc in documents]
tf_list = [compute_tf(doc) for doc in preprocessed_docs]
idf = compute_idf(preprocessed_docs)
tfidf_list = [compute_tfidf(tf, idf) for tf in tf_list]
for i, tfidf in enumerate(tfidf_list):
print(f"\n文档 {i + 1}: {documents[i]}")
for word, score in sorted(tfidf.items(), key=lambda item: item[1], reverse=True):
print(f"词: {word}, TF-IDF值: {score:.4f}")
文档 1: The quick brown fox jumps over the lazy dog.
词: the, TF-IDF值: 0.2222
词: jumps, TF-IDF值: 0.1562
词: quick, TF-IDF值: 0.1111
词: brown, TF-IDF值: 0.1111
词: fox, TF-IDF值: 0.1111
词: over, TF-IDF值: 0.1111
词: lazy, TF-IDF值: 0.1111
词: dog, TF-IDF值: 0.0791
文档 2: Never jump over the lazy dog quickly.
词: never, TF-IDF值: 0.2008
词: jump, TF-IDF值: 0.2008
词: quickly, TF-IDF值: 0.2008
词: over, TF-IDF值: 0.1429
词: the, TF-IDF值: 0.1429
词: lazy, TF-IDF值: 0.1429
词: dog, TF-IDF值: 0.1018
文档 3: A quick brown dog outpaces a quick fox.
词: a, TF-IDF值: 0.3514
词: quick, TF-IDF值: 0.2500
词: outpaces, TF-IDF值: 0.1757
词: brown, TF-IDF值: 0.1250
词: fox, TF-IDF值: 0.1250
词: dog, TF-IDF值: 0.0890
LSTM(Long Short Term Memories)#
LSTM(Long Short Term Memories) 是一类特殊的循环神经网络结构,其隐藏层有着特殊的结构,给出了一种计算隐藏层状态的新方法。通过引入门控机制来解决 RNN 的梯度消失问题,从而能够学习到长距离依赖。
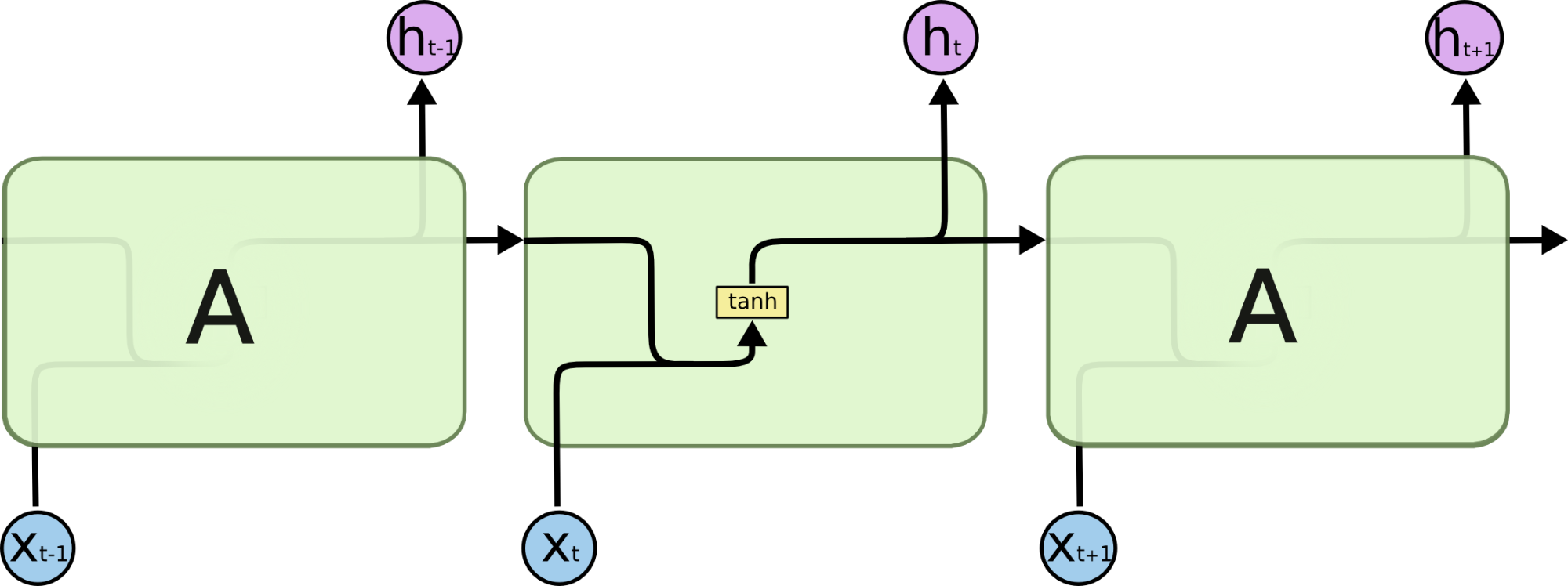
我们之前分析了 RNN 的简单结构,其结构大致如下图所示:
LSTM 的基本结构如下图所示:
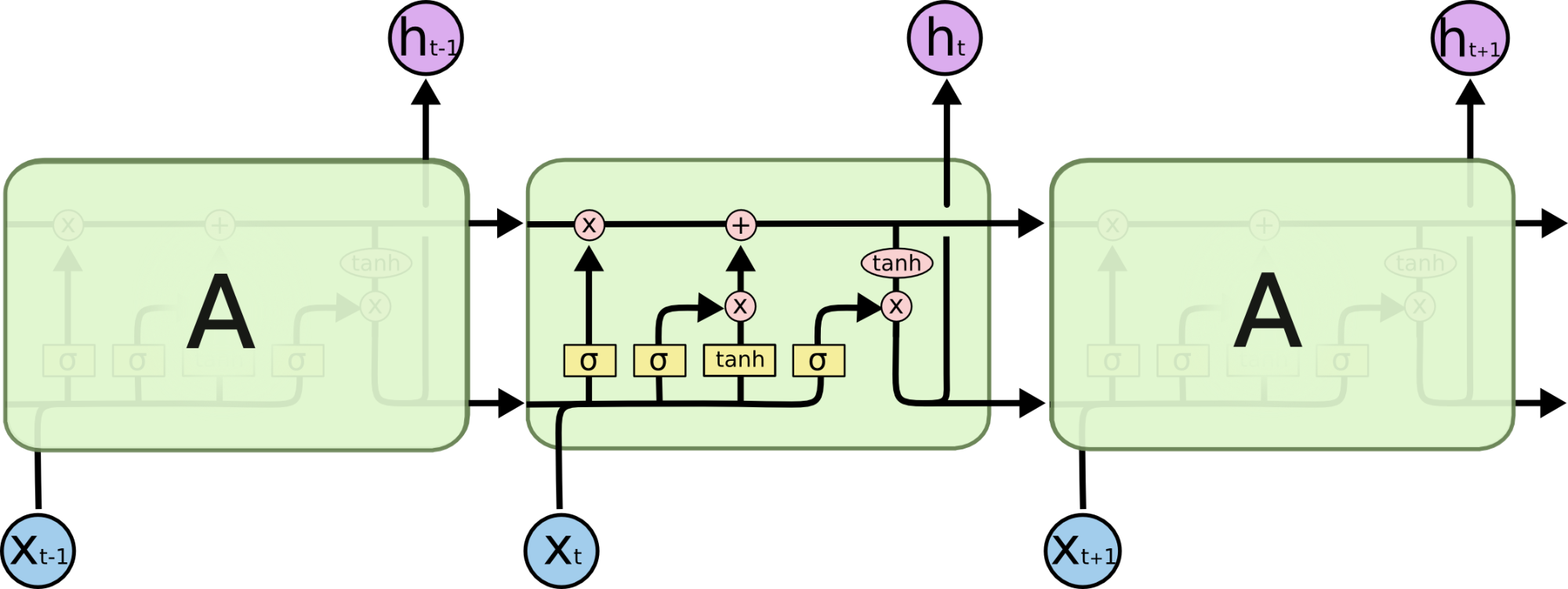
图中各个符号的定义:

各个符号的语义如下:
Neural NetWork Layer:该图表示一个神经网络层
Pointwise Operation:该图表示一种操作,如加号表示矩阵或向量的求和,乘号表示向量的乘法操作
Vector Tansfer:每一条线表示一个向量,从一个节点输出到另一个节点
Concatenate:该图表示两个向量的合并,即由两个向量合并为一个向量,如有 \(x_1\) 和 \(x_2\) 两向量合并后为 \([x_1,x_2]\) 向量
Copy:该图表示一个向量复制了两个向量,其中两个向量值相同
对 RNN 简单结构的解释#
为了接下来叙述的更清楚,先描述一下 RNN 的简单结构。
\(x_t\) 为 t 时刻的输入
\(h_t\) 首先为 t 时刻的隐藏层状态,同时也为 t + 1 时刻的输入,这里还是直接把 \(h_t\) 作为输出而不做进一步处理
那么我们可以理解成在时刻 t, \(h_{t-1}\) 和 \(x_t\) 作为一个激活函数为 tanh 的神经网络层的输入,通过计算得到了当前时刻的隐藏层状态 \(h_t\),这个 \(h_t\) 既是下一时刻的输入,也是当前时刻的输出。
LSTM结构拆分#
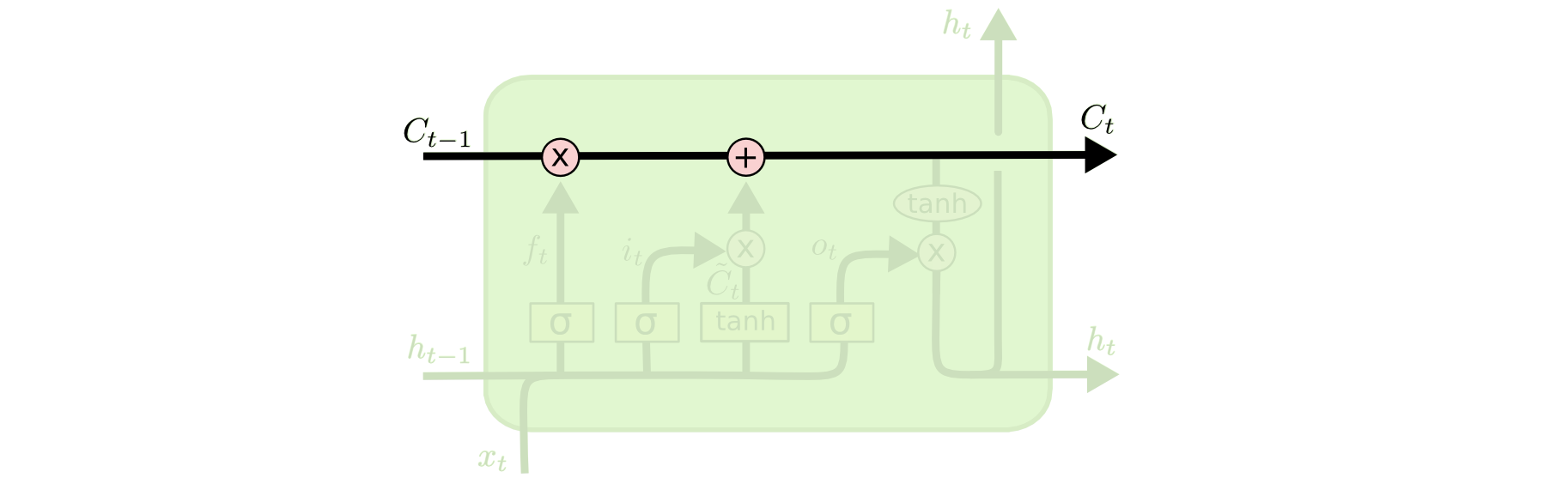
cell state#
LSTM最核心的部分是cell state。时刻 t 对应的 cell state 是 \(C_t\)。如下图中的直线所示 cell state 贯穿所有时刻。
LSTM 中的门#
