Table of Contents
- 1 序列特征优化方案
- 1.1 Base Model
- 1.2 DIN(Deep Interest Network)
- 1.3 DIEN(target attention + GRU)
- 1.4 DSIN
- 1.5 京东 | Deep Multifaceted Transformers for Multi-objective Ranking in Large-Scale E-commerce Recommender
- 1.6 阿里|Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction
- 1.7 阿里BST(Transformer处理序列特征)
- 1.8 阿里DMR(attention)
- 1.9 阿里MIND
推荐系统04-序列特征优化方案#
Base Model#
传统基于用户行为序列描述用户兴趣的方法是把序列中各个item的embedding通过pooling的方式转化成一个固定维的embedding。如下图所示,其中红色节点表示商品ID,蓝色节点表示店铺iD,粉色节点表示类目ID,白色节点表示用户特征和上下文特征,Goods 1 ~ Goods N 用来描述用户的历史行为,候选广告(Candidate Ad)本身也是商品。
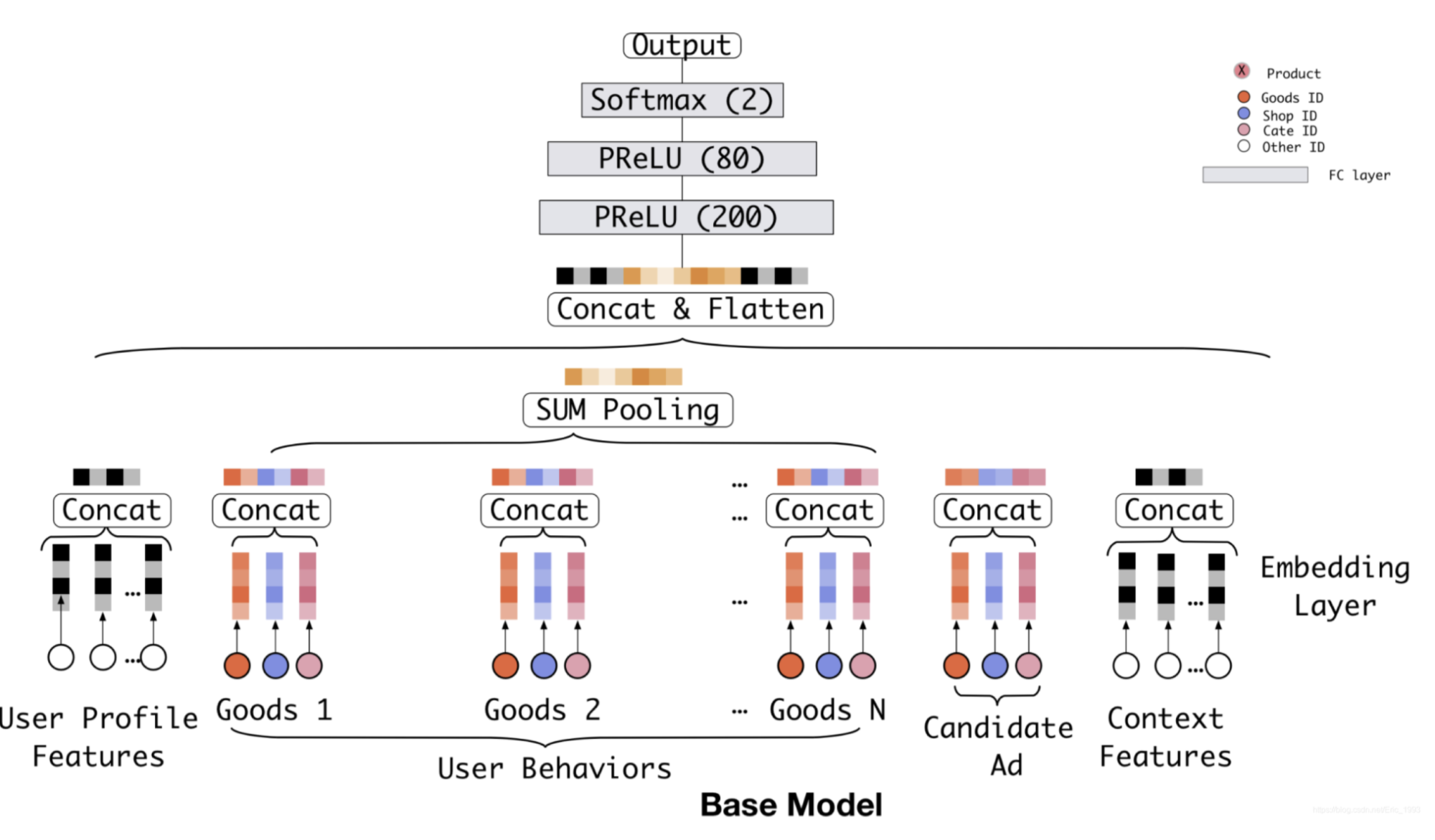
网络结构具有的缺点是经过pooling以后的向量与候选广告无关,对于一个用户来说是固定不变的。对于不同的候选广告,与之对应的用户兴趣分布也应该不通。因为只有用户部分的兴趣会影响当前行为(对候选广告点击或不点击)。
DIN(Deep Interest Network)#
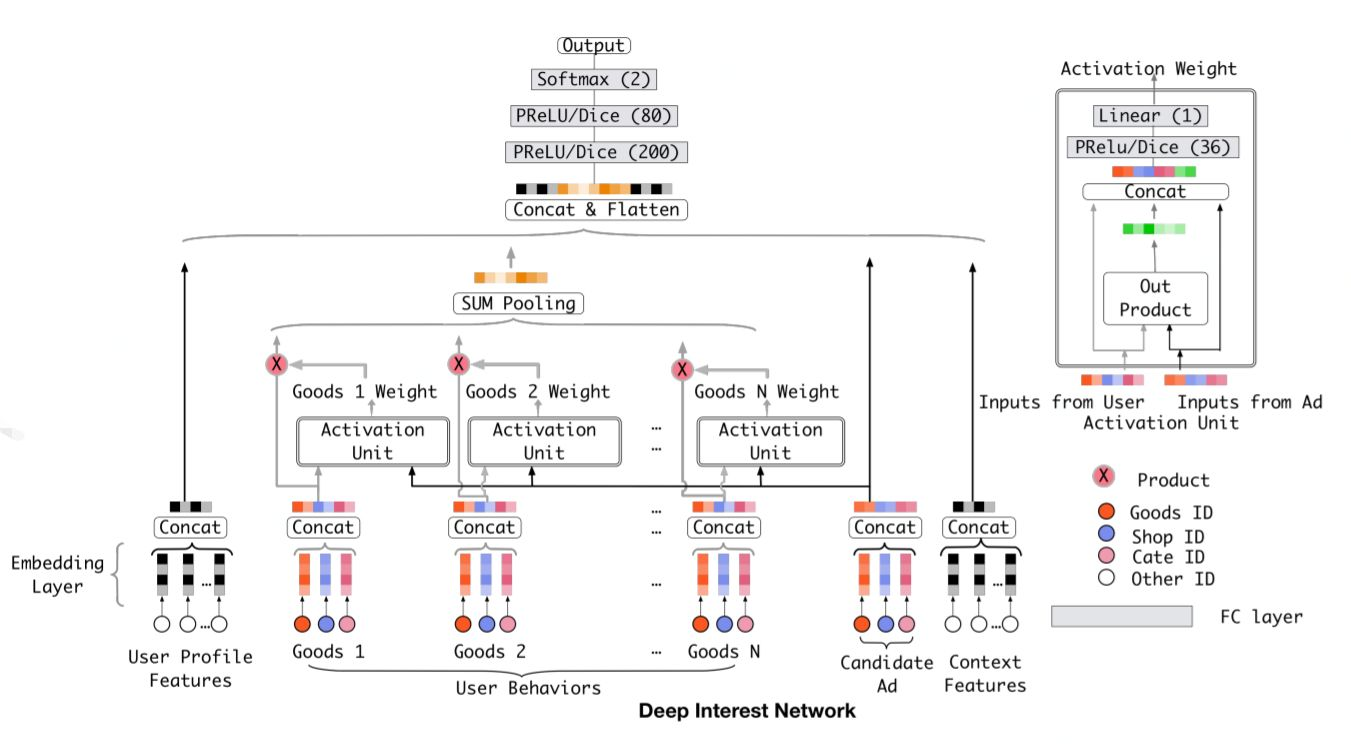
DIN核心思想#
DIN的核心思想是,对每一个用户,不同的广告有不同的向量表示,结合用户行为特征与给定的广告为每个用户行为计算权重,引入local-activation机制有侧重的利用用户不同的行为特征,其中\(e_j\)表示用户行为向量,\(v_A\)为候选广告的向量,a表示激活单元,\(a(e_j,v_A)\)为权重。整体逻辑为SUM Pooling。
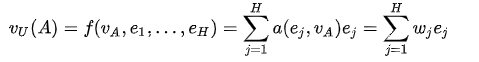
相比基础的深度推荐网络,DIN在生成用户向量的时候加了一个activation unit单元,计算每个用户行为与候选广告之间的权重。在传统的attention机制中,给定两个向量,比如u和v,通常直接做点乘。这篇论文中做了进一步的改进:首先是把u和v以及uv的外积合并起来作为输入给全连接层,最后得到权重,这样可以减少信息损失。论文中还放宽了权重加和等于1的限制,这样更有利于体现用户行为特征之间的差异化程度。
mini-batch aware regularization(MBAR)#
为解决大规模稀疏场景下,采用SGD对引入L2正则的loss进行更新时计算开销过大的问题,该方法只对每一个mini-batch中参数不为0的进行梯度更新。
自适应激活函数Dice#
PRelu激活函数如下所示:
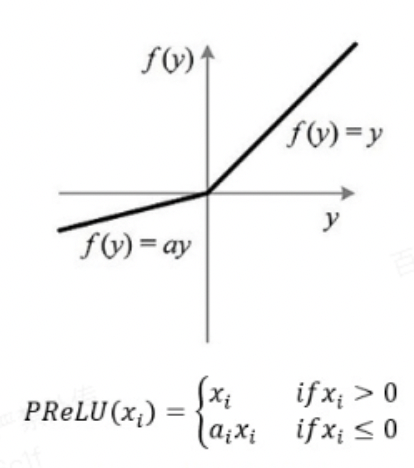
采用PRelu激活函数时,它的rectified point固定为0,这在每一层的输入分布发生变化时是不适用的,所以文章对该激活函数做了改进,平滑了rectified point附近曲线的同时,激活函数会根据每层输入数据的分布来自适应调整rectified point的位置,具体形式如下:
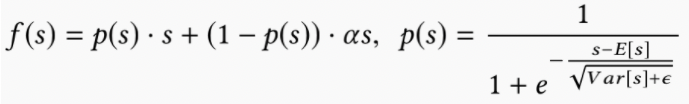
DIEN(target attention + GRU)#
阿里妈妈的精准定向检索及基础算法团队以 Deep Interest Network(DIN) 算法为基础,进一步优化升级,产出了 Deep Interest Evolution Network(DIEN)算法,主要解决了以下两个问题:
更加精确的刻画用户的长期兴趣和短期兴趣
用户的兴趣是时刻变化的,需要更加准确的刻画用户兴趣的变化
模型结构#
如图所示,DIEN 由 embedding 层、Interest Extractor Layer 层,Interest Evolving Layer 层组成。Interest Extractor Layer 根据行为序列提取兴趣序列,Interest Evolving Layer 基于 Target Ad 对兴趣序列进行建模,得到用户兴趣向量表示,最终将用户兴趣向量表示与其他特征向量 concat 到一起后送到 MLP 中以进行最终预测。
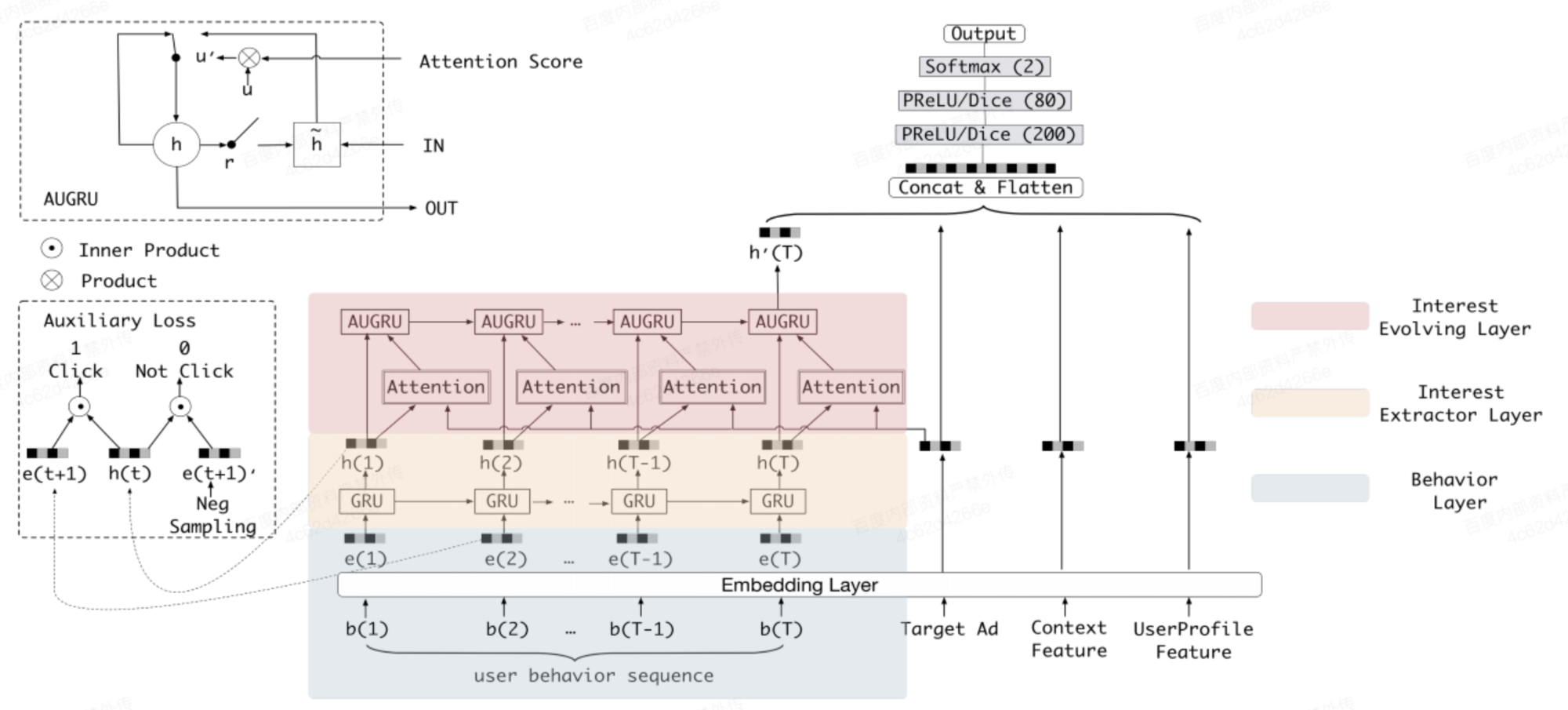
Interest Extractor Layer#
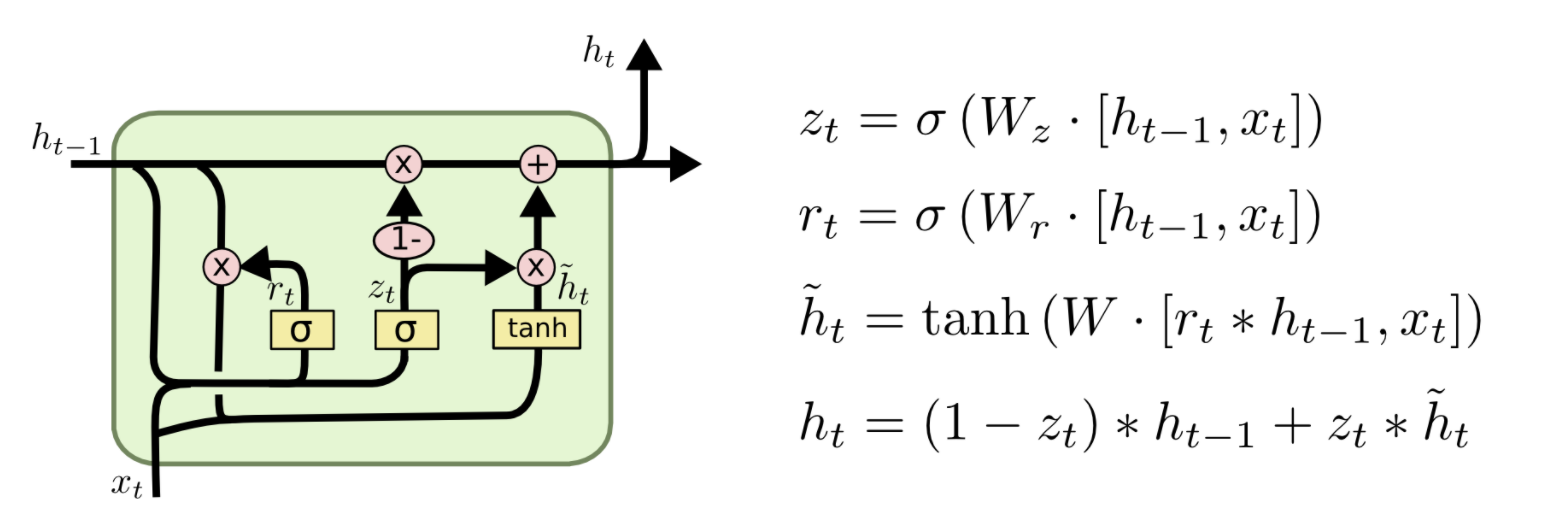
兴趣提取层的目的就是从用户的行为序列中提取出一系列的兴趣状态。为了平衡效率和性能,作者选择了GRU(Gated Recurrent Unit,门循环单元)网络来对用户行为之间的依赖进行建模。GRU既能够克服RNN梯度消失的问题,同时又比LSTM网络具有更少的参数,训练时收敛速度更快。GRU单元的表达式如下:
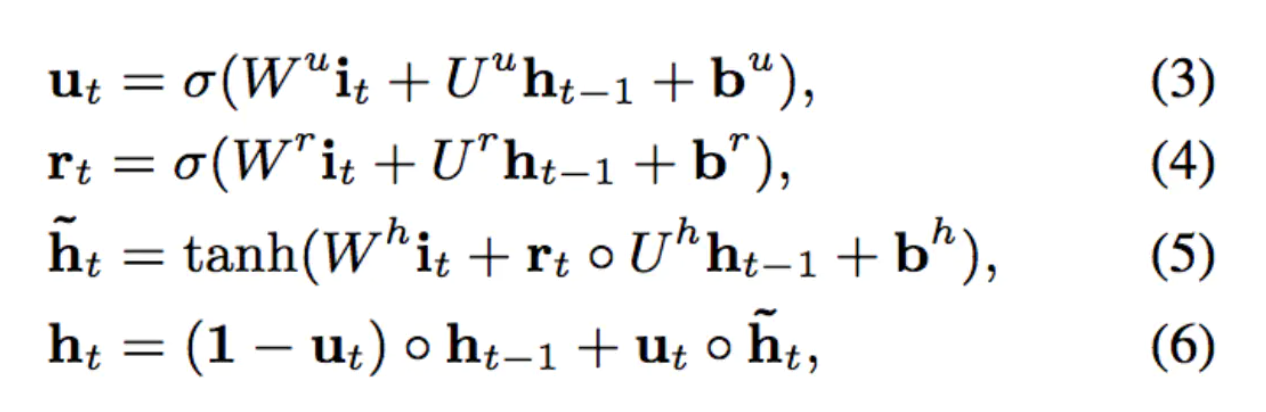
其中 \(\sigma\)表示sigmoid激活函数,\(\circ\)表示元素积(element-wise product),\(W\)和\(U\)表示隐藏层参数,\(i_t\)表示GRU单元的输入(用户第t个行为的embedding向量),\(h_{t}\)表示第t个GRU单元的隐层状态。关于GRU结构的介绍可以参考文章:GRU学习笔记,主结构如下:
辅助损失函数#
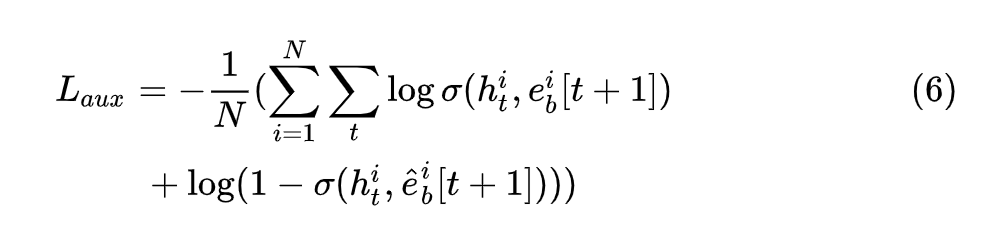
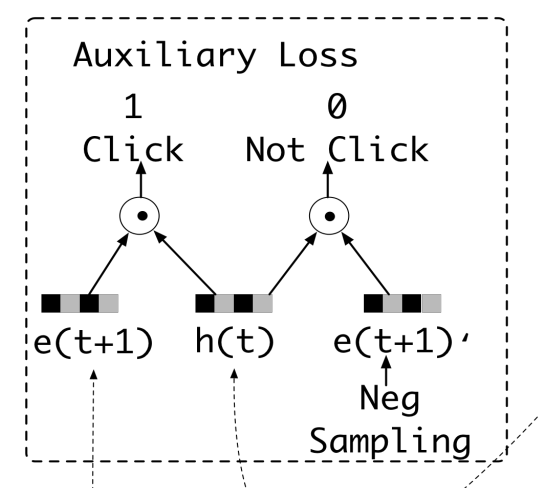
其中 \(\{e_{b}^{i},\hat e_{b}^{i}\} \in D_{\beta},i=1,2,3,...,N\)表示N对行为embedding序列,\(e_{b}^{i} \in \mathbb{R}^{T \times n_E}\)表示用户的点击行为序列,\(\hat e_{b}^{i}\in \mathbb{R}^{T \times n_E}\)表示用户没有点击的行为序列。\(T\)表示序列中历史行为的数量,\(n_E\)表示embedding向量的维度。\(e_{b}^{i}[t]\)表示第i个用户第t次点击行为的embedding向量。其中:
DIEN使用的整体损失函数是:
Interest Evolving Layer#
兴趣进化层Interest Evolution Layer的主要目标是刻画用户兴趣的进化过程。兴趣进化层的数据就是兴趣提取层的输出,兴趣进化层结合了注意力机制中的局部激活能力和GRU的序列学习能力来建模。attention部分系数计算方式如下:
将attention机制融入GRU结构中(AUGRU)#
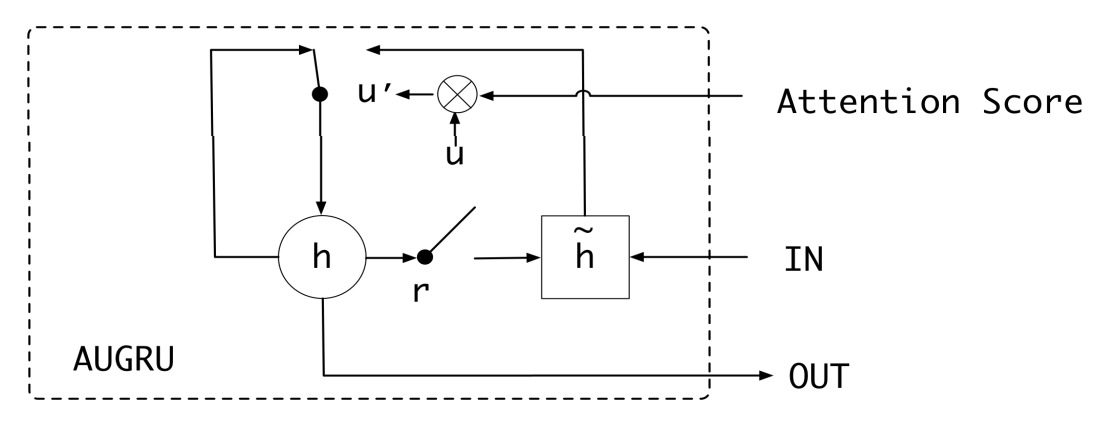
通过将attention部分的计算结果作用到GRU结构的更新门上将attention机制融入到GRU结构中。
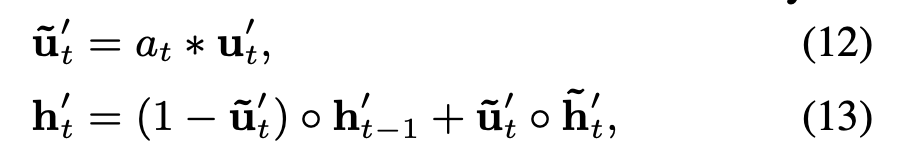
DSIN#
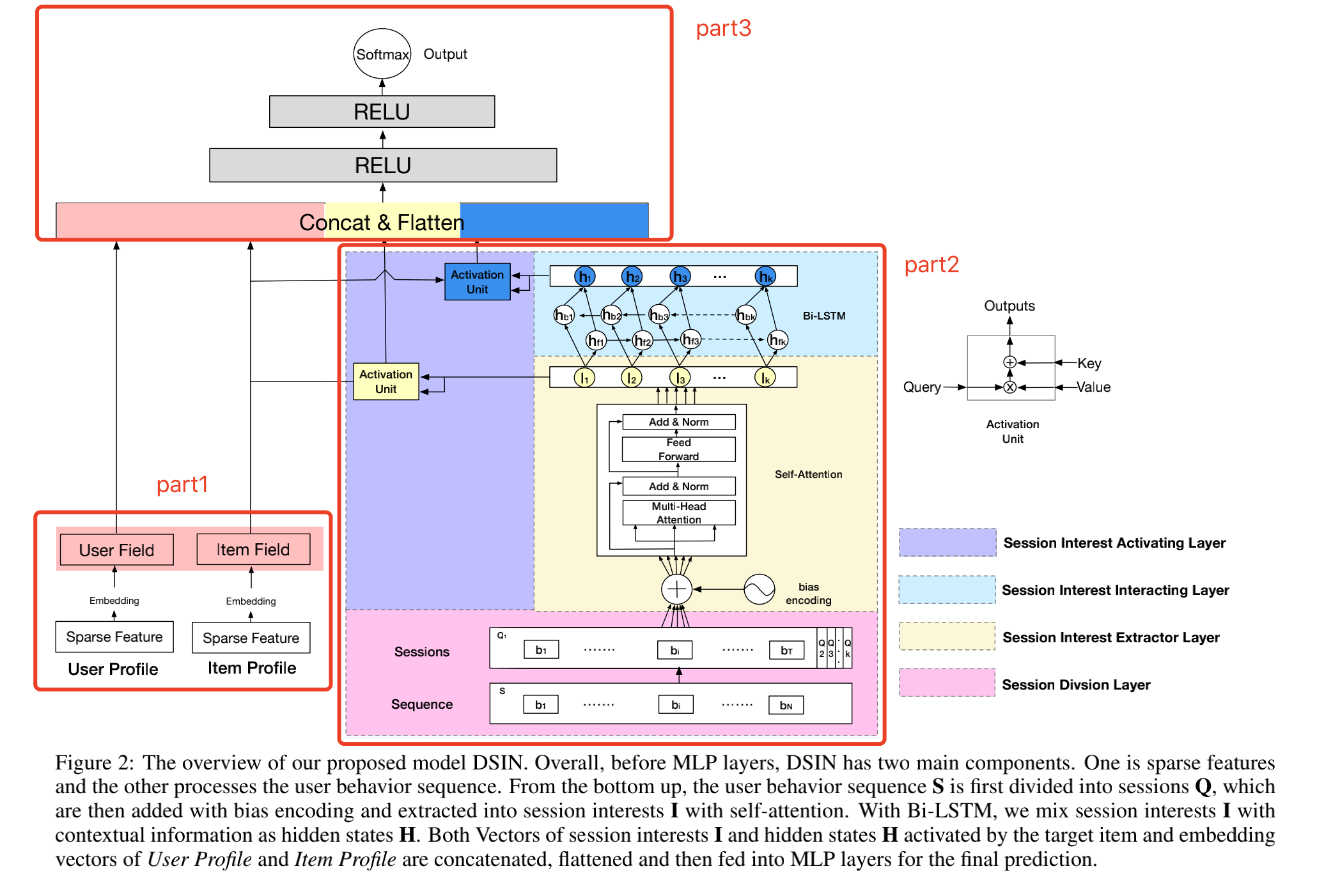
这篇文章主要介绍阿里在2019年发表的排序阶段模型:Deep Session Interest Network for Click-Through Rate Prediction。主要思路为将用户的历史点击行为划分为不同session,而后通过Transformer结构学习每个session的向量表示,最后通过BiLSTM结构对session序列进行建模,整体来说具有一定的参考意义。
模型结构(整体)#
embedding#
从图中可以看出模型主要由三大部分组成,其中第一部分(part1)主要处理用户画像特征(年龄、性别、所在城市等)和item侧特征(seller id, brand id等),处理方式也很简单,所有特征通过embedding的方式得到对应的向量表示,最终用户侧特征向量表示为\(X^U \in \mathbb{R}^{N_u \times d_{model}}\),其中\(N_u\)表示用户侧特征个数,item侧特征的向量表示为:\(X^I \in \mathbb{R}^{N_i \times d_{model}}\),其中\(N_i\)表示item侧特征个数。
建模用户序列#
这一部分(part2)主要用来建模用户行为序列,主要包含4部分:
session division layer: 对用户行为序列进行划分
session interest extractor layer: 学习每个session的向量表示
session interest interacting layer: 对session序列进行建模
session interest activating layer: 引入attention机制
session division layer#
主要作用就是将用户的历史点击行为序列划分为多个sessions。整个操作的符号表示为将用户的行为序列\(S\)划分为sessions \(Q\),第\(k\)个session的表示形式为:
其中\(T\)为当前session对应的序列长度,\(b_i\)为用户在当前session中的第\(i\)次点击行为,文中session的划分是按照时间间隔来的,两次点击之间的间隔超过30min则将下一次点击行为计入下一个session。

session interest extractor layer#
这部分的主要作用就是学习每个session的向量表示,文中使用了multi-head self-attention的结构对每个session建模。为了刻画不同session间的顺序,DSIN使用了Bias Encoding,其中\(BE \in \mathbb{R}^{K \times T \times d_{model}}\)。Bias Encoding 计算方式如下:
其中\(BE_{(k,t,c)}\)表示第k个session中的第t个物品的embedding向量中的第c个位置对应的bias,加入bias encoding后,用户的session表示为:
Multi-head Self-attention的计算逻辑为:
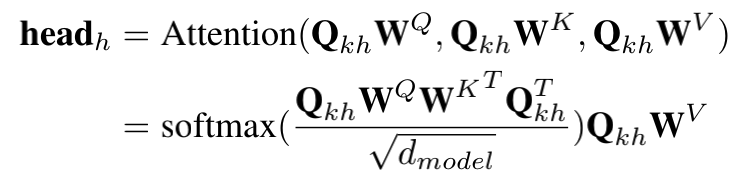
Session Interest Interacting Layer#
这部分主要通过Bi-LSTM结构对session序列进行建模。
其中\(\mathop{h_{ft}}\limits ^{\rightarrow}\)表示forward隐藏层状态,\(\mathop{h_{bt}}\limits ^{\leftarrow}\)表示backward隐藏层状态。
session interest activating layer#
这部分主要是通过attention机制刻画目标item和session之间的相关性。主要思想是若session与目标item之间的相关性越高,则应该赋予越大的权重。模型结构中共有两个Activation Unit,结构是一致的。
session interest extractor layer 相关 activation unit#
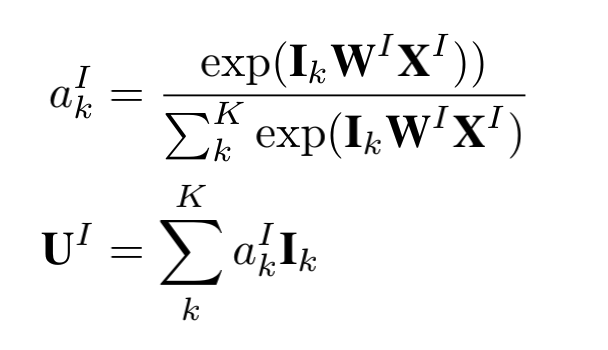
session interest interacting layer 相关 activation unit#
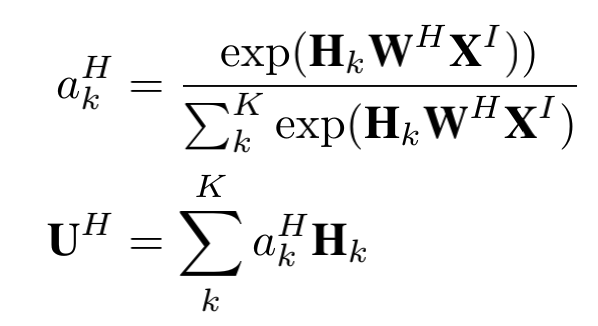
MLP#
这一部分(part3)为简单的MLP结构,首先将得到的所有向量表示concat到一起,而后通过2层前馈神经网络,最后通过一个softmax层得到输出。损失函数为:
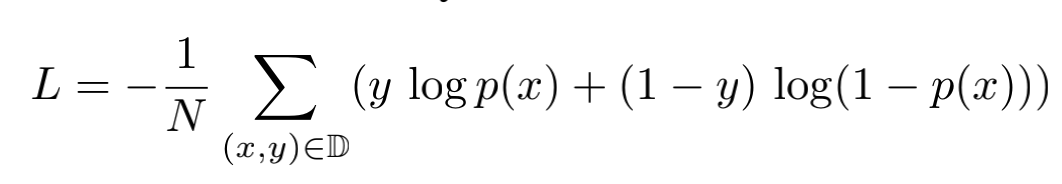
其中 \(\mathbb{D}\)表示训练集,\(y \in \{0, 1\}\),\(p(\cdot)\)表示网络最终的输出结果,表示用户点击目标item的概率。
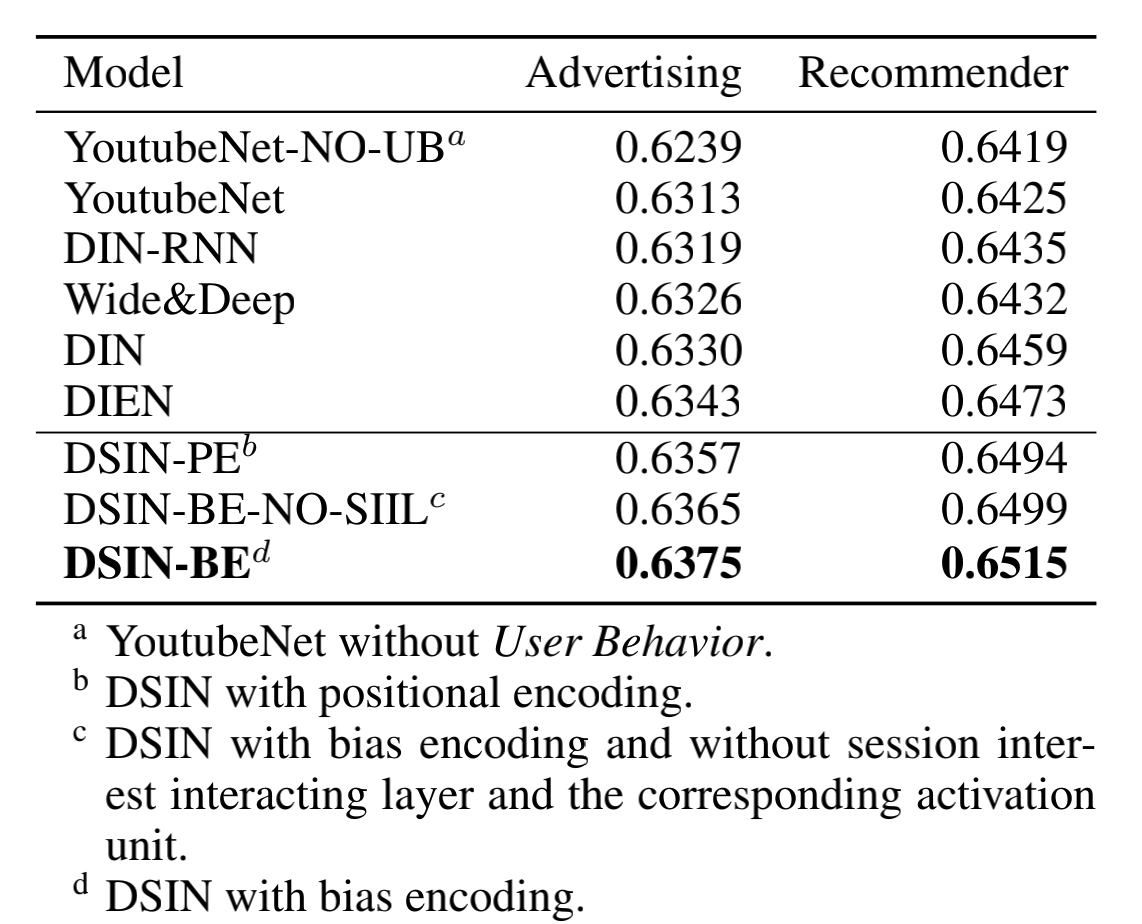
实验数据#
从实验结果来看,AUC相比其他模型均有一定幅度的提升。
京东 | Deep Multifaceted Transformers for Multi-objective Ranking in Large-Scale E-commerce Recommender#
推荐阅读⭐️⭐️⭐️⭐️⭐️
paper: Deep Multifaceted Transformers for Multi-objective Ranking in Large-Scale E-commerce Recommender
论文《Deep Multifaceted Transformers for Multi-objective Ranking in Large-Scale E-commerce Recommender》
简介#
模型应用的业务场景商品搜索排序阶段,论文提出用多个Transfomer对用户多种类型的行为序列进行建模,在此基础上叠加MMOE建模多目标,最后使用一个消偏塔对数据进行消偏。
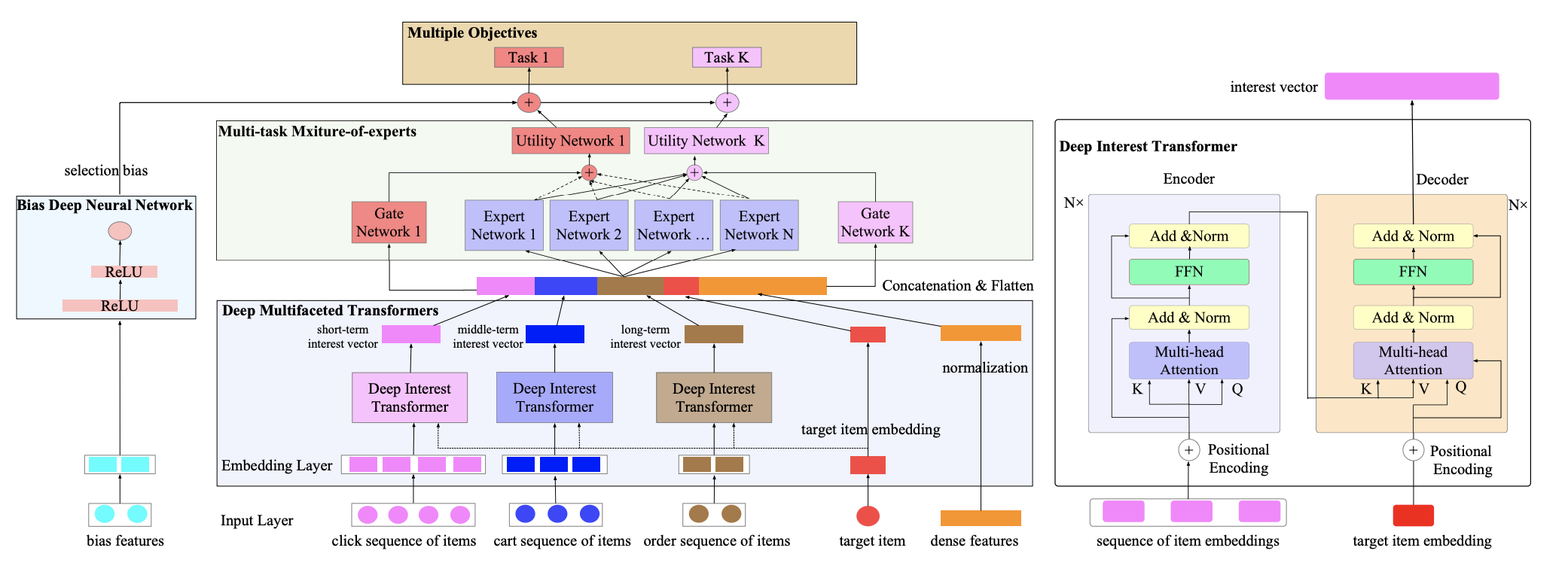
Deep Multifaceted Transformers Layer#
Embedding Layer对每个物料使用物料id、类目id、品牌id、商铺id分别映射成低维向量,然后concat起来,形成向量;Dense特征使用了Z-score归一化。模型使用了点击,加购,成交3个Item Sequence,分别表征短期,中期和长期兴趣;分别用3个Transformer来对点击、加入购物车、购买行为序列进行建模:
encoder:用序列的item-embedding作为self-attention的输入
decoder:使用target item的embedding作为query,encoder输出的结果作为key和value。
Bias Deep Neural Network#
Bais塔的输入都是偏差相关的特征,对于位置偏差输入就是展示位置索引编号或者网页索引编号;对于近邻偏差,输入就是目标物料的类目和邻近K个物料的类目。Bias建模部分使用Bias特征+MLP,输出的Logits与主网络Logits相加。
Multi-gate Mixture-of-Experts Layers#
多任务建模部分使用MMoE结构。
阿里|Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction#
推荐阅读⭐️⭐️⭐️⭐️⭐️
paper: Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction
像DIN、DIEN这些模型,都使用了Target Attention,这样可以对不相关的行为信息做一下过滤。但是这种方式在处理超长行为序列时的计算延时(latency)是不能接受的。
针对超长行为序列两步走:
General Search Unit(GSU):在用户行为序列中进行初筛,得到相关的item,压缩用户行为序列长度,初筛的方式又分两种:
soft search: 用候选item的embedding去和用户行为序列中的每一项的embedding去做点积,然后取TopK,这里可以用ALSH等比较高效的方法。
hard search: 标签匹配的方式,比如选出用户行为序列中与target item同类别的行为。
Exact Search Unit(ESU):对筛选后的用户行为序列建模。
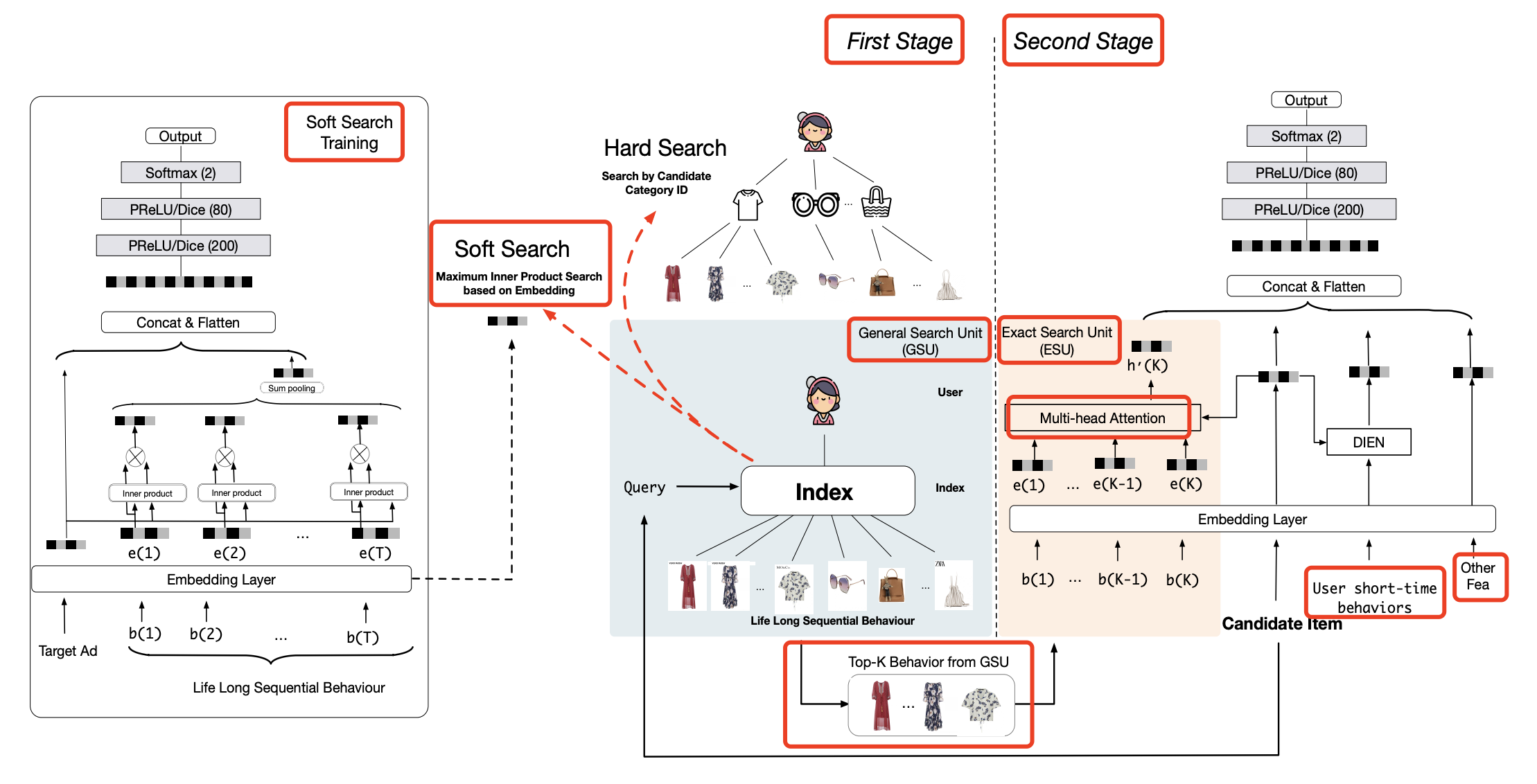
General Search Unit#
在做soft search操作时,采用的是另外一套embedding,和MLP的embedding不一样,主要是考虑到分布不一样。训练时,添加辅助loss:
使用hard serach这种方式时可以认为就是标签匹配,无参,定义好筛选规则即可。
Exact Search Unit#
和传统的DIN思路一致,这里使用的是multi head attention。
阿里BST(Transformer处理序列特征)#
推荐阅读⭐️⭐️⭐️⭐️⭐️
《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba》
阿里搜索团队在2019年发布的文章《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba》中提出了BST模型,主要思路是利用Transformer结构来捕获用户行为序列中的序列信息。与WDL(wide and deep learning networks)和DIN(Deep Interest networks)模型相比:
离线评估阶段AUC有明显的提升
线上A/B实验,CTR指标也有较大幅度提升
系统性能开销有所增加,平均响应时长指标上涨
最终模型被实际部署到线上精排阶段,文章为序列特征的处理提供了新的思路,值得学习。
模型结构#
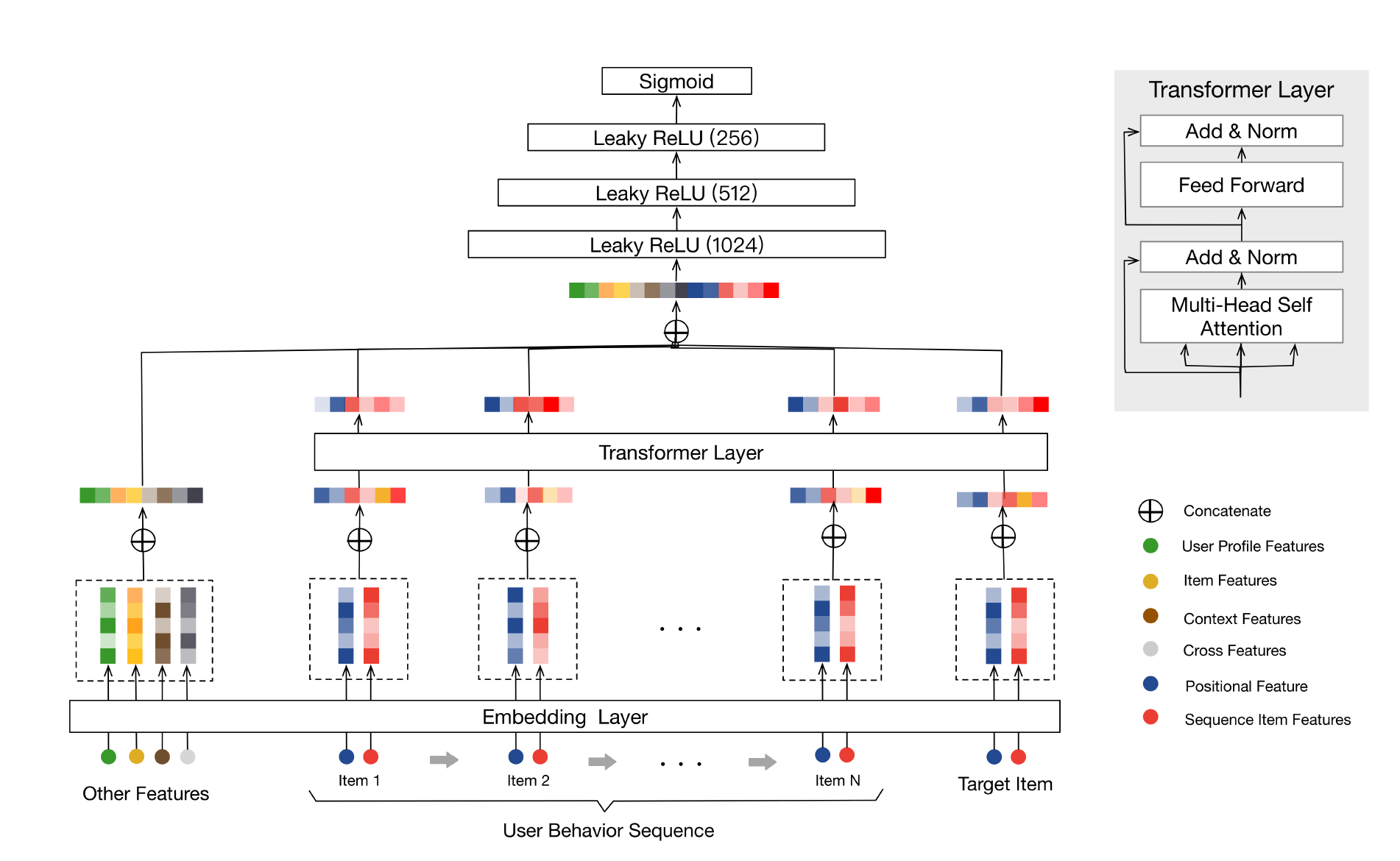
模型主要分为三大部分:Embedding Layer、Transformer Layer、MLP Layers and Loss function。
Embedding Layer#
embedding层主要作用就是把输入的每个特征都转换为低维向量,文中的特征主要包括用户行为序列特征和其他特征。其中其他特征主要包括:用户画像特征、item相关特征、上下文特征、交叉特征,如下表所示:

所有其他特征通过embedding层后,得到对应的低维向量表示,将所有的低维向量concat到一起。
用户行为序列特征主要包含两部分,一个是item相关的特征(Sequence Item Features),一个是位置特征(Positional Features)。
item相关的特征主要包含item_id和category_id(当然也可以考虑使用其他item相关的特征,文中说明在其业务场景下使用item_id和category_id即可取得足够好的效果)。
位置特征主要用来刻画用户历史行为序列中的顺序信息,文中通过自定义的计算方式\(pos(v_i)=t(v_t)-t(v_i)\)计算每个item的位置,其中\(t(v_t)\)表示推荐的时间戳,\(t(v_i)\)表示用户点击商品\(v_i\)的时间戳,然后将item的位置通过embedding层投射为低维向量。
Transformer Layer#
Transformer Layer 主要包含三个部分:Self-attention layer,Point-wise Feed-Forward Networks和Stacking the self-attention blocks。
Self-attention layer#
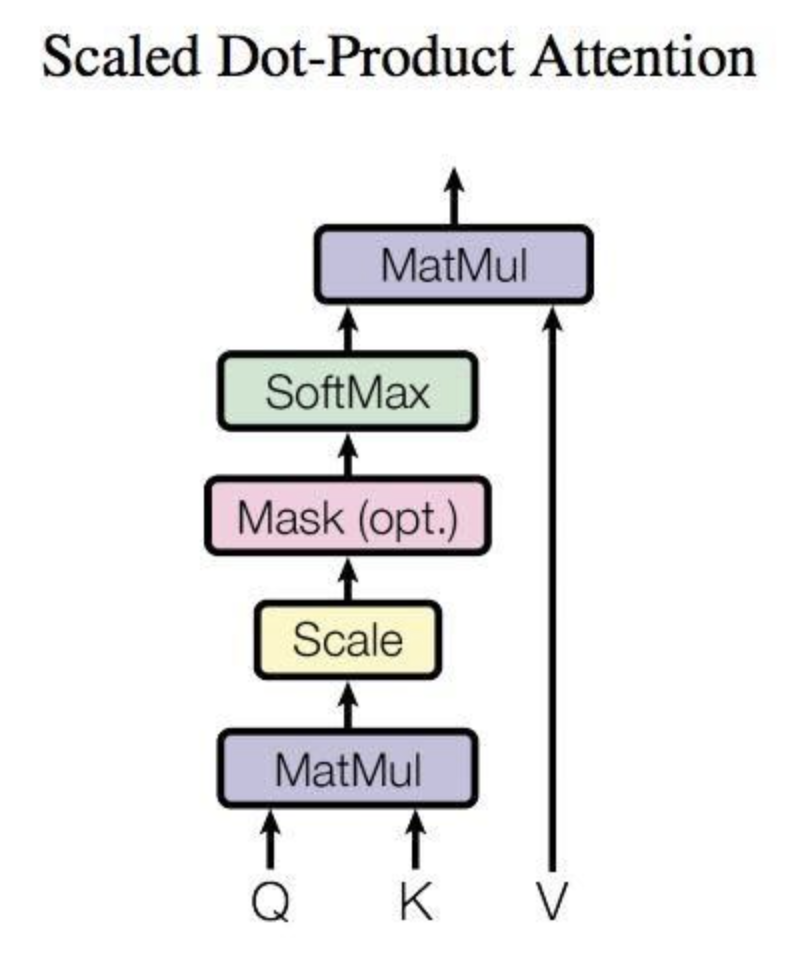
self-attention主要结构如上图所示,计算时需要用到Q(查询)、K(键值)、V(值)矩阵。self-attention接收的输入是embedding层的输出矩阵\(E\),\(W^Q, W^K, W^V \in \mathbb{R} ^ {d \times d}\),\(Q、K、V\)的计算方式如下:
attention计算方式为:
multi-head attention计算方式为:
因此,self-attention的最终输出为矩阵S(实际还会做进一步处理,后文会进一步说明)。
Point-wise Feed-Forward Networks#
BST模型也通过添加FFN网络来增加模型非线性,简单形式为:
本文中的FFN其实就是一个简单的二层网络,其中第一层的激活函数为为LeakyRelu,对于输入序列中每个位置上的向量x:
残差连接、Dropout、LayerNorm#
在Self-attention layer和Point-wise Feed-Forward Networks中均能看到残差连接、Dropout和LayerNorm的影子,其中:
残差连接主要是为了解决多层网络训练的问题
Dropout主要是为了防止模型过拟合
LayerNorm(Layer Normalization)通常用于RNN结构,会将每一层神经元的输入都转成均值方差都一样的,可以加快模型收敛
实际上self-attention的最终输出为: $\( S' = LayerNorm(S+Dropout(S)) \)$
Feed-Forward Networks(FFN)的最终形式为:
Stacking the self-attention blocks#
这一部分即上文介绍的self-attention + FFN的堆叠结构(本文中尝试过1~3层的堆叠结构,单层结构效果是最好的)。
MLP layers and Loss function#
将所有的embedding进行拼接,输入到三层的神经网络中,并最终通过sigmoid函数转换为0-1之间的值,代表用户点击目标商品的概率。loss函数为:
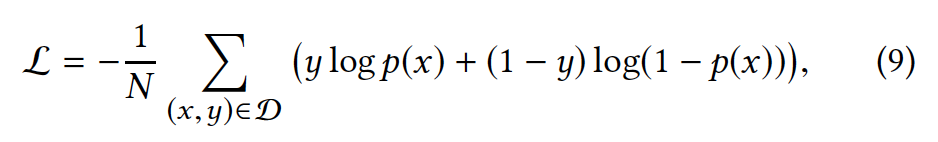
实验数据#
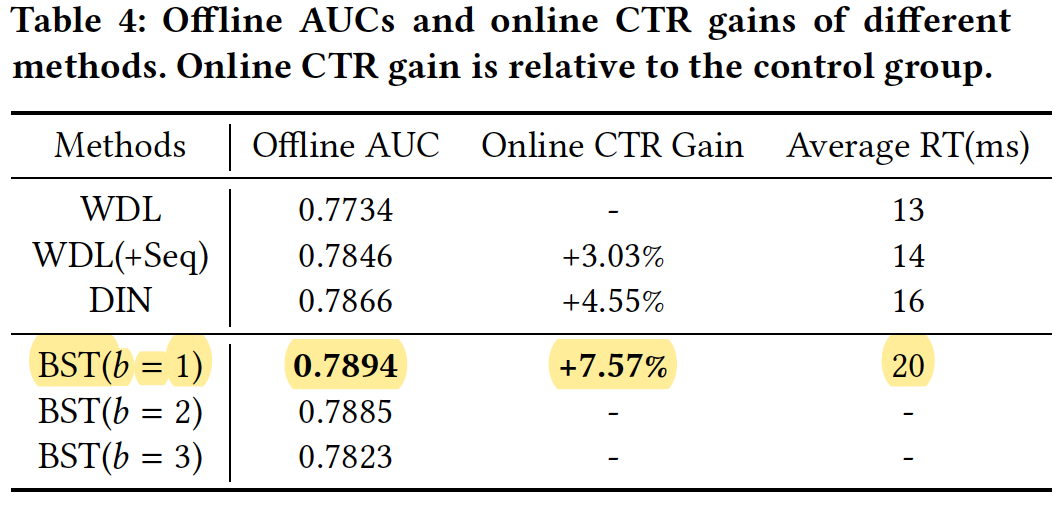
可以看到BST模型与其他模型相比离线AUC评估指标有大幅度的提升,线上A/B实验,点击率也有大幅度的提升,但模型性能开销也有相应的提升(平均响应时长有一定程度的上涨)。
阿里DMR(attention)#
DIN等模型将学习到的Sequence Embedding(用户兴趣向量)、User Profile、待排序物品特征等Concat后送入最上层的MLP进行特征交叉最终输出一个CTR预估分数,作者认为在Concat特征送入MLP进行交叉前就计算一个User和Item相关性可以降低模型的学习难度。
DMR可以看做是另一种对DIN的改进方式。文章提出了两种网络结构,Item-to-Item网络和User-to-Item网络,来描述用户和候选目标item是否匹配。
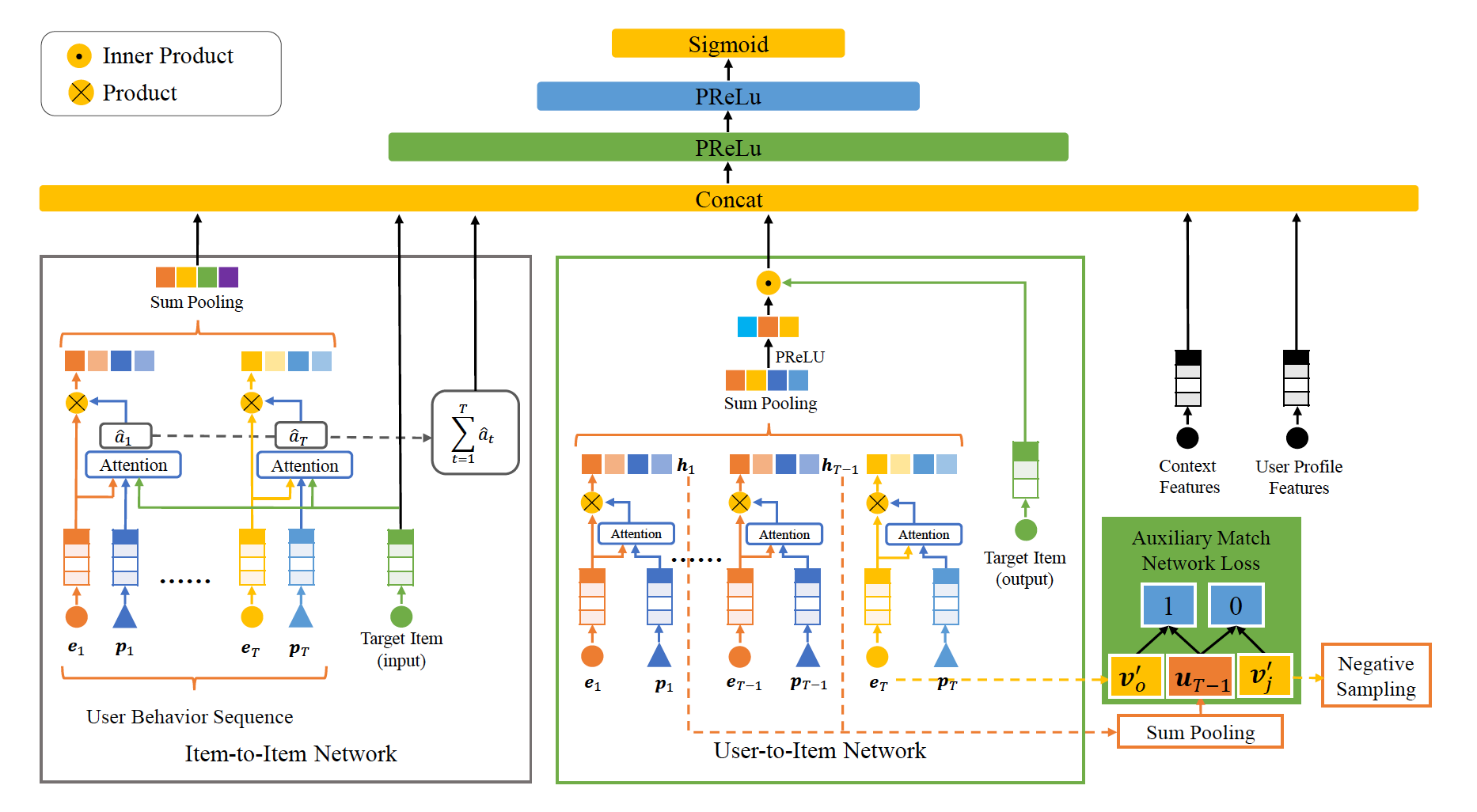
Item-to-Item Network#
\(e_i\)是用户行为序列中每个item的embedding,\(p_i\)是用户行为在序列中的位置embedding,文章通过融合行为embedding、位置embedding和target item embedding计算attention权重。
通过softmax得到最终权重,将权重作用到每个行为embedding上,通过sum pooling的方式得到用户行为序列的向量表示。
此外item-to-item network子网络的输出还包括target item embedding,以及sofatmax之前各个行为embedding的attention权重和。
User-to-Item Network#
在计算attention的时候并不考虑target item。
一般来说,用户的兴趣会随着时间发生变化,距离现在更近的行为更能反映用户的真实兴趣。根据用户行为发生的时间为用户行为指定权重可以解决这个问题,采用attention机制,把用户行为出现的位置按时间排序后,用数字编码,当做query(这里也可以根据具体业务替换为其他重要的特征),自主地为每个行为计算attention权重。
通过softmax得到最终的attention权重:
将权重作用到每个行为embedding上,最后再通过sum pooling + 非线性变换的方式得到用户行为序列的向量表示。
最后跟target item embedding 做内积运算来表示用户和目标商品的匹配程度,最终输入到MLP网络(同样的问题,这种单值特征的作用大么?)。
引入一个辅助训练网络来帮助训练,确保点积结果越大代表用户和target item的相关性越高。在辅助训练的时候,使用行为序列中的前T-1个行为学习用户表示,而用最后一个行为作为正样本,使用负采样的方法随机获得负样本。\(p_j\)表示匹配分值,\(L_{NS}\)表示辅助网络loss,\(L_{final}\)表示最终 loss。
阿里MIND#
推荐系统一般包含两个重要阶段:召回和排序,召回阶段负责从海量候选中选出用户感兴趣的候选集,排序阶段再对用户感兴趣的候选集进行排序取出TOPN。在这两个阶段一个很重要的因素就是如何建模表征用户兴趣,目前大部分模型都以单向量表征用户,MIND模型提出了一种用多个向量表征用户的思路。

模型的核心思想:
利用multi-interest提取层(以胶囊网络和动态路由算法为基础)结合用户历史行为,提取用户的多元兴趣。
通过label-aware attention机制帮助学习用户的多元向量表示。
模型介绍#
模型整体结构图#
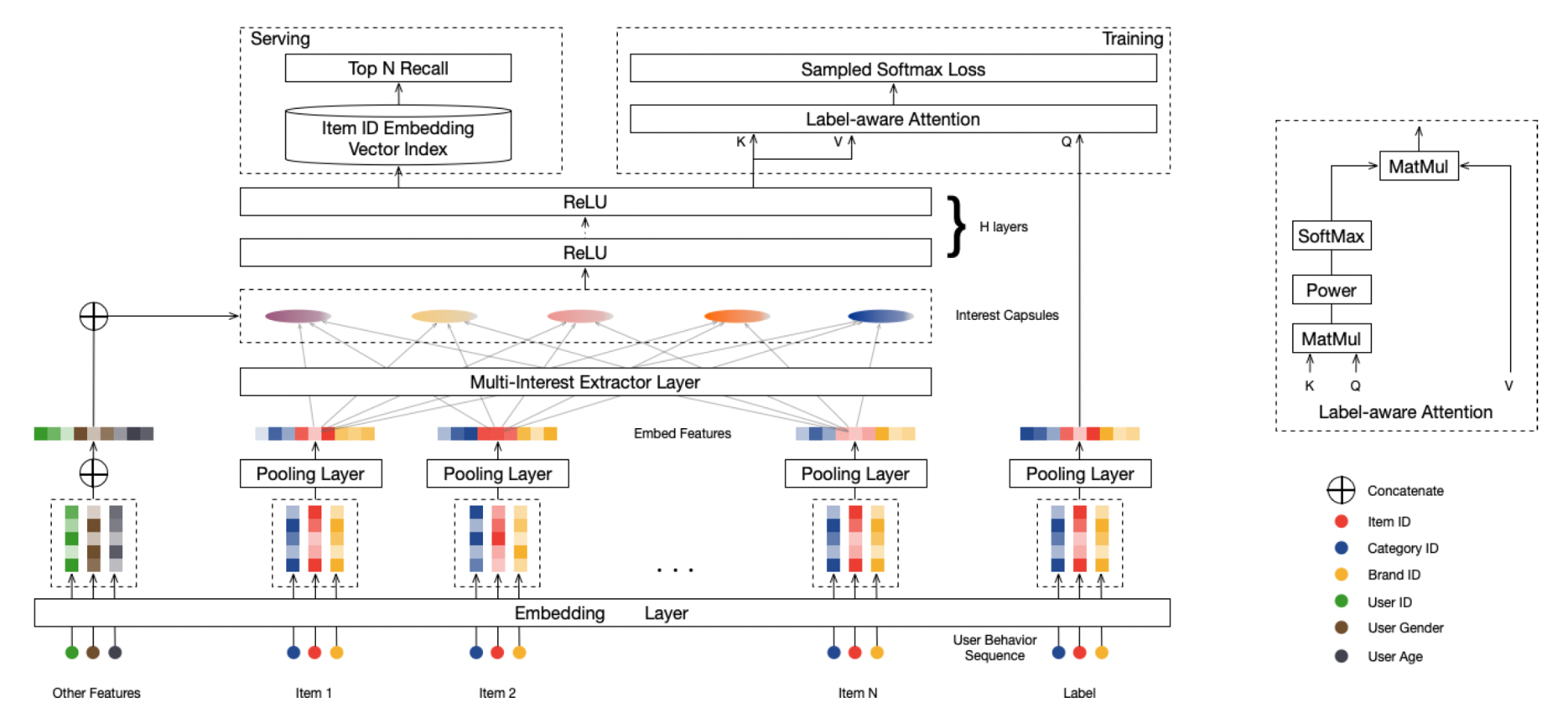
模型定义#
首先介绍一下三元组\((I_u, P_u, F_i)\)中各个组成部分的含义,\(I_u\)表示与用户交互过的商品(用户历史行为),\(P_u\)表示用户画像特征(例如年龄、性别等),\(F_i\)表示商品的特征(例如商品id、一级分类等)。
MIND的核心是学习以下函数表达:
其中 \(V_u\) 是 \(d \times K\) 维的矩阵,d表示每个向量的维度,K表示向量个数。
目标商品的向量表示可以定义为:
其中\({e_i}\)为d维向量。
模型候选打分计算公式:
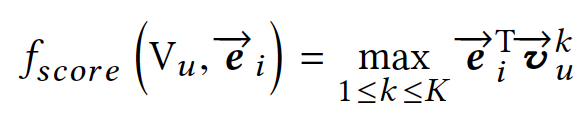
即用户的每个向量与候选物料计算打分取最大值作为模型最终打分。
模型结构#
模型主要分为以下四部分:
Embedding & Pooling Layer
Multi-Interest Extractor Layer
Label-aware Attention Layer
Training & Serving
Embedding & Pooling Layer#
这一层逻辑比较简单,\(I_u\)、\(P_u\)、\(F_i\)均通过embedding层转化为embedding向量,而后通过average pooling得到最终的向量表示。
Multi-Interest Extractor Layer#
这一层通过胶囊网络学习用户的多个兴趣向量表示,来表示用户的多种兴趣。这一层涉及到胶囊网络和动态路由算法,会在其他文章中详细展开。
Label-aware Attention Layer#
这一部分的原理其实也比较简单,这一层的输入即为通过Multi-Interest Extractor Layer提取到的多个用户兴趣向量(兴趣胶囊),每个用户兴趣向量表示不同的用户兴趣,通过Label-aware注意力机制确定通过这些用户兴趣向量计算最终的用户向量\(\vec{v_{u}}\)时各自的权重。
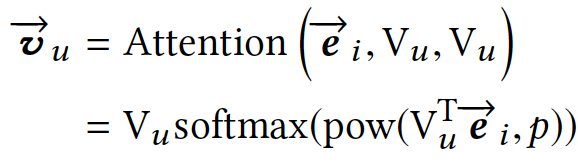
其中p为调节参数:
当p为0时,那么每个用户兴趣向量有相同的权重
当p>1时,p越大,与目标商品向量点积更大的用户兴趣向量会有更大的权重
当p为无穷大时,实际上就相当于只使用与目标商品向量点积最大的用户兴趣向量,忽略其他用户向量,可以理解是每次只激活一个兴趣向量,文章指出使用这种方法收敛最快。
Training & Serving#

得到用户向量\(\vec{v_{u}}\)和商品向量\(\vec{e_{i}}\)之后,通过下式可以计算得到用户对商品的交互概率:
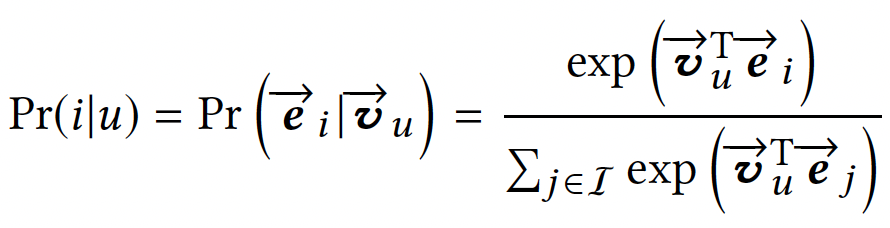
模型的目标函数:
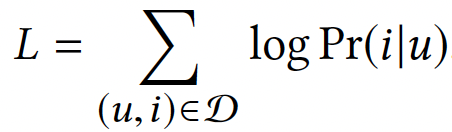
模型采用了sampled softmax的方式降低开销。
在Serving阶段,算出每个用户的多个向量后,每个向量都可用于为用户召回商品,最终从所有召回结果中挑选出TOPN。
整个过程可以参考Youtube DNN。