Table of Contents
推荐系统06-特征交叉#
DCN#
推荐阅读⭐️⭐️⭐️⭐️⭐️
Deep & Cross Network for Ad Click Predictions
DCN 提出了cross network的网络结构 ,能够高效的进行高阶特征交叉。DCN 无论在模型表现和模型大小方面都具有显著优势。
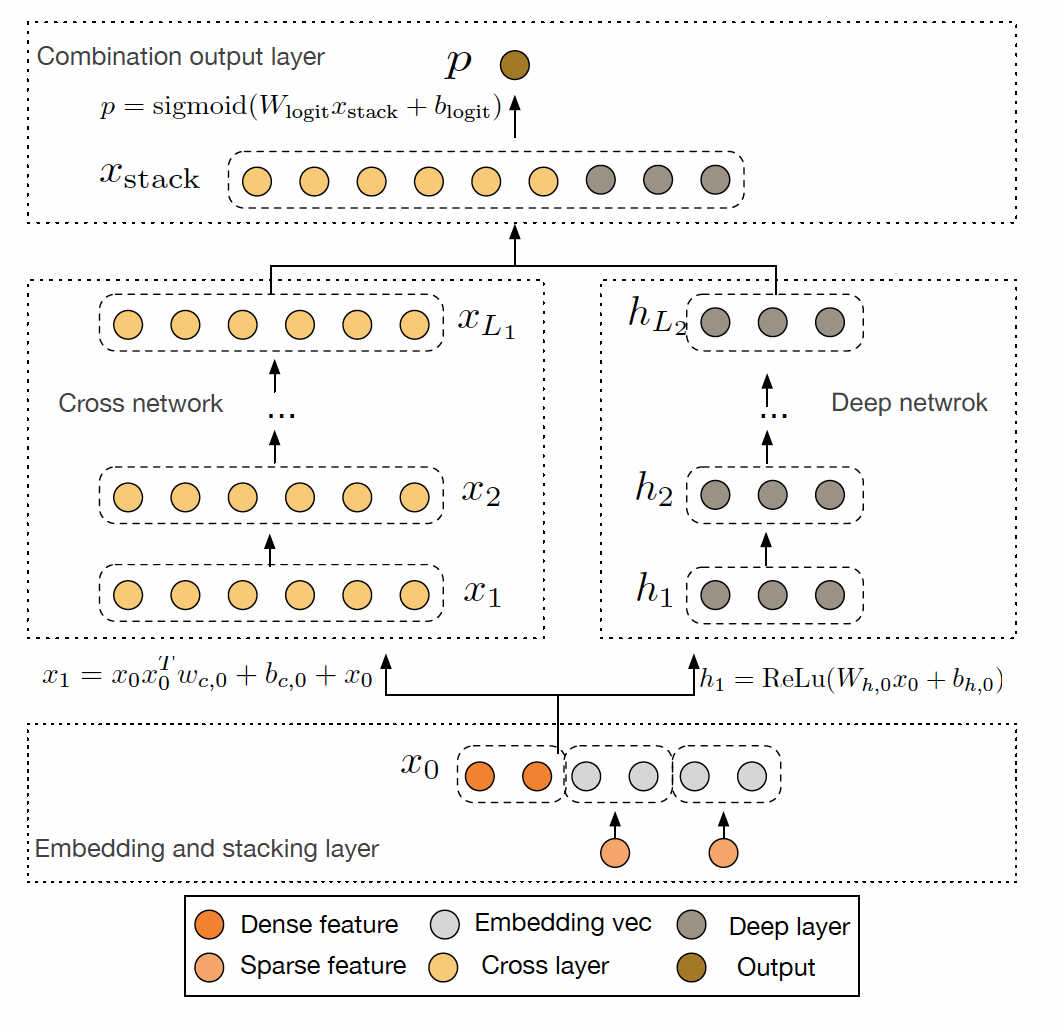
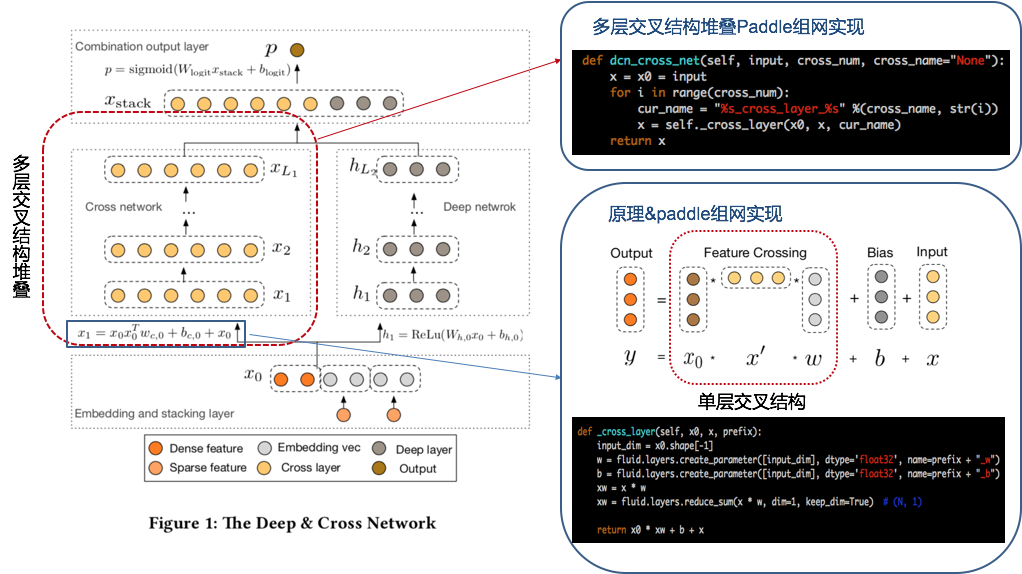
DCN共分为4个部分:
Embedding and stacking layer:网络输入层,其中特征包含稀疏特征和稠密特征,这一层是模型的输入层。我们知道输入的特征分为稀疏特征(Sparse feature)和稠密特征(Dense feature),其中稀疏特征经过embedding层转为稠密向量(embedding vec),最终把所有embedding vec以及稠密特征concat到一起得到模型最终输入(\(x_0\))。
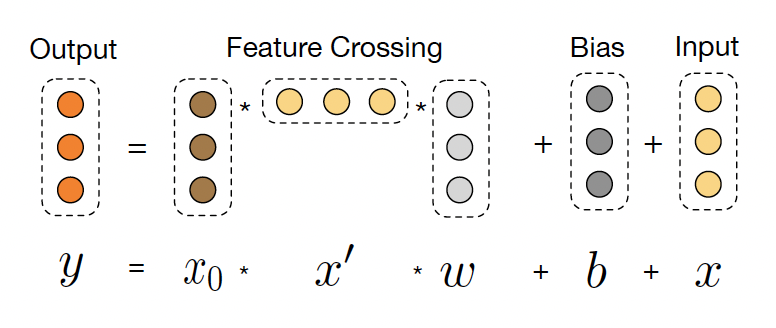