在前向传播的过程中,通过门来控制 \(c_t\) 中信息的增减。LSTM中的门是通过一个激活函数为sigmoid的神经网络层来实现的,门的输出值在 \(0 \sim 1\) 之间。然后把门的取值向量和目标数据按位相乘就可以达到控制数据流通的效果。LSTM中共有三个门,分别为forget gate,input gate,output gate。这三个门的计算方法公式一样,都是根据 \(x_t\) 和 \(h_t−1\) 来计算, 区别在于这三个门对应的神经网络层的权重矩阵和偏置不同。
forget gate \(f_t\)#
首先考虑从上一时刻的 cell state 中丢弃什么信息,这由 forget gate 来控制。
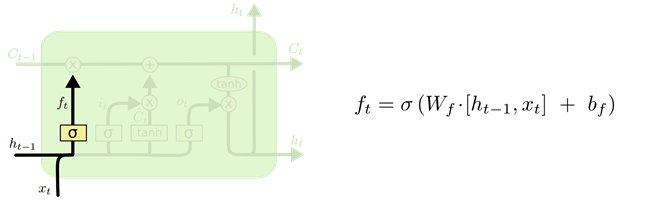
input gate \(i_t\)#
接着考虑当前时刻的新信息(candidate values, \(\widetilde{C}_t\))有哪些需要添加到 cell state。
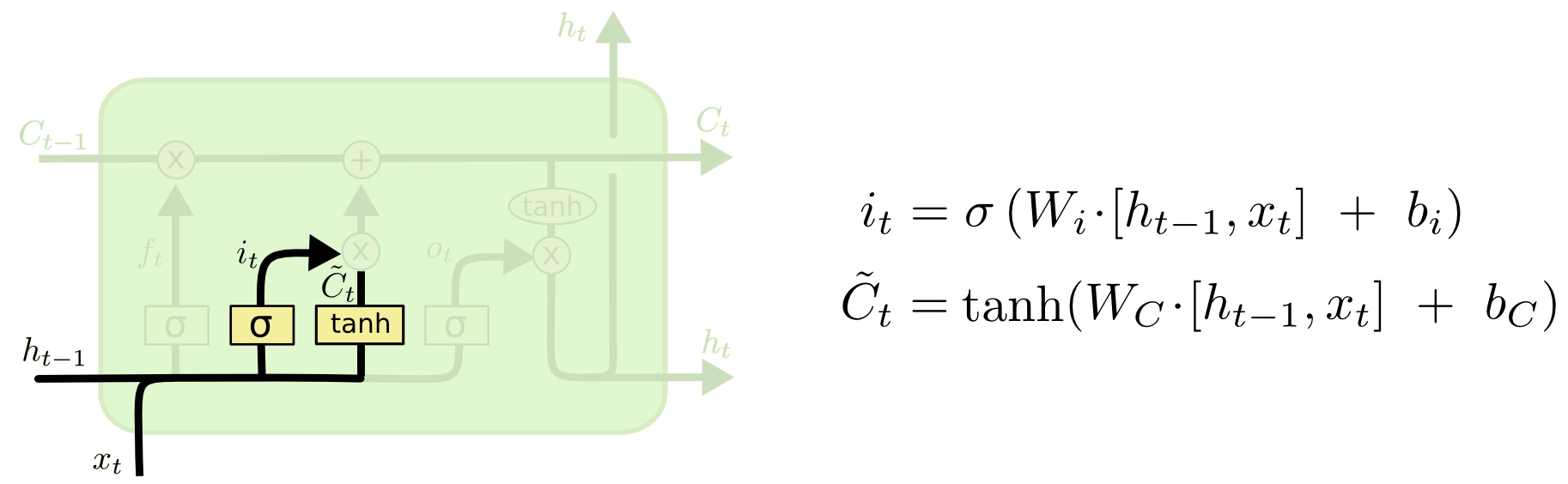
从公式中可以看出 candidates values(\(\widetilde{C}_t\)) 的计算方式就是简单的 RNN 结构中的隐藏层状态的计算方式。
计算出 \(i_t\) 和 \(\widetilde{C}_t\) 后,\(i_t \circ \widetilde{C}\),就是要添加到 cell state 中的新信息,其中 \(\circ\) 代表两个向量按位乘。
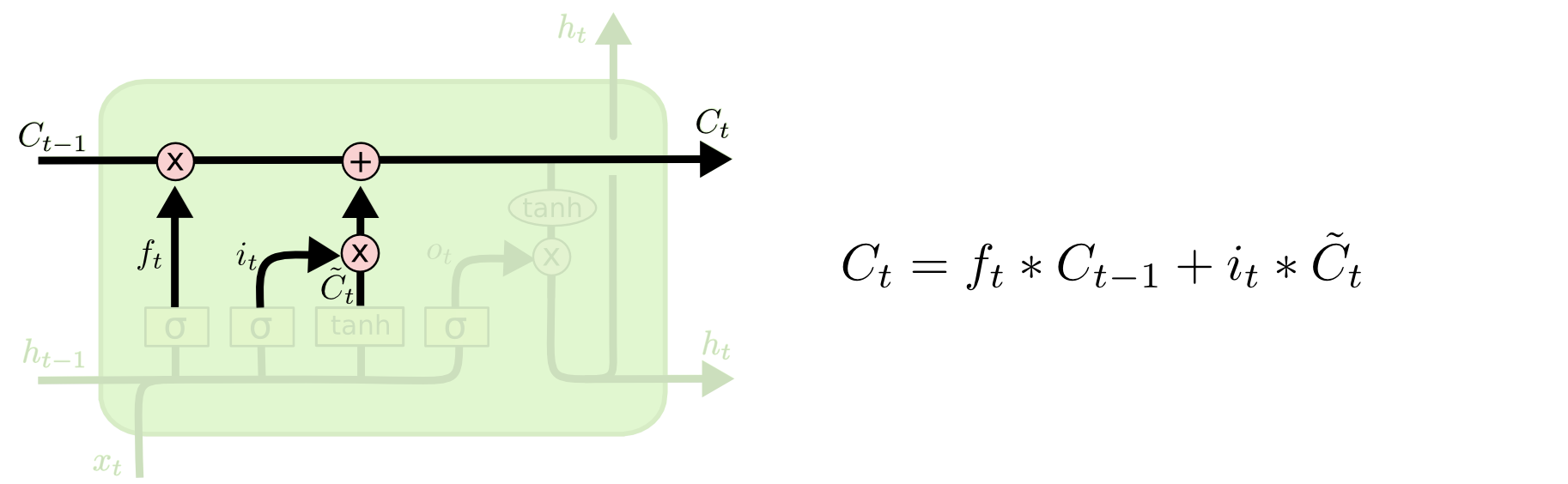
对以上两个门的总结#
通过 forget gate 和 input gate 这两个门的控制作用,我们已经丢弃了 cell state 中该丢弃的那部分信息,并且向 cell state 中添加了该添加的新信息。图中的 \(*\) 表示按位乘。
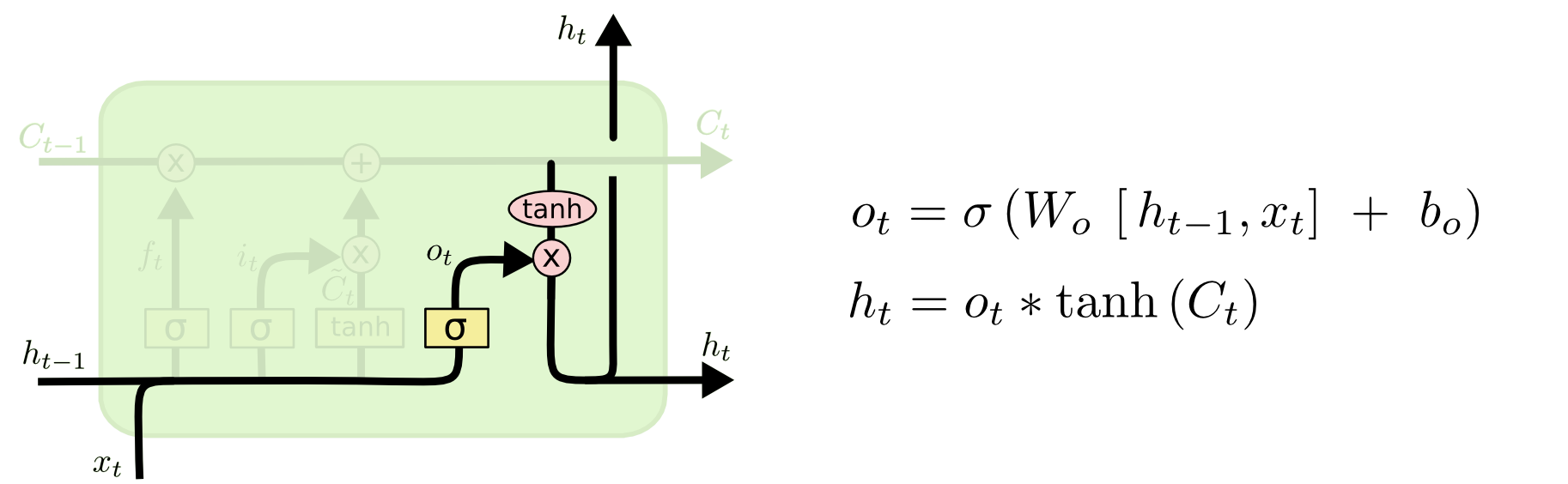
output gate \(o_t\)#
通过之前的计算,我们已经得到了当前时刻的 cell state(\(C_t\)),接下来我们考虑通过当前的 cell state 产生输出。通过 output gate 来控制当前时刻的 cell state 有哪些信息应该被输出。图中的 \(*\) 表示按位乘。
GRU#
梯度消失和长距离依赖问题#
RNN 中存在的梯度消失问题会导致难以学习到长距离依赖的问题。由于梯度消失问题的存在,越早的时刻对参数的修正起到的作用就越小,也就是说模型很难捕捉到长距离依赖关系。
GRU结构简介#
GRU 引入了 reset gate 和 update gate。其结构图如下,其中 \(*\) 表示按位乘。

reset gate \(r_t\) 和 update gate \(z_t\)#
reset gate 用来控制计算当前时刻的新信息时,保留多少之前的记忆。举个例子来说明一下,假设每个时刻输入的是一个词的话,那么如果 \(r_t\) 为 0,那么 \(\widetilde{h}_t\) 中就会只包含当前词的信息。
update gate 控制需要从前一时刻的隐藏层状态 \(h_{t-1}\) 中忘记多少信息,同时控制需要将多少当前时刻的新信息加入到隐藏层状态中。
reset gate 允许模型丢弃一些和未来无关的信息,如果reset gate接近0,那么之前的隐藏层信息就会丢弃。update gate 控制当前时刻的隐藏层输出 \(h_t\) 需要保留多少之前的隐藏层信息,若 \(z_t\) 接近于 1,相当于我们之前把之前的隐藏层信息拷贝到当前时刻,可以学习长距离依赖。 一般来说那些具有短距离依赖的单元 reset gate 比较活跃,具有长距离依赖的单元 update gate 比较活跃。
当前时刻的新信息#
接下来计算当前时刻的新信息(candidate values, \(\widetilde{h}_t\))。这跟 LSTM 中的 candidates values(\(\widetilde{C}_t\)) 是类似的。计算方式如下:
深度残差网络(ResNet)#
深度网络出现的退化问题#
深度残差网络是2015年提出的深度卷积网络,一经出世,便在ImageNet中斩获图像分类、检测、定位三项的冠军。从经验来看,网络的深度对模型的性能至关重要,当增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时理论上可以取得更好的结果,但是实验发现深度网络出现了退化问题(Degradation problem)。网络深度增加时,网络准确度出现饱和,甚至出现下降。如下图所示:
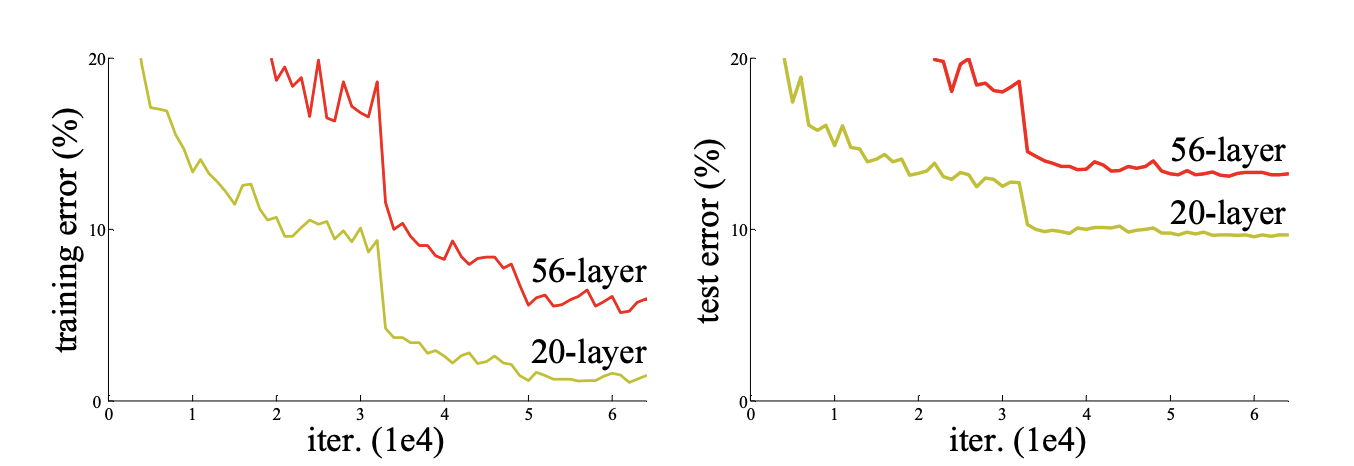
可以看出56层的网络比20层网络效果还要差。但是这不是过拟合的问题,因为56层网络的训练误差同样高。
只做恒等映射也不该出现退化问题#
深度网络的退化问题至少说明深度网络不容易训练。但是考虑以下事实:现在已经有了一个浅层神经网络,通过向上堆积新层来建立深层网络。一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即向上堆积的层仅仅是在做恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。但是问题可能是,网络并不是那么容易的就能学到恒等映射。随着网络层数不断加深,求解器不能找到解决途径。
ResNet#
ResNet 就是通过显式的修改网络结构,加入残差通路,让网络更容易的学习到恒等映射。通过改进,我们发现深层神经网络的性能不仅不比浅层神经网络差,还要高出不少。
Plaint net#
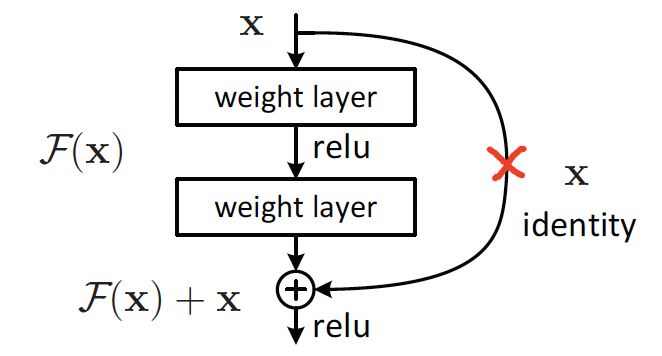
\(H(x)\)代表的是我们最终想要得到的一个映射。在 Plaint net 中,我们就是希望这两层网络能够直接拟合出\(H(x)\)。
Residual net#
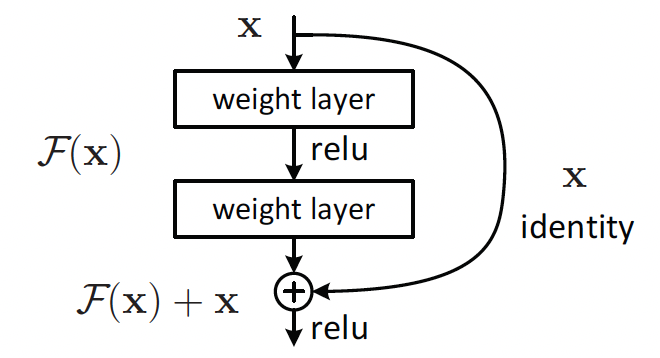
\(H(x)\)代表的仍然是我们最终想要得到的一个映射。与 Plain net 不同的是,这里通过一个捷径连接(shortcut connections)直接将\(x\)传到了后面与这两层网络拟合出的结果相加,\(H(x)\)是我们最终想要得到的一个映射,假设这两层网络拟合出来的映射为\(F(x)\),那么\(F(x)\)应该等于\(H(x)-x\)。
做这种变换的作用:如果 x 已经是最优的了,也就是说我们希望得到的映射 \(H(x)\) 恰好就是此时的输入 \(x\),也就是说要做恒等映射,这个时候只需要将权重值设定为 0。也就是让 \(F(x) = 0\) 就好了。我们发现这比直接学习 \(H(x) = x\) 要容易的多。
实际上残差网络相当于将学习目标改变了,学习的不再是一个完整的输出,而是目标值 \(H(x)\) 和 x 的差值,也就是这篇文章一直在讨论的残差 \(F(x)\)。并且有 \(F(x) = H(x) - x\)。
Residual Block#
残差网络(Residual Networks)由许多隔层相连的神经元子模块组成,我们称之为 Residual Block。
34层的ResNet结构图#

图中的虚线部分:
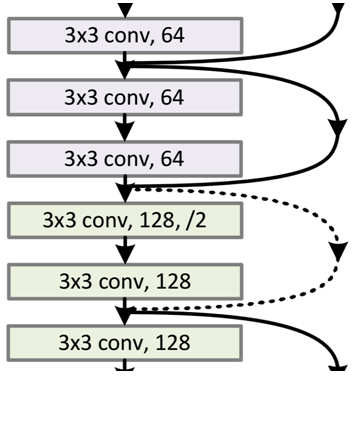
经过捷径连接(shortcut connections)后,\(H(x) = F(x) + x\),如果 \(F(x)\) 和 \(x\) 的通道数相同,则可直接相加。但是如果二者通道数不同,那么就不可以直接相加了。上图中的实线和虚线就是为了区分这两种情况:
实线:表示二者通道数相同,二者可以直接相加。
虚线:表示二者通道数不同,此时需要采用的计算方式为 \(H(x)=F(x) + Wx\),其中 \(W\) 代表卷积操作,用来调整 \(x\) 的通道数。
两种残差学习单元#
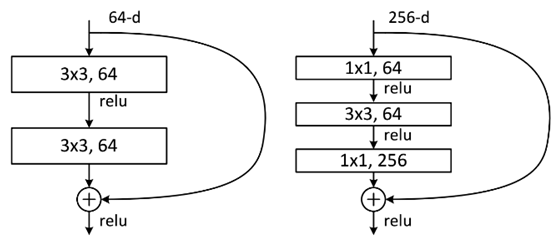
两种结构分别针对ResNet34(左图)和 ResNet50/101/152(右图)。右图的主要目的是减少参数数量。
为了做个详细的对比,我们这里假设左图的残差单元的输入不是 64-d 的,而是 256-d 的,那么左图应该为两个 \(3 \times 3, 256\) 的卷积。参数总数为:
说明:\(3 \times 3 \times 256\) 计算的是每个 filter 的参数数目,第 2 个 256 是说每层有 256 个filter,最后一个 2 是说一共有两层。
右图的输入同样为 256-d 的,首先通过一个 \(1 \times 1, 64\) 的卷积层将通道数降为 64。然后是一个 \(3 \times 3, 64\) 的卷积层。最后再通过一个 \(1 \times 1, 256\) 的卷积层通道数恢复为 256。参数总数为:
可见参数数量明显变少了。
通常来说对于常规的ResNet,可以用于34层或者更少的网络中(左图);对于更深的网络(如101层),则使用右图,其目的是减少计算和参数量。
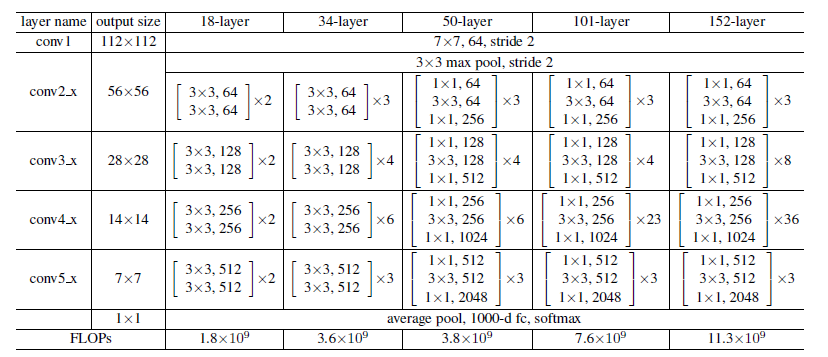
不同深度的ResNet#
CNN模型中常见的Pooling操作#
