Table of Contents
推荐系统08-图神经网络#
图模型总结#
图模型适合数据稀疏的场景,图神经网络允许知识信息在图中进行远距离传递,对于用户行为较少的场景,可以形成知识补充和传递;图模型能够提高embedding表达能力,图网络能够将协同信息、用户行为信息、内容属性信息等各种异质信息在一个统一的框架里进行融合,表征为embedding。
常见应用场景:基于图神经网络的CF召回#
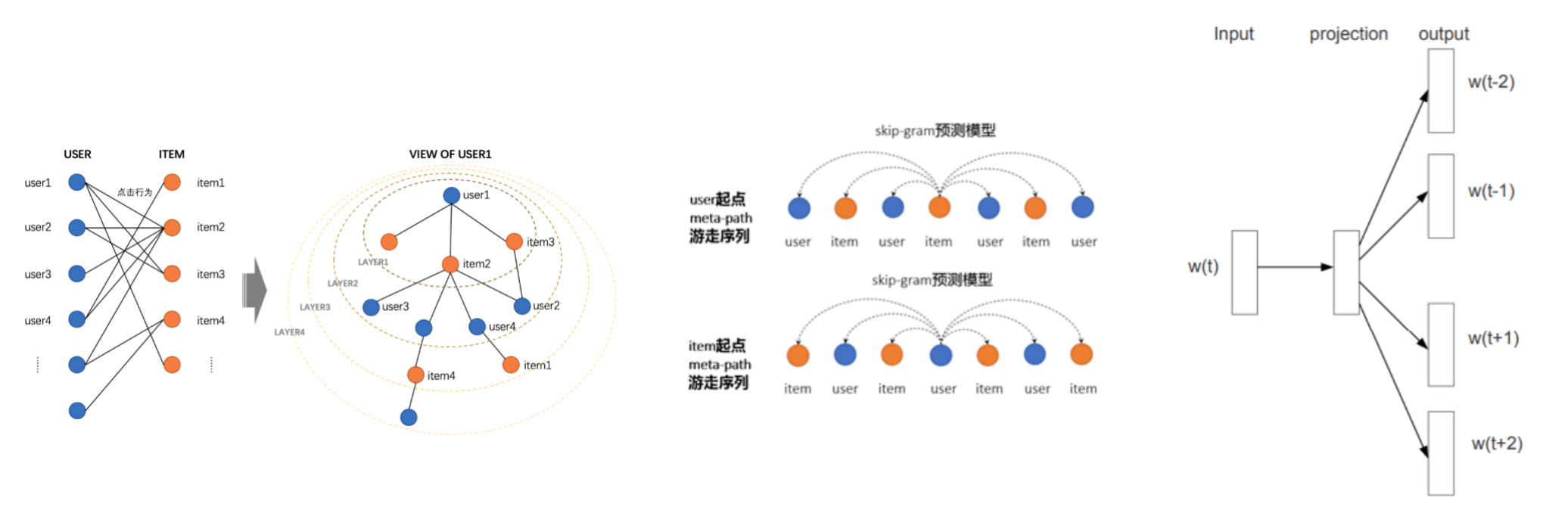
step1: 基于user-item关系的游走产生序列
step2: 用 skip-gram + negative sampling 算法学习每个节点的embedding表示
step3: 基于 User 向量和 Item 向量分别构建 UCF 召回和 ICF 召回等
DeepWalk#
推荐阅读⭐️⭐️⭐️⭐️⭐️
DeepWalk: Online Learning of Social Representations
近年来,图神经网络 (GNN) 在各个领域越来越受欢迎,包括社交网络、知识图谱、推荐系统等。
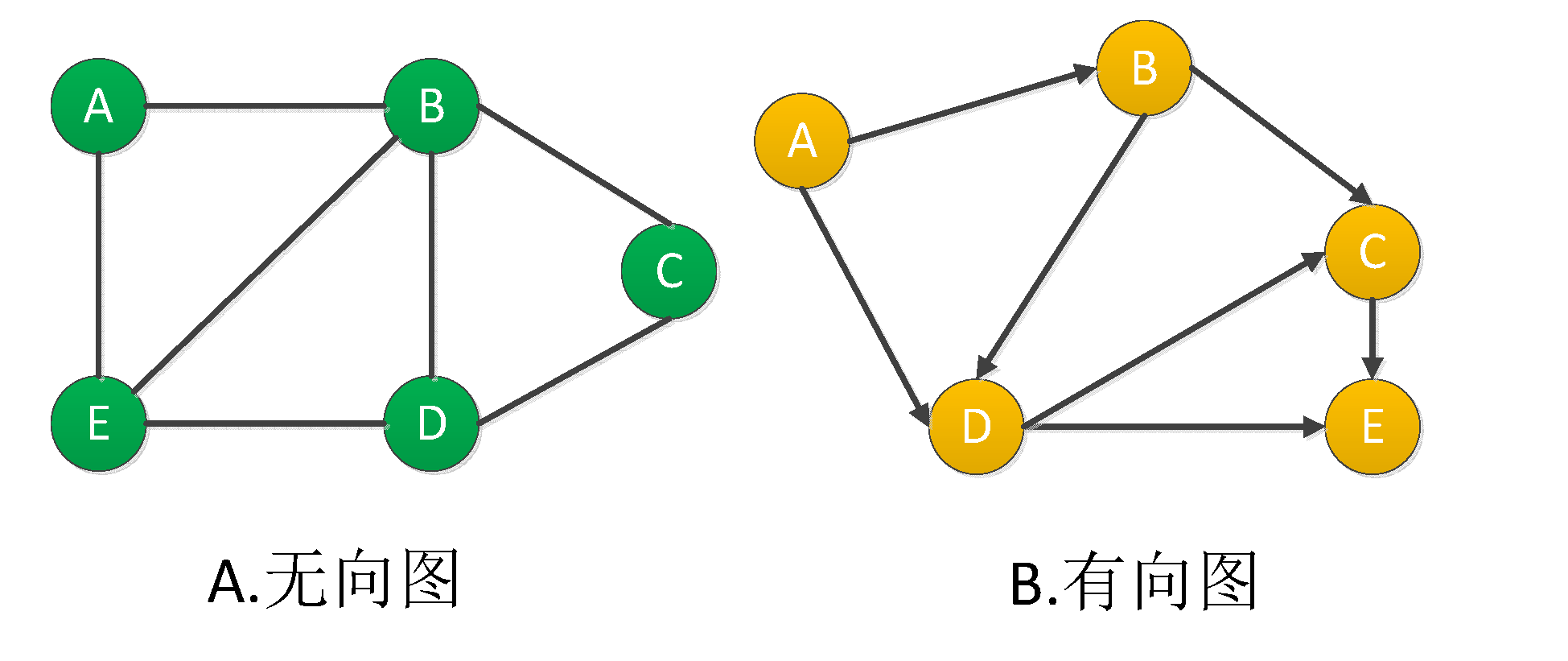
图是由两个部件组成的一种数据结构:顶点(vertices)/节点(nodes) 和边 (edges)。一个图 G 可以用它包含的顶点 V 和边 E 的集合来描述。
图又分为有向图和无向图,这取决于顶点之间是否存在方向依赖关系。
介绍 DeepWalk 之前简单描述一下Graph Embedding 技术,简单点说 Graph Embedding 技术就是得到图中每个节点的向量表示,之后就可以用得到的向量做各种各样的事情。
DeepWalk 的思想类似 word2vec,使用图中节点与节点的共现关系来学习节点的向量表示。那么关键的问题就是如何来描述节点与节点的共现关系,DeepWalk给出的方法是使用随机游走(RandomWalk)的方式在图中进行节点采样。
算法包括两个步骤:
step1: 在图中的节点上执行随机游走生成节点序列
step2: 运行skip-gram,根据步骤 1 中生成的节点序列学习每个节点的嵌入
在随机游走过程中,下一个节点是从前一节点的邻居统一采样。然后将每个序列截短为长度为2|w|+1的子序列,其中 w 表示 skip-gram 中的窗口大小。
在论文中,使用分层softmax解决节点数量庞大导致softmax计算成本过高的问题。
伪代码:

DeepWalk 的主要问题是缺乏泛化能力。每当一个新节点出现时,它必须重新训练模型以表示这个节点。因此这种 GNN 不适用于图中节点不断变化的动态图(需要解决 embedding 冷启动问题)。
GCN#
GCN 的主要公式: $\( H^{(l+1)} = \sigma(\tilde{D} ^ {-\frac{1}{2}} \tilde{A} \tilde{D} ^ {-\frac{1}{2}} H^{(l)} W^{(l)}) \)$
如果去掉 \( \tilde{D} ^ {-\frac{1}{2}} \tilde{A} \tilde{D} ^ {-\frac{1}{2}} \) 部分,GCN 主要公式可以简化为:
可以看成一个简单的全连接神经网络。
公式中各项的计算方式#
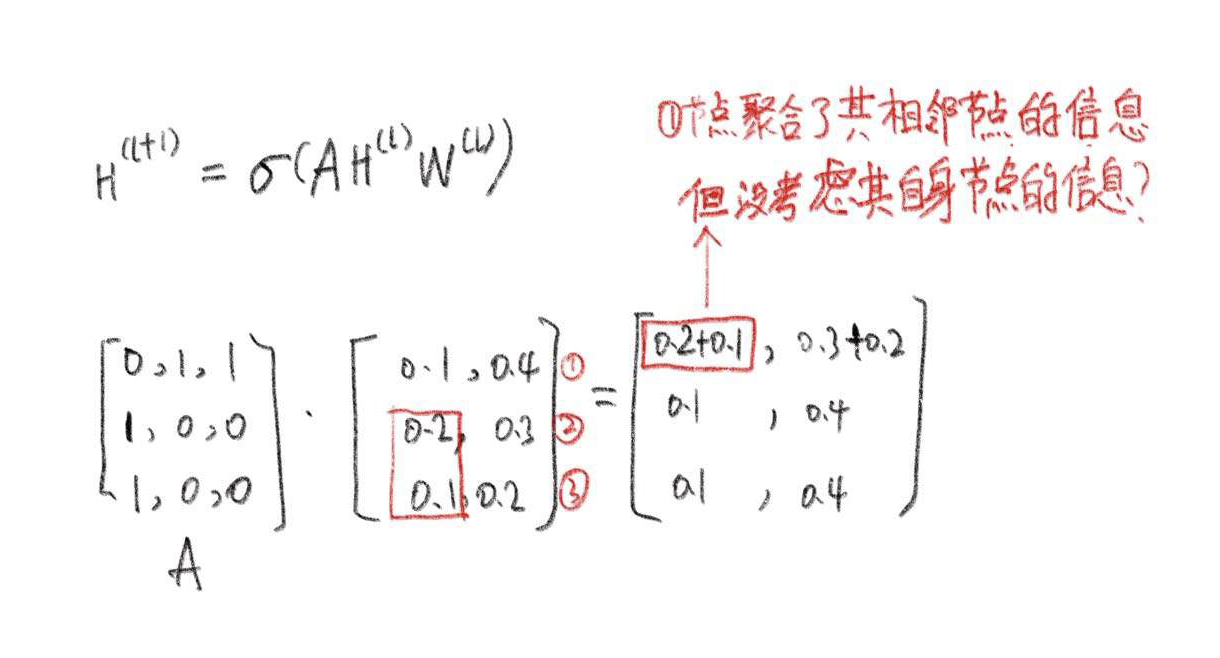
假设有一个图:
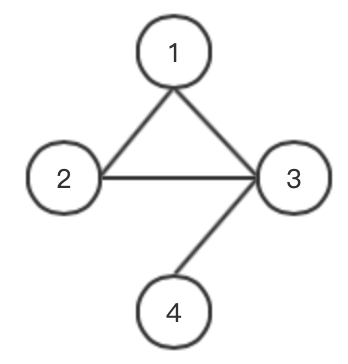
给出公式中每一部分的值,邻接矩阵 A 为:
单位矩阵\(I_N\)为:
\(\tilde{A} = A + I_N\):
\(\tilde{A}\) 矩阵按行求和得到 \(\tilde{D}\),即 \(\tilde{D}_{ii} = \sum_{j} \tilde{A}_{ij}\):
公式中各项的的计算方式如上,下面用一个更简单的实例介绍公式的实际含义。
公式含义说明#
假设有一个图如下,图中每个节点对应一个 embedding 向量。

两层的 GCN 网络示意图#
首先计算好 \(\hat{A} = \tilde{D} ^ {-\frac{1}{2}} \tilde{A} \tilde{D} ^ {-\frac{1}{2}}\)
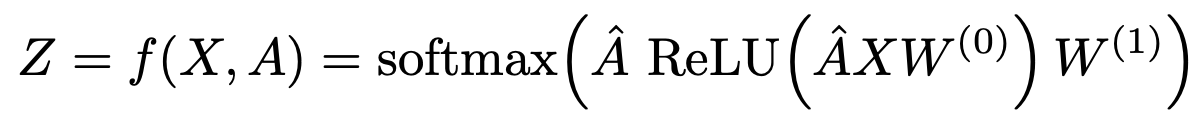
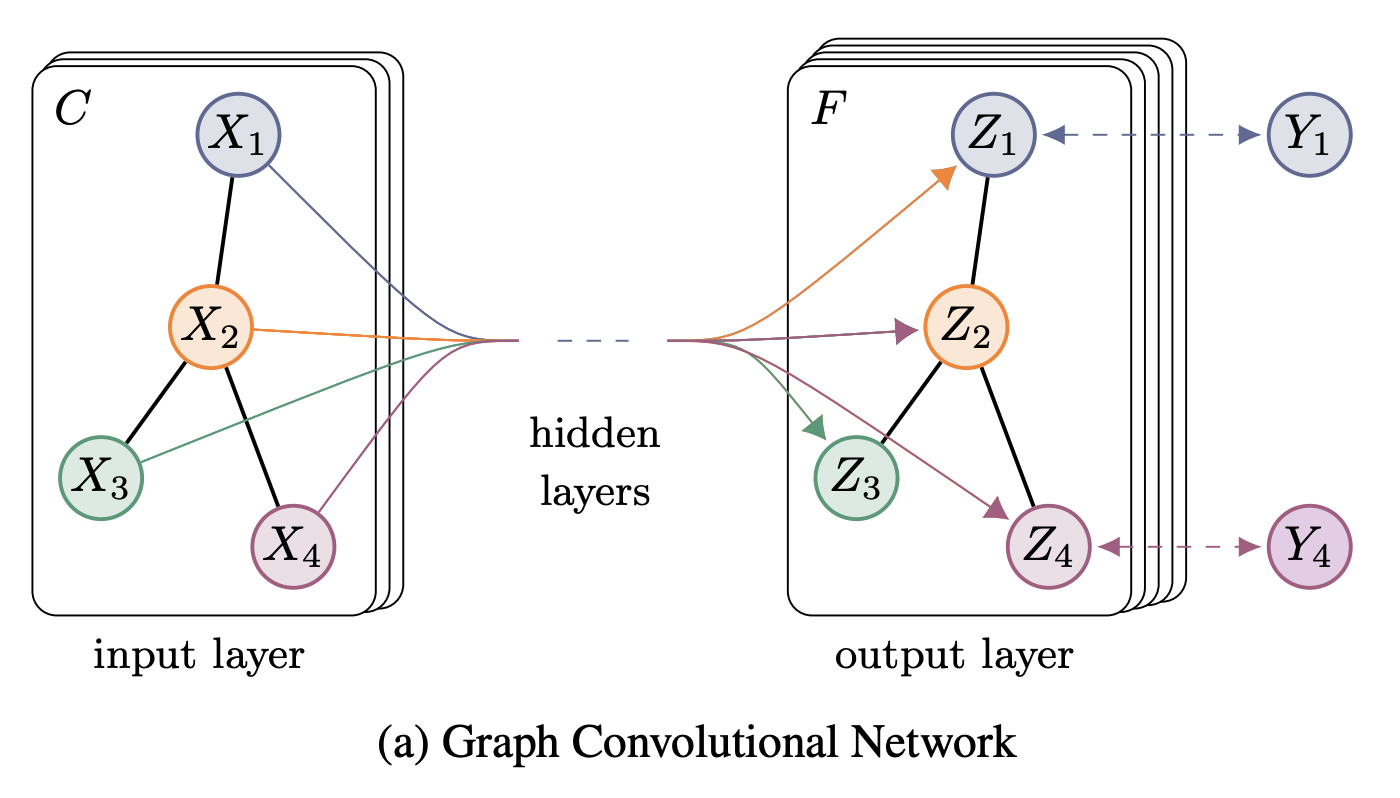
假设 N 为节点数,则 \(\hat{A}\) 维度为 (N, N)。
假设输入层的维度为 (N, C),第一个隐藏层维度为 (C, H),第二个隐藏层的输出维度为 (H, F):
第一个隐藏层的输出维度为 (N, H):
第二个隐藏层的输出维度为 (N, F):
阿里EGES#
在推荐系统中,有三个主要挑战,分别是可扩展性(scalability)、稀疏性(sparsity)、冷启动问题(cold start)。阿里淘宝团队提出了基于图神经网络的EGES算法来应对这三个挑战。
论文题目是《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》,通常推荐系统都包含召回、排序等几个阶段,这篇文章主要聚焦召回阶段。
文章共涉及到三个模型:
Base Graph Embedding(BGE)
Graph Embedding with Side Information(GES)
Enhanced Graph Embedding with Side Information(EGES)
基于用户历史行为构图#
第一步是基于用户历史行为构图,考虑到性能开销,不可能根据用户整个的历史行为构图,其次考虑到用户的兴趣有随着时间迁移的情况,因此在基于用户历史行为构图时,设定了一个时间窗口,只考虑时间窗口内的用户历史行为(session-based users’ behaviors)。
获取指定时间窗口内的用户历史行为后,例如用户U1的历史行为序列为DAB,对应图中的两条有向边D->A和A->B,如图中的(a)、(b)所示。
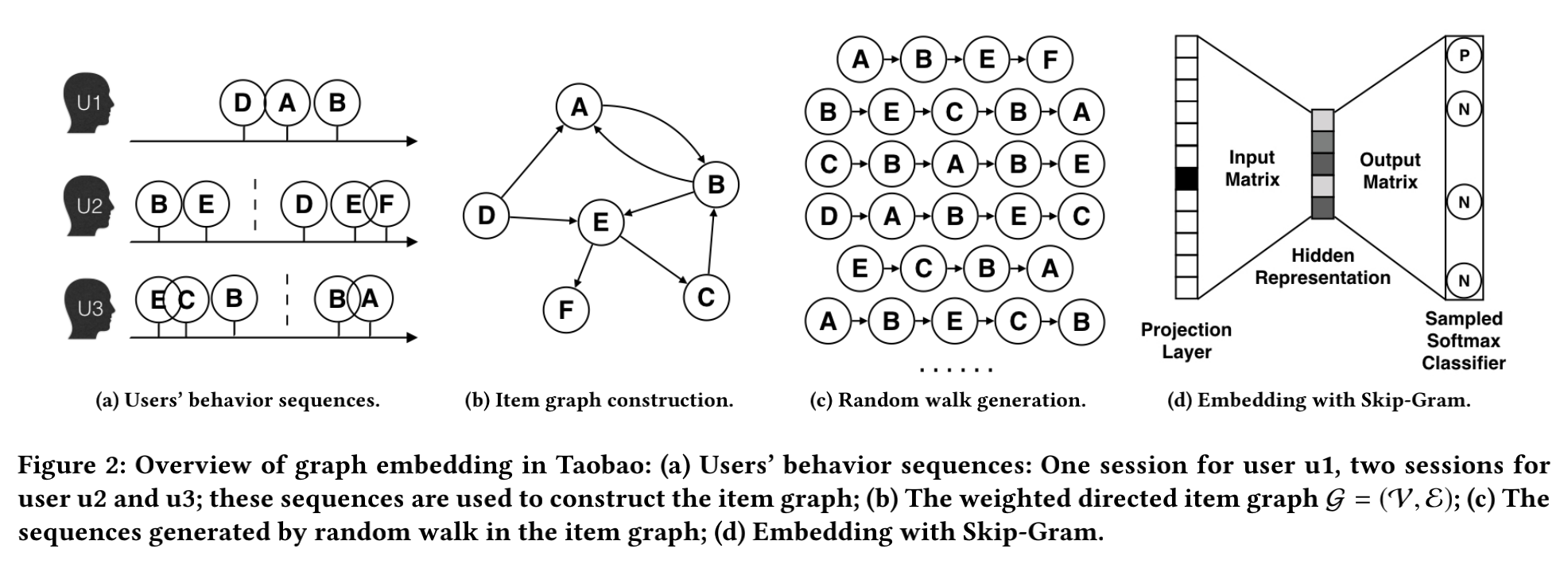
实际业务场景中存在大量的脏数据,如果不做数据清洗,很可能影响到到模型效果,所以在构图前也做了一些数据清洗工作:
用户点击后在相关页面停留时间少于1s,则认为点击行为不置信,构图前需要清洗相关的行为。
3个月内用户累计购买超过1000次或点击超过3500次则认为用户是过度活跃的用户,构图前需要清洗此类用户。
淘宝上的零售商一直在更新商品的细节,在极端的情况下,同一标识符的商品在淘宝上经过长时间的更新后可能会变成完全不同的商品,构图前需要清洗相关商品的行为。
BGE#
基于用户历史行为构图,得到一张带权有向图,入上图中的(b)所示,用\(\mathcal{G}=(\mathcal{V}, \mathscr{E})\)。\(M\)为图\(\mathcal{G}\)的邻接矩阵,其中\(M_{ij}\)表示图中节点i到节点j的边的权重。首先使用random walk的产出序列,如上图中的(c)所示。最后基于Skip-Gram算法学习每个节点的embedding表示。其中random walk时的转移概率的计算方式如下:
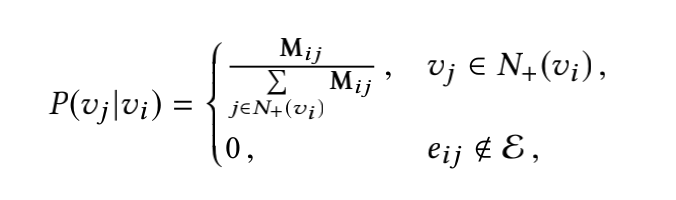
其中\(N_{+}(v_i)\)表示\(v_i\)节点的邻居节点集合。
GES#
BGE模型对于交互行为少商品不太友好,会出现对应商品的embedding向量表示学习不够充分的问题,模型存在比较严重的冷启动问题,为了解决冷启问题,在BGE模型的基础上提出了GES模型。与BGE模型,改进模型的基本思路是为图中的每个节点增加额外信息(Side Information),例如Category、Brand、Price等来强化item的向量表示。
我们定义矩阵\(W\)表示物品及其side information的embedding向量表示,\(W_v^0\)表示物品\(v\)自身的向量表示,\(W_v^s\)表示物品\(v\)第s类side information的向量表示。
最终物品的向量表示为:
EGES#
考虑到在计算物品的最终向量时,不同类型的side information的贡献应该是不同的,所以在聚合side information时可以添加attention机制。
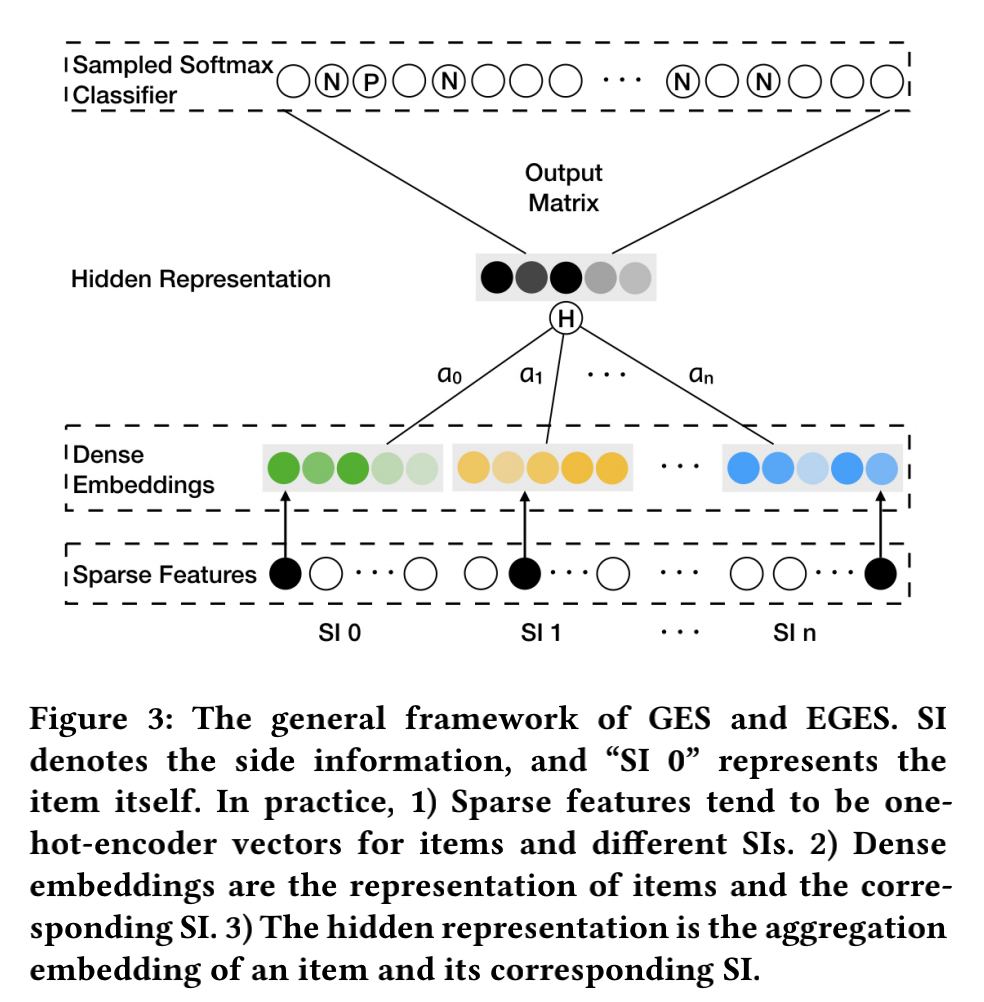
定义一个矩阵 \(A \in \mathbb{R}^{V \times (n+1)} \),\(V\)表示的是图中所有节点的数量,n表示side information的类型数,\(A_{ij}\)表示第i个item的第j类side information的权重,\(A_{i0}\)表示第i个item自身的权重,依次类推。方便起见使用\(a_v^s\)表示物品\(v\)的第\(s\)类side information的权重。
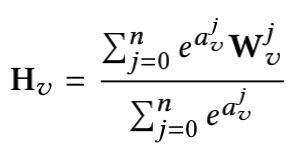
在这里我们使用\(e^{a_v^j}\)代替\(a_v^j\)来确保每个side information的权重都大于0,并使用\(\sum_{j=0}^n e^{a_v^j}\)对每个side information的权重做了标准化处理。
伪代码:

涉及到的结构与超参:
\(\mathcal{G}=(\mathcal{V}, \mathscr{E})\):图结构
S:side information
\(w\):每个节点的游走次数(number of walks per node)
\(l\):随机游走的序列长度(walk length)
\(k\):Skip-Gram算法窗口大小(Skip-Gram window size k)
\(\#ns\):负样本数量(正负样本比,number of negatives samples)
\(d\):embedding向量维度(embedding dimension)

实验数据#
数据稀疏度#
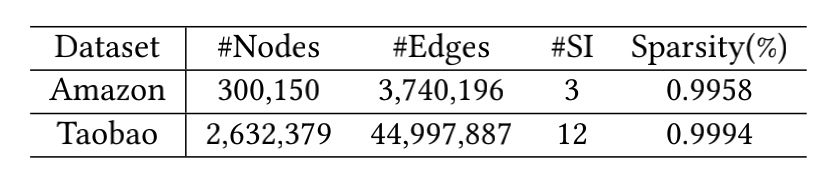
计算方式如下:
其中\(\#Edges\)表示图中边的数量,\(\#Nodes\)表示图中节点数。
离线AUC评估#
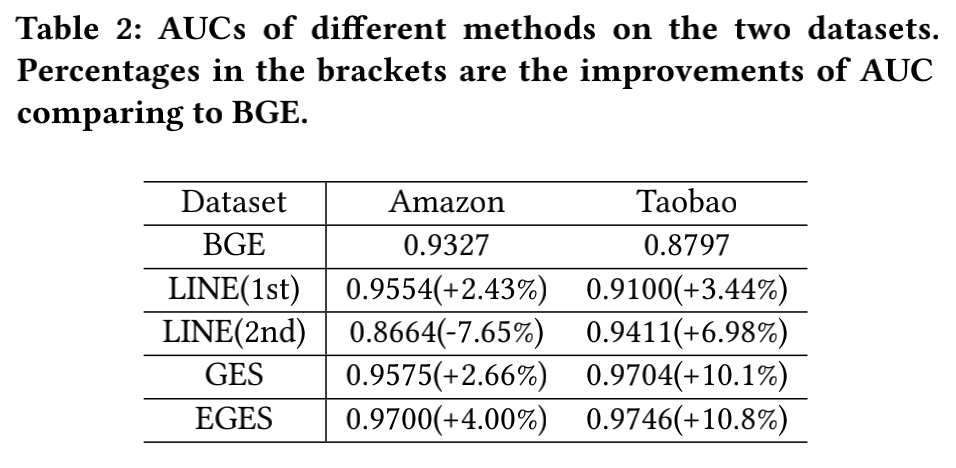
离线评估对比了BGE、LINE、GES和EGES的AUC,其中EGES在亚马逊数据集和淘宝的数据集上的表现都是最好的(关于这个评估指标个人或多或少存在一些疑问,召回阶段的模型评估离线AUC是否有实际的参考价值,比较好理解的是评估准召指标,期待与大佬交流学习~)。
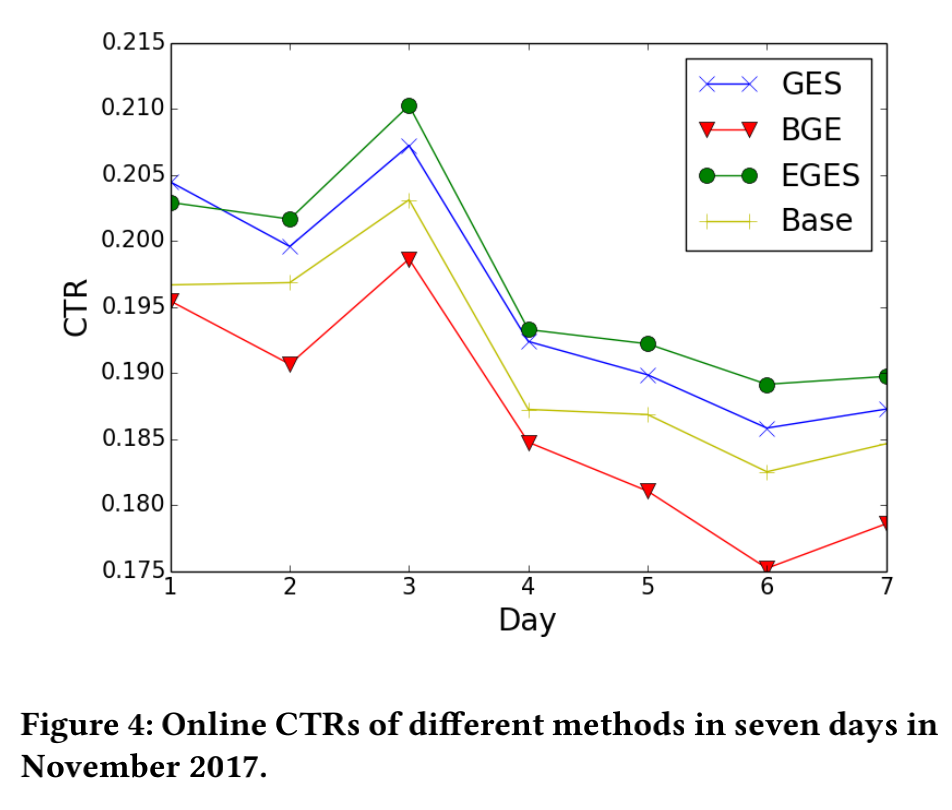
线上CTR对比#
基于淘宝真实的数据流量进行了线上的CTR对比,EGES的表现是最好的。
GraphSAGE(Transductive Learning->Inductive Learning)#
在介绍GraphSAGE之前先介绍下直推式学习(Transductive Learning)和归纳学习(Inductive Learning),二者的最大区别在于直推式学习(Transductive Learning)要求在一个确定的图中去学习顶点的embedding,无法直接泛化到在训练过程没有出现过的顶点,而归纳学习(Inductive Learning)则是要求能够利用已知顶点的embedding高效的产生未知顶点的embedding,要求对未知数据有很好的泛化能力。
GraphSAGE的核心思想是:GraphSAGE不是学习一个图上所有节点的embedding,而是学习一个为每个节点产生embedding的映射(一组aggregator functions,通过对邻居节点进行聚合产生目标节点的embedding)。
整体流程#
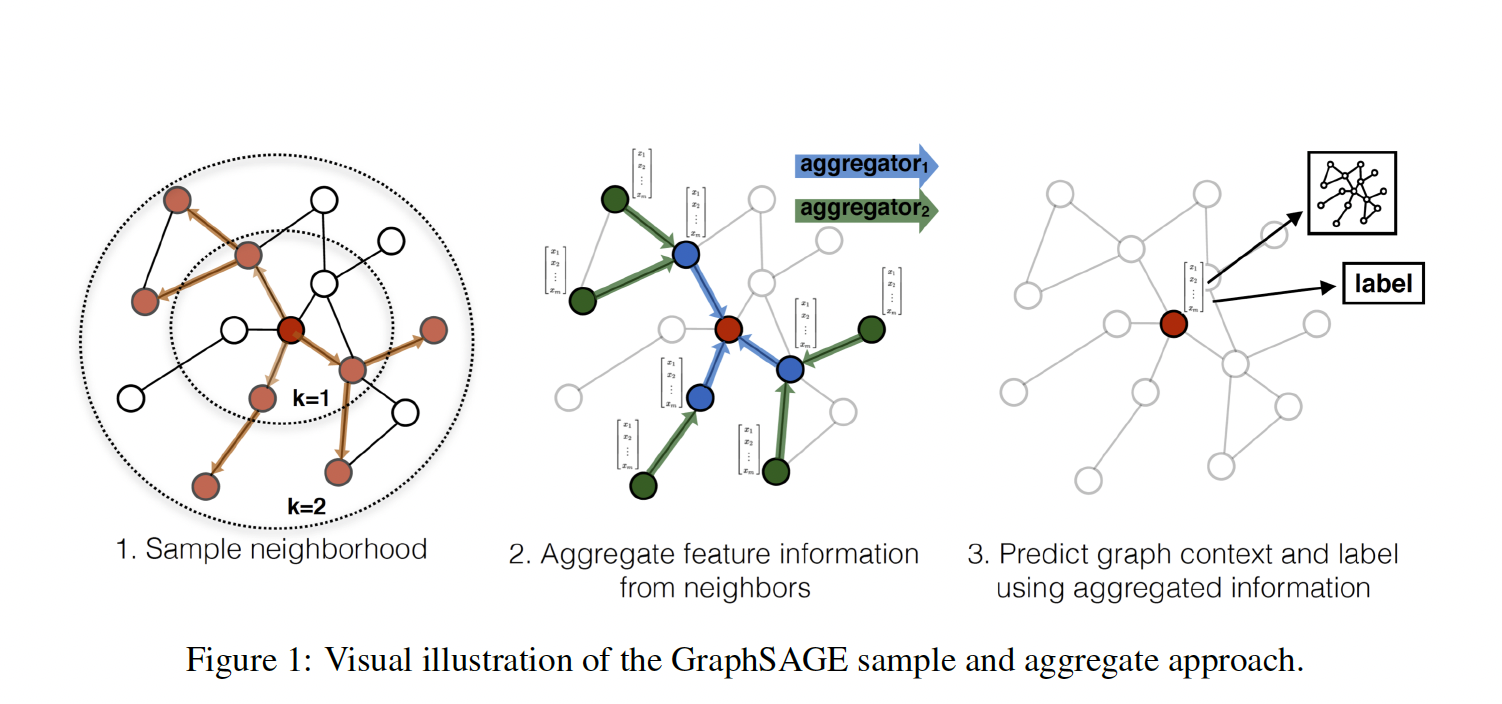
GraphSAGE的整体流程主要包含以上三步:
Sample neighborhood:对每个节点的邻居节点进行采样,为每个节点采样固定数量的邻居
Aggregate feature information from neighbors:通过聚合函数聚合邻居节点包含的信息
Predict graph context and label using aggregated information:得到图中各个顶点的向量表示
Embedding generation#
GraphSAGE的前向传播算法如下,前向传播描述了如何使用聚合函数对节点的邻居信息进行聚合,从而生成节点embedding:

其中:
\(\mathcal G(\mathcal V, \mathcal E)\)表示一个图
\(x_v\)表示节点的向量表示
depth K表示网络的层数,也代表着每个顶点能够聚合到的邻接节点的跳数
\(h_u^{k-1}\)表示在k−1层中节点\(v\)的邻居**节点\(u\)**的向量表示,\(\mathcal N(v)\)表示节点\(v\)的所有邻居节点
\(h_{\mathcal N(v)}^{k}\)表示在第k层节点\(v\)的所有邻居节点的向量表示
\(h_v^{k}\)表示在第k层节点\(v\)的向量表示
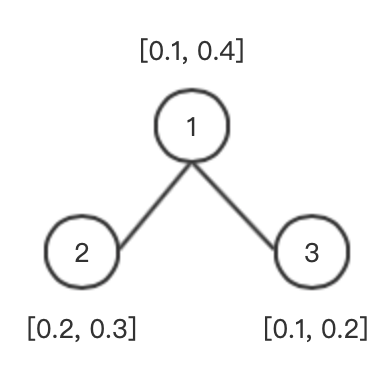
假设有一个图如下所示:
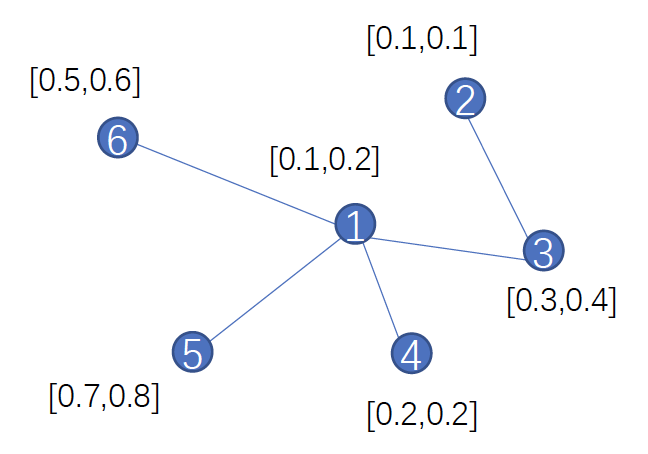
计算节点 1 的相邻节点 \(N(1) = \{ 3, 4, 5, 6 \}\)
伪代码第 4 步:\(h_{N(1)}^1 = AGGREGAGE(\{h_3^0, h_4^0, h_5^0, h_6^0\}\),假设这里使用的 AGGREGATE 方法为均值函数(mean),则 \(h_{N(1)}^1 = mean([0.3, 0.4], [0.2, 0.2], [0.7, 0.8], [0.5, 0.6]) = [0.425, 0.5] \)
伪代码第 5 步:\(h_1^1 = \sigma(W^1 \cdot CONCAT(h_1^0, h_{N(1)}^1)) = \sigma(W^1 \cdot [0.1, 0.2, 0.425, 0.5])\)
采样#
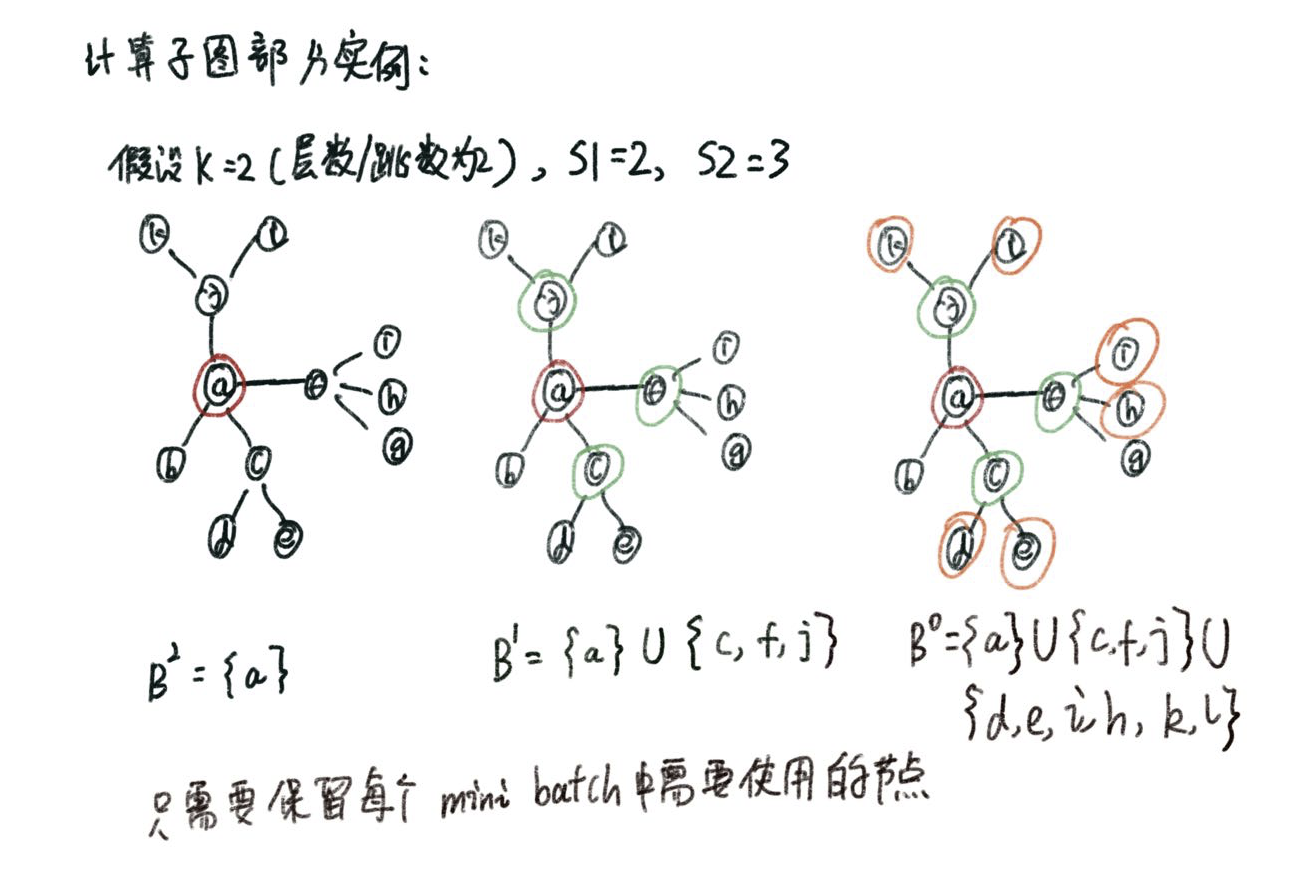