Cross network:Corss Network 部分网络层叠加的方式如下为:\(x_{l+1} = x_{0} x_{l}^{T} w_{c,l} + b_{c,l} + x_{l}\),通过控制堆叠层数,可以高效的进行高阶特征交叉,假设需要叠加3层:
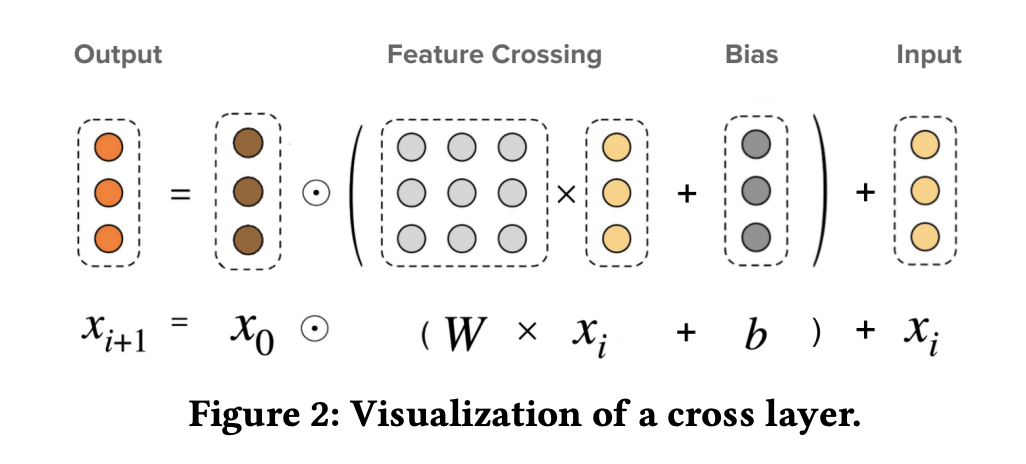
一层交叉的可视化如下图所示:
Deep network:常见的DNN层,表达式为:\(h_{l+1} = f(W_lh_l + b_l)\)
Combination output layer:将 Cross network 和 Deep network 的输出 concat 到一起,经过一个 logits 层,对于一个二分类问题:
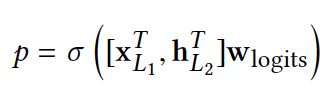
其中:
损失函数(logloss + L2正则):
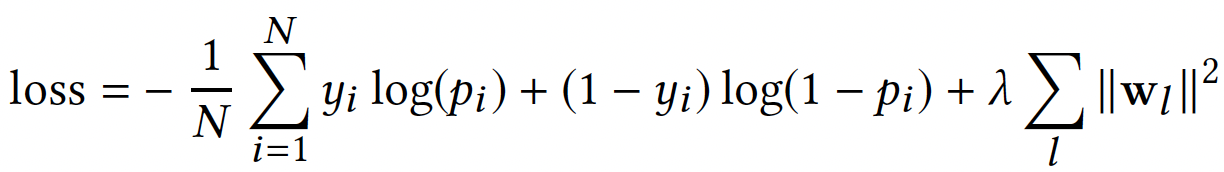
整体网络结构如下:
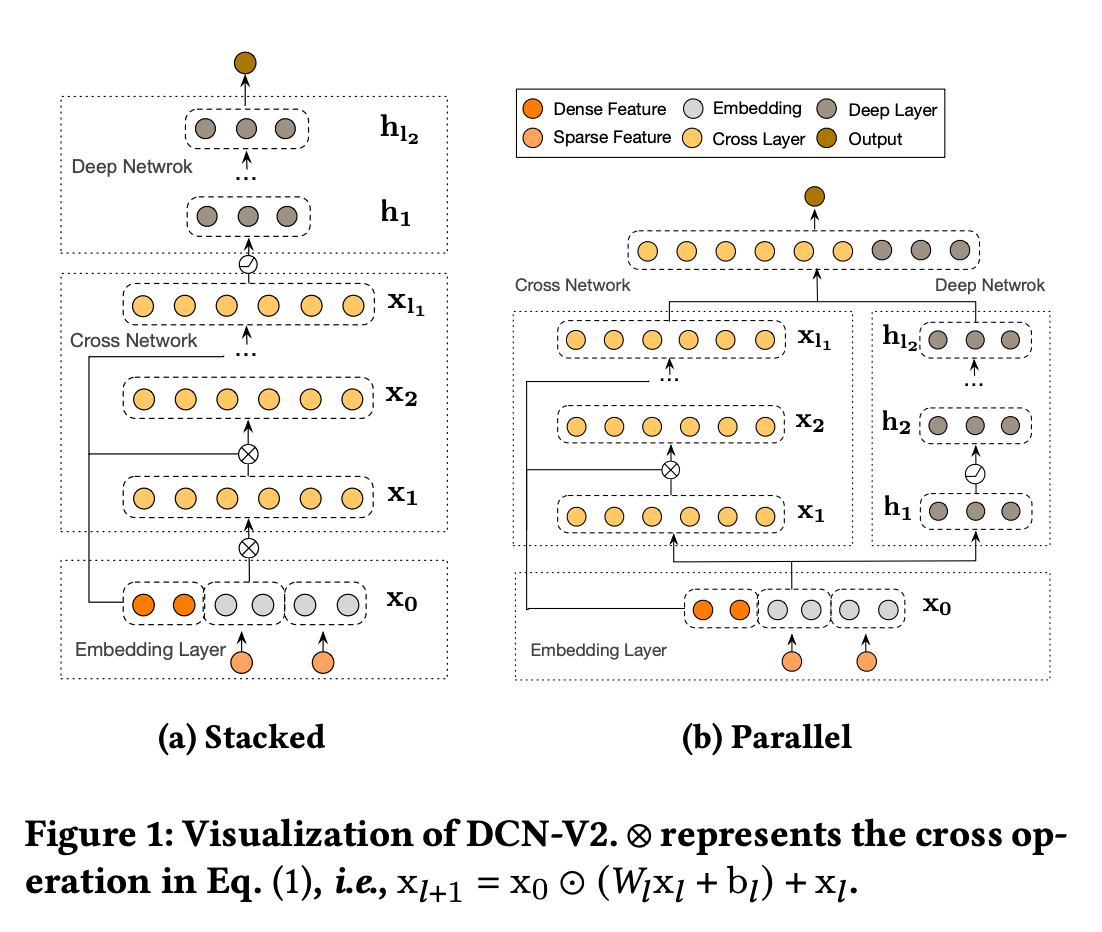
DCN v2#