CNN是目前自然语言处理中和RNN并驾齐驱的两种最常见的深度学习模型。一般而言,输入的字或者词用Word Embedding的方式表达,这样本来一维的文本信息输入就转换成了二维的输入结构,假设输入X包含m个字符,而每个字符的Word Embedding的长度为d,那么输入就是m*d的二维向量。
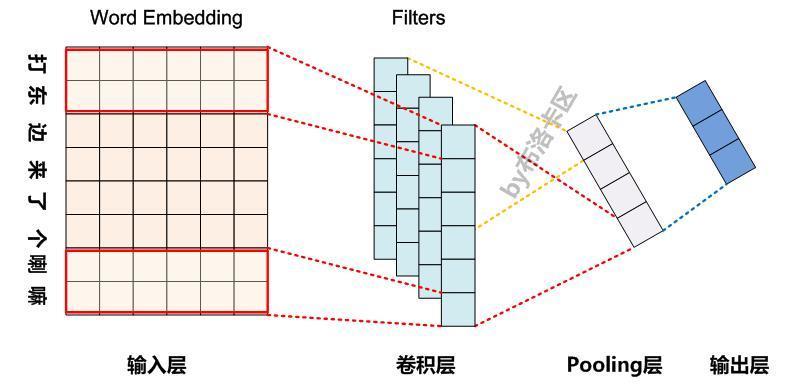
这里可以看出,因为NLP中的句子长度是不同的,所以CNN的输入矩阵大小是不确定的,这取决于m的大小是多少。卷积层本质上是个特征抽取层,可以设定超参数F来指定设立多少个特征抽取器(Filter),对于某个Filter来说,可以想象有一个k*d大小的移动窗口从输入矩阵的第一个字开始不断往后移动,其中k是Filter指定的窗口大小,d是Word Embedding长度。对于某个时刻的窗口,通过神经网络的非线性变换,将这个窗口内的输入值转换为某个特征值,随着窗口不断往后移动,这个Filter对应的特征值不断产生,形成这个Filter的特征向量。这就是卷积层抽取特征的过程。每个Filter都如此操作,形成了不同的特征抽取器。Pooling 层则对Filter的特征进行降维操作,形成最终的特征。一般在Pooling层之后为全连层。下面我们重点介绍NLP中CNN模型常见的Pooling操作方法。
Max Pooling Over Time#
Max Pooling Over Time是NLP中CNN模型中最常见的一种下采样操作。意思是对于某个Filter的卷积运算结果,只取其中得分最大的那个值作为Pooling层保留值,其它特征值全部抛弃,值最大代表只保留这些特征中最强的,而抛弃其它弱的此类特征。
这个操作可以保证特征的位置与旋转不变性,因为不论这个强特征在哪个位置出现,都会不考虑其出现位置而能把它提出来。对于图像处理来说这种位置与旋转不变性是很好的特性,但是对于NLP来说,这个特性其实并不一定是好事,因为在很多NLP的应用场合,特征的出现位置信息是很重要的,比如主语出现位置一般在句子头,宾语一般出现在句子尾等,这些位置信息其实有时候对于分类任务来说还是很重要的,但是Max Pooling 基本把这些信息抛掉了。
其次,Max Pooling能减少模型参数数量,防止模型过拟合。因为经过Pooling操作后,往往把2D或者1D的数组转换为单一数值。
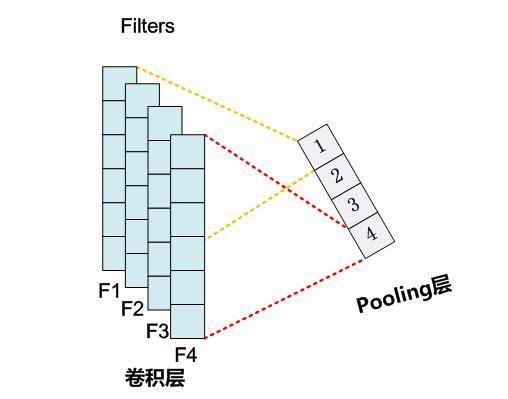
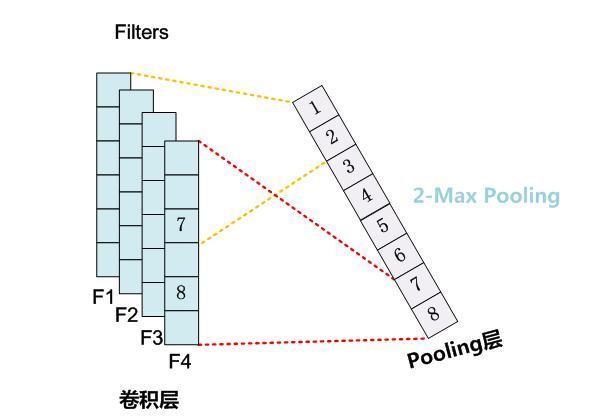
K-Max Pooling#
K-Max Pooling的意思是:原先的Max Pooling Over Time从Convolution层一系列特征值中只取最强的那个值,那么我们思路可以扩展一下,K-Max Pooling可以取所有特征值中得分在TopK的值,并保留这些特征值原始的先后顺序(图3是2-max Pooling的示意图),就是说通过多保留一些特征信息供后续阶段使用。
Chunk-Max Pooling#
Chunk-MaxPooling的思想是:把某个Filter对应的Convolution层的所有特征向量进行分段,切割成若干段后,在每个分段里面各自取得一个最大特征值,比如将某个Filter的特征向量切成3个Chunk,那么就在每个Chunk里面取一个最大值,于是获得3个特征值(如图4所示,不同颜色代表不同分段)。
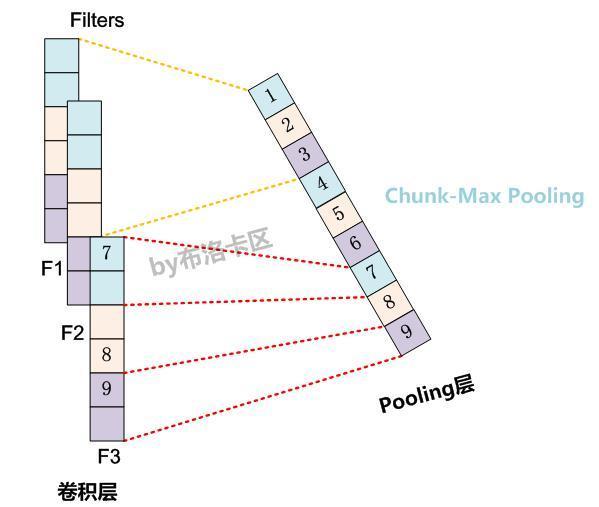
乍一看Chunk-Max Pooling思路类似于K-Max Pooling,因为它也是从Convolution层取出了K个特征值,但是两者的主要区别是:
K-Max Pooling是一种全局取TopK特征的操作方式
Chunk-Max Pooling则是先分段,在分段内包含特征数据里面取最大值,所以其实是一种局部TopK的特征抽取方式。
L-2 Norm#
L-2 Norm的作用是把embedding的长度都归一化为1,也就是说把它们都映射到一个长度为1的单位超球面上去。如果把它投影到单位超平面上,会增加训练稳定性和投影空间的线性可分性。增加线性可分性,意思也就是说你用简单算法也能得到比较好的效果。试想一下,一个单位超球面和一个不规则球面的向量空间,是不是前者更容易做到线性可分呢?这是目前图像领域里面得出的结论。

import numpy as np
def l2_normalize(vector):
norm = np.sqrt(np.sum(np.square(vector)))
if norm == 0:
return vector
return vector / norm
vector = np.array([3, 4])
normalized_vector = l2_normalize(vector)
print(f"向量 {vector} 的归一化结果是: {normalized_vector}")
向量 [3 4] 的归一化结果是: [0.6 0.8]
Batch Normalization#
BN假设所有样本独立同分布,并且使用所有样本的共享统计量进行normalization,\(E\)和\(Var\)分别是滑动均值和方差,\(\gamma\)和\(\beta\)是可以学习的scale和bias。多场景建模时,一般为每个场景添加独立的BN层,确保每个场景的数据都能被正确归一化。
Batch Normalization(批量归一化)的主要作用可以概括为以下几点:
稳定训练过程:训练神经网络时,数据在每一层都会经过一系列的变化,导致分布可能会变得不稳定。Batch Normalization通过将数据重新调整为标准正态分布,使训练过程更加平稳,减少训练的不确定性。
加速收敛:通过归一化处理,模型在训练过程中可以更快地达到最优状态。因为数据分布被稳定下来,模型可以用更高的学习率,从而减少训练的时间。
防止过拟合:Batch Normalization有助于防止模型过拟合。这种归一化方法有类似正则化的效果,减少对其他正则化方法(如Dropout)的依赖。
import numpy as np
class BatchNormalization:
def __init__(self, num_features, epsilon=1e-5, momentum=0.9):
self.epsilon = epsilon
self.momentum = momentum
self.gamma = np.ones(num_features) # 缩放参数γ
self.beta = np.zeros(num_features) # 平移参数β
self.running_mean = np.zeros(num_features)
self.running_var = np.ones(num_features)
self.training = True
def forward(self, X):
"""前向传播"""
if self.training:
# 计算当前批次的均值和方差
batch_mean = np.mean(X, axis=0)
batch_var = np.var(X, axis=0)
# 归一化
self.X_norm = (X - batch_mean) / np.sqrt(batch_var + self.epsilon)
# 平滑的更新运行中的均值和方差
# 平衡了当前批次和历史批次的统计量,防止单个批次对整体统计量的剧烈影响
self.running_mean = self.momentum * self.running_mean + (1 - self.momentum) * batch_mean
self.running_var = self.momentum * self.running_var + (1 - self.momentum) * batch_var
else:
# 使用运行中的均值和方差进行归一化
self.X_norm = (X - self.running_mean) / np.sqrt(self.running_var + self.epsilon)
# 应用缩放和偏移
out = self.gamma * self.X_norm + self.beta
return out
def set_training(self, training):
self.training = training
# 示例使用
np.random.seed(0)
X = np.random.randn(5, 3)
print(X)
bn = BatchNormalization(num_features=3)
# 训练模式下的前向传播
bn.set_training(True)
output_train = bn.forward(X)
print("训练模式下的归一化结果:\n", output_train)
# 测试模式下的前向传播
bn.set_training(False)
output_test = bn.forward(X)
print("测试模式下的归一化结果:\n", output_test)
[[ 1.76405235 0.40015721 0.97873798]
[ 2.2408932 1.86755799 -0.97727788]
[ 0.95008842 -0.15135721 -0.10321885]