DCN的的问题在于交叉网络对于特征交互信息的表达能力不够,而DCN-v2在这里通过对DCN中的交叉网络的改造,以及对Cross网络和Deep网络的结合方式,包括并行连接方式和stacking的连接方式,使得模型的效果性能明显提升。
DCN-v2模型相比于DCN模型的优势在于:
对于交互特征的表达能力更强;
DCN-v2模型的结构比较简单,比较适合作为复杂模型中的一个模型算子来引入使用;
在特征交互信息的学习上非常高效,尤其在与低秩矩阵架构结合使用时更加高效。
在Cross网络中,第l+1层的计算公式为:\(x_{l+1} = x_0 \odot (W_l x_l + b_l) + x_l\),其中\(x_0\)是一个d维向量,\(W_l\)是一个\(d\)维矩阵,\(b_l\)是一个d维向量,它们分别是cross网络要学习的权重矩阵和偏差向量。
Cost-Effective Mixture of Low-Rank DCN:在实际工业界中,模型复杂度容易被计算资源和响应延迟这些条件所限制,一般都会在计算开销和模型精度之间做trade-off。在数学上,低秩方法是用来减小矩阵计算开销的常用方法,它是将一个稠密矩阵分解成两个高瘦的矩阵,例如将 d✖️d 维的稠密矩阵M分解成两个 d✖️r 的高瘦矩阵U和V,当 r << d 时,计算开销将被大大降低,当原来稠密矩阵的奇异值差别较大或快速衰减时,对于计算开销的优化将更加明显。