[ 0.4105985 0.14404357 1.45427351]
[ 0.76103773 0.12167502 0.44386323]]
训练模式下的归一化结果:
[[ 0.79834163 -0.10633427 0.73103552]
[ 1.50498534 1.93980876 -1.57728392]
[-0.40789413 -0.87536574 -0.54579564]
[-1.20737923 -0.46345902 1.29222109]
[-0.68805361 -0.49464972 0.09982295]]
测试模式下的归一化结果:
[[ 1.6881266 0.36139964 0.95638524]
[ 2.1785064 1.8657813 -1.02779382]
[ 0.85105179 -0.20401383 -0.14114988]
[ 0.29624413 0.09883153 1.43876764]
[ 0.65663338 0.07589925 0.41380923]]
交叉熵损失函数#
定义#
交叉熵损失函数(Cross-Entropy Loss),在机器学习中特别是分类任务中非常常用。它衡量的是模型预测的概率分布与真实概率分布之间的差异。换句话说,交叉熵损失越小,表示模型的预测结果越接近真实标签。
对于一个分类任务,交叉熵损失函数的定义如下:
其中:
\( y \) 是真实标签的独热编码(one-hot encoding)。
\( \hat{y} \) 是模型预测的概率分布。
\( C \) 是类别的总数。
\( y_i \) 是真实标签中第 \(i\) 类的值(对于独热编码,只有一个位置是1,其余为0)。
\( \hat{y}_i \) 是模型预测的第 \(i\) 类的概率。
通俗解释#
可以用一个简单的例子来解释交叉熵损失函数。假设我们在做一个猫和狗的二分类任务:
如果图片是猫,真实标签 \( y \) 可以表示为 [1, 0]。
如果图片是狗,真实标签 \( y \) 可以表示为 [0, 1]。
模型输出的是对这两个类别的预测概率,例如:
模型预测图片是猫的概率为 0.9,是狗的概率为 0.1,预测结果为 [0.9, 0.1]。
交叉熵损失函数计算真实标签和预测概率之间的差异,对于标签 [1, 0] 和预测 [0.9, 0.1],交叉熵损失为:
损失值越小,表示预测结果越接近真实标签。
import numpy as np
def cross_entropy_loss(y_true, y_pred):
"""
计算交叉熵损失
参数:
y_true -- 真实标签,形状为 (batch_size, num_classes)
y_pred -- 预测概率,形状为 (batch_size, num_classes)
返回:
loss -- 交叉熵损失值
"""
epsilon = 1e-9 # 避免log(0)的情况
y_pred = np.clip(y_pred, epsilon, 1. - epsilon)
cross_entropy = -np.sum(y_true * np.log(y_pred), axis=1)
return np.mean(cross_entropy)
# 示例用法
y_true = np.array([[1, 0], [0, 1], [1, 0]]) # 真实标签 (one-hot encoded)
y_pred = np.array([[0.9, 0.1], [0.4, 0.6], [0.2, 0.8]]) # 预测概率
loss = cross_entropy_loss(y_true, y_pred)
print("交叉熵损失:", loss)
交叉熵损失: 0.7418746839526391
Focal Loss#
简介#
Focal Loss 是一种改进的交叉熵损失函数,旨在解决样本类别不均衡的问题。它通过降低对易分类样本的损失权重,增强对难分类样本的关注,从而改善模型在不平衡数据集上的表现。Focal Loss 的公式如下:
其中公式中各个部分的含义如下:
\(p_t\)是模型对正确类别的预测概率。
\(\alpha_t\)是平衡因子,用于平衡正负样本的影响(可选)。
\(\gamma\)是调整因子,用于控制易分类样本的权重降低程度。
Focal Loss是如何做到降低对易分类样本的损失权重,增强对难分类样本的关注的?
对于易分类样本,\(p_{t}\)接近 1(模型对其分类的信心高),那么\(1-p_{t}\)接近 0,因此 \((1- p_{t})^\gamma\) 也接近 0,这个调节项会显著降低易分类样本的损失值。
对于难分类样本,\(p_{t}\)接近 0(模型对其分类的信心低),那么\(1-p_{t}\)接近 1,因此 \((1- p_{t})^\gamma\) 仍接近 1,这个调节项对难分类样本的影响很小。
推导过程(可跳过该章节)#
交叉熵损失函数(其中 \(\hat p\)为预测概率大小):
对于二分类问题,先简化公式:
对于所有样本来说,假设N为总样本量,m为正样本量,n为负样本量,当m << n时,负样本就会在损失函数里占据主导地位,由于损失函数的倾斜,模型训练过程中会倾向于样本多的类别,造成模型对少样本类别的性能较差。
focal loss具体形式:
如果我做以下定义:
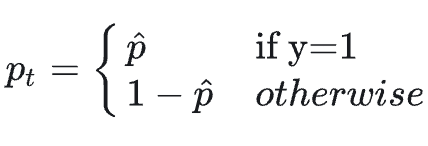
focal loss表达式:
交叉熵表达式:
import numpy as np
def focal_loss(y_true, y_pred, alpha=0.25, gamma=2.0):
"""
计算Focal Loss
参数:
y_true -- 真实标签,形状为 (batch_size, num_classes)
y_pred -- 预测概率,形状为 (batch_size, num_classes)
alpha -- 平衡因子,默认值为 0.25
gamma -- 调整因子,默认值为 2.0
返回:
loss -- Focal Loss 值
"""
epsilon = 1e-9
y_pred = np.clip(y_pred, epsilon, 1. - epsilon) # 避免log(0)情况
cross_entropy = -y_true * np.log(y_pred)
loss = alpha * (1 - y_pred) ** gamma * cross_entropy
return np.mean(np.sum(loss, axis=1))
# 示例用法
y_true = np.array([[1, 0], [0, 1], [1, 0]]) # 真实标签
y_pred = np.array([[0.9, 0.1], [0.4, 0.6], [0.2, 0.8]]) # 预测概率
loss = focal_loss(y_true, y_pred)
print("Focal Loss:", loss)
Focal Loss: 0.09273549740974675
OneEpoch现象#
推荐阅读⭐️⭐️⭐️⭐️⭐️
paper: Multi-Epoch Learning for Deep Click-Through Rate Prediction Models
模型AUC在第一个epoch内逐步提升,但是从第二个epoch开始,AUC效果突然剧烈下降。产生OneEpoch现象的原因:
embedding + mlp的结构
能使模型快速收敛的优化器算法(eg: 学习率较大的adam优化器)
高维稀疏特征(eg: item_id等细粒度特征)
其他不相关因素:模型参数量、激活函数、batch size、weight decay、dropout
多Epoch探究:每一轮训练都重置embedding,更新embedding和mlp,避免embedding层过拟合,并让mlp层学的更充分。

温度系数#
温度系数常应用在召回/粗排等双塔模型结构中,点乘之后除以一个固定的系数(温度系数),τ是温度系数,一般来说加一个温度系数是有效的。原因是温度系数可以让模型更聚焦于hard负例,且τ越小越聚焦,也就不用花费大力气挖掘hard负例。
Hard样本#
Hard样本是指那些模型难以正确分类的样本。这些样本可能由于以下原因难以分类:
数据不平衡
特征不明显
噪声或异常数据
温度系数与Hard样本的具体关系#
低温度系数(<1):
效果: 使得模型的输出概率分布更尖锐(更接近于0或1)。
对hard样本的影响:
模型对hard样本的预测可能会更不确定,因为这些样本本身难以分类,输出概率会更加极端(高概率的类别与低概率的类别差距更大)。
模型可能会更加确信自己的错误预测,从而难以在后续训练中纠正。
高温度系数(>1):
效果: 使得模型的输出概率分布更平滑(更接近于均匀分布)。
对hard样本的影响:
模型对hard样本的预测会变得更不确定,输出的概率更接近于均匀分布(各类别的概率差距缩小)。
这种不确定性可以提示模型在训练过程中对这些hard样本进行更多关注,从而帮助模型更好地学习和纠正错误。
温度系数对预估值的影响#
假设一个分类模型在一个三类问题中输出如下分数(未归一化):
易分类样本:[10, 2, 1]
难分类样本:[3, 3, 2.5]
无温度调整(温度=1):
易分类样本的Softmax概率:[0.999, 0.001, 0.000]
难分类样本的Softmax概率:[0.4, 0.4, 0.2]
降低温度(温度=0.5):
易分类样本的Softmax概率:[1.0, 0.0, 0.0]
难分类样本的Softmax概率:[0.42, 0.42, 0.16](更尖锐)
升高温度(温度=2):
易分类样本的Softmax概率:[0.88, 0.06, 0.06]
难分类样本的Softmax概率:[0.34, 0.34, 0.32](更平滑)
温度系数对loss的影响#
在机器学习和深度学习中,损失函数(loss)是用于衡量模型预测与真实标签之间差异的指标。对于分类任务,常用的损失函数是交叉熵损失。温度系数的调整会影响模型的预测概率分布,从而对损失值产生影响。
假设模型的输出分数为:[3.0, 1.0, 0.1],且真实标签对应的类别为第一个类别(索引0)。
无温度调整(温度=1):
使用Softmax函数计算概率:
\( P_0 = \frac{e^{3.0}}{e^{3.0} + e^{1.0} + e^{0.1}} \approx 0.84 \)
\( P_1 = \frac{e^{1.0}}{e^{3.0} + e^{1.0} + e^{0.1}} \approx 0.11 \)
\( P_2 = \frac{e^{0.1}}{e^{3.0} + e^{1.0} + e^{0.1}} \approx 0.05 \)
降低温度(温度=0.5):
调整后的Softmax计算:
调整后的分数:[6.0, 2.0, 0.2](分数被拉开)
\( P_0 = \frac{e^{6.0}}{e^{6.0} + e^{2.0} + e^{0.2}} \approx 0.97 \)
\( P_1 = \frac{e^{2.0}}{e^{6.0} + e^{2.0} + e^{0.2}} \approx 0.03 \)
\( P_2 = \frac{e^{0.2}}{e^{6.0} + e^{2.0} + e^{0.2}} \approx 0.0007 \)
交叉熵损失的公式为: $\( L = - \sum_{i} y_i \log(p_i) \)\( 其中 \)y_i\( 是真实标签的one-hot编码,\)p_i$ 是模型预测的概率。
无温度调整时的损失:
\( y = [1, 0, 0] \)
损失:\( L = - \log(0.84) \approx 0.17 \)
降低温度后的损失:
\( y = [1, 0, 0] \)
损失:\( L = - \log(0.97) \approx 0.03 \)
当温度系数降低时,模型的输出概率分布变得更尖锐,预估值被拉开。如果模型预测正确,类别的概率接近1,交叉熵损失将会变小。相反,如果模型预测错误,高温度系数导致的平滑概率分布可能会导致较高的损失。因此,预估值被拉开不一定会导致损失变大。具体影响取决于模型预测的正确性。对于正确的预测,预估值被拉开会降低损失;对于错误的预测,预估值被拉开会增加损失。
softmax函数#
一个非常漂亮且实用的函数。Softmax 函数公式如下,它可以将数值处理成概率。
构建神经网络时,碰到多分类问题,我们可以将全连接层的输出通过函数转为概率。例如,我们在鸢尾花分类问题中,如果最后全连接层给出了 3 个输出,分别是 -1.3,2.6,-0.9。通过 Softmax 函数处理之后,就可以得到 0.02,0.95,0.03 的概率值。也就是说有 95% 的概率属于 Versicolor 类别的鸢尾花。

import numpy as np
def softmax(x):
# Softmax 实现
exp_x = np.exp(x)
return exp_x / np.sum(exp_x)
np.round(softmax([-1.3, 2.6, -0.9]), 2)
array([0.02, 0.95, 0.03])
蒸馏学习#
推荐阅读⭐️⭐️⭐️⭐️⭐️
《Dislillation the Knowledge in a Neural Network》
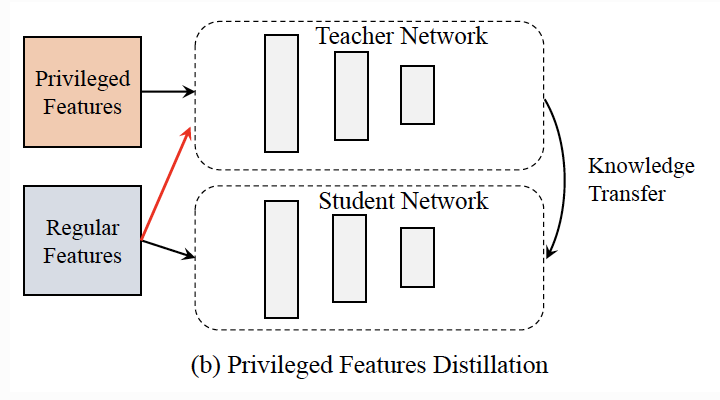
MD(Model Distillation):教师模型和学生模型处理相同的输入特征,其中教师模型会比学生模型更为复杂。
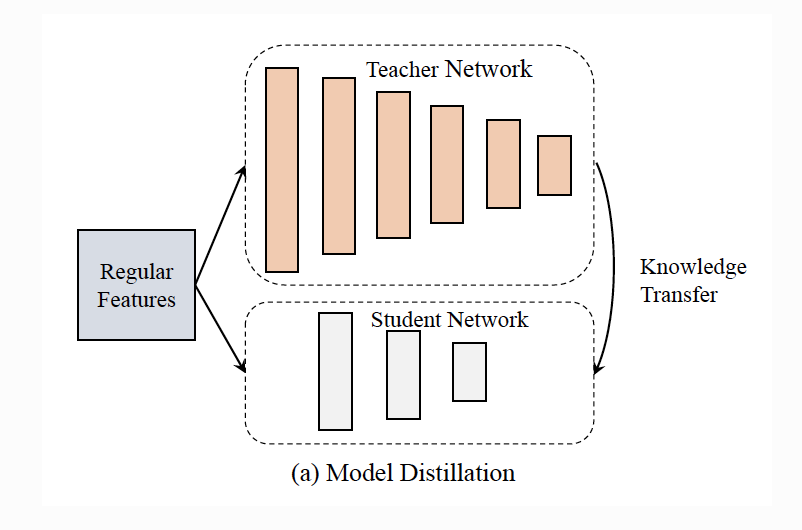
PFD(Privileged Features Distillation):教师模型和学生模型使用相同网络结构,而处理不同的输入特征,学生模型处理常规特征(Regular Features),教师模型处理优势特征(Privileged Features)和常规特征(Regular Features)。