在矩阵M上使用低秩架构的计算公式为:\(x_{l+1} = x_0 \odot (U_l(V_l^T x_l) + b_l) + x_l\),对于这个计算公式有两种解释:
我们可以在子空间中学习特征交互;
将输入特征 x 先映射到低维空间 \(R^r\),再映射回高维空间 \(R^d\) 中。这两种解释进一步激发了对DCN-v2模型的改进。
从子空间的角度可以联想到MoE(Mixture-of-Experts),在原始Cross网络中,只使用了一个expert,现在可以将其替换成多个experts,每个expert负责学习不同的子空间信息:
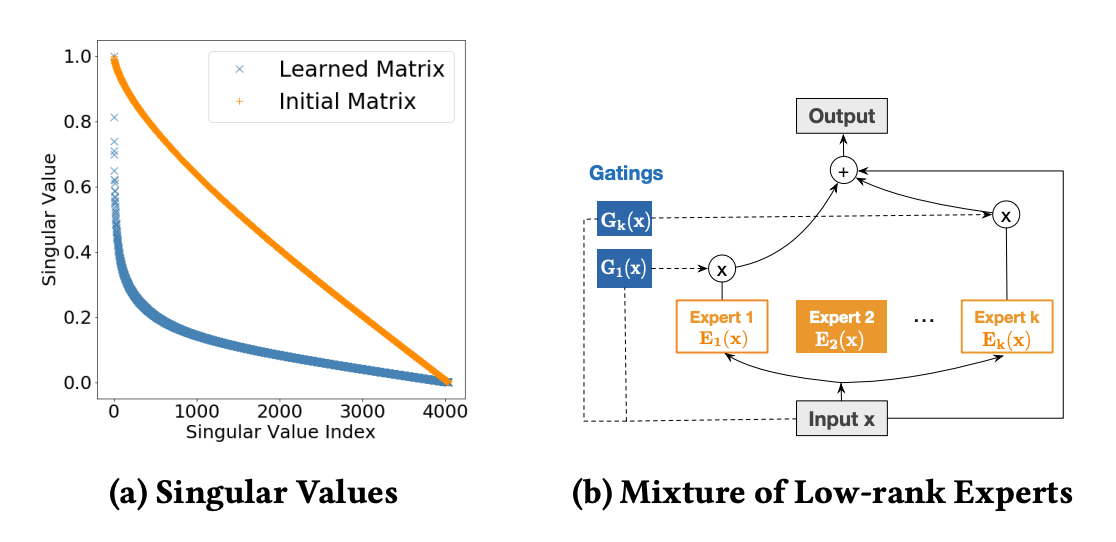
因此对应的低秩架构下的Cross层计算公式为:
映射空间具有低维的特性,这里除了从维度 d’ 到 d 的线性映射(d’ << d),额外引入了非线性变换来提取更有效的特征信息,因此映射变换后的Cross层的计算公式为:
FM#
推荐阅读⭐️⭐️⭐️⭐️⭐️
从一般线性模型到FM模型#
在一般的线性模型中,各个特征相互独立,不考虑特征与特征之间的相互关系。 一般的线性模型为:
但实际上,大量的特征之间是有关联的,为了表述特征间的相关性,可以采用多项式模型。为了简单起见,我们讨论二阶多项式模型:
该多项式模型与线性模型相比,对每个二阶交叉特征都配备了一个超参数,特征组合部分的参数有\(\frac{n(n-1)}{2}\)个,泛化能力比较弱,特别是在大规模稀疏特征场景下,问题尤为突出。
FM模型可以解决上述问题,FM模型表达式如下:
通过以上表达式可以看出:
FM存在一阶项,实际就是LR,能够记忆高频、常见模式。
FM基于embedding的二阶交叉,适用于大规模稀疏特征场景,泛化能力强,即使在训练数据里两个特征并未同时在训练样本里出现过,\(x_i\)和\(x_j\)一起出现的次数为0,也可以通过内积算出这个新特征组合的权重。
计算性能优化#
通过数学公式改写,把表面\(O(kn^2)\)的复杂度降低到\(O(kn)\),其中n是特征数量,k是特征的 embedding size。
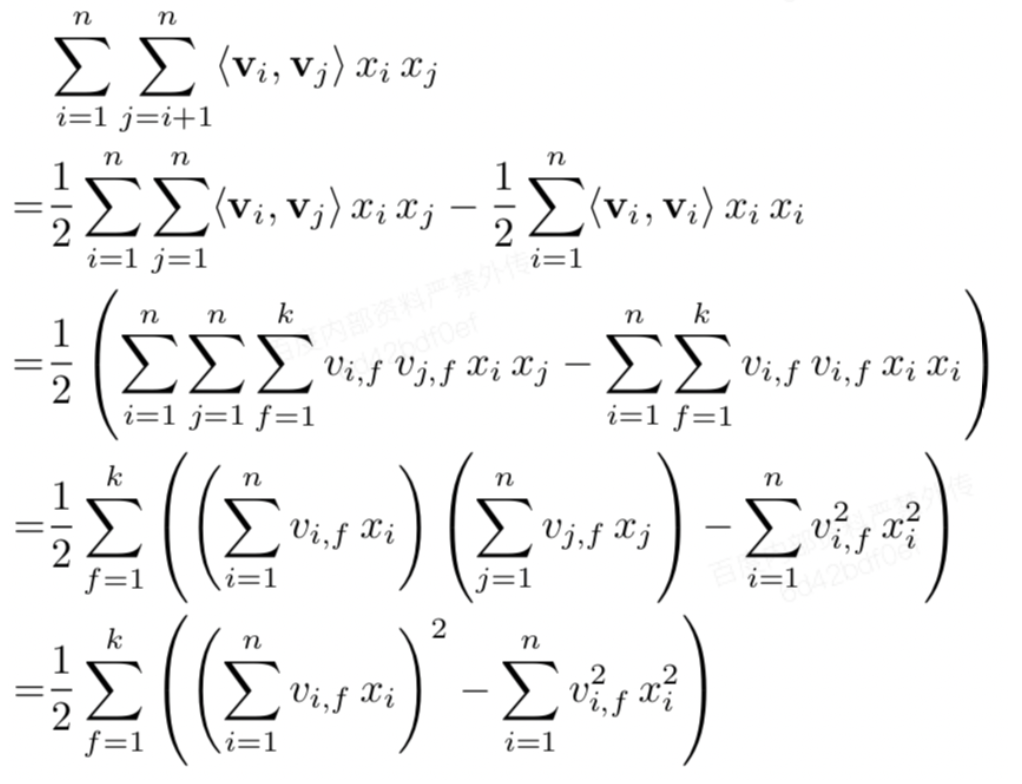
FM模型特点总结#
综上,FM模型有以下几个特点:
可以在非常稀疏的数据中进行合理的参数估计
FM模型的时间复杂度是线性的
FM是一个通用模型,它可以用于任何特征为实值的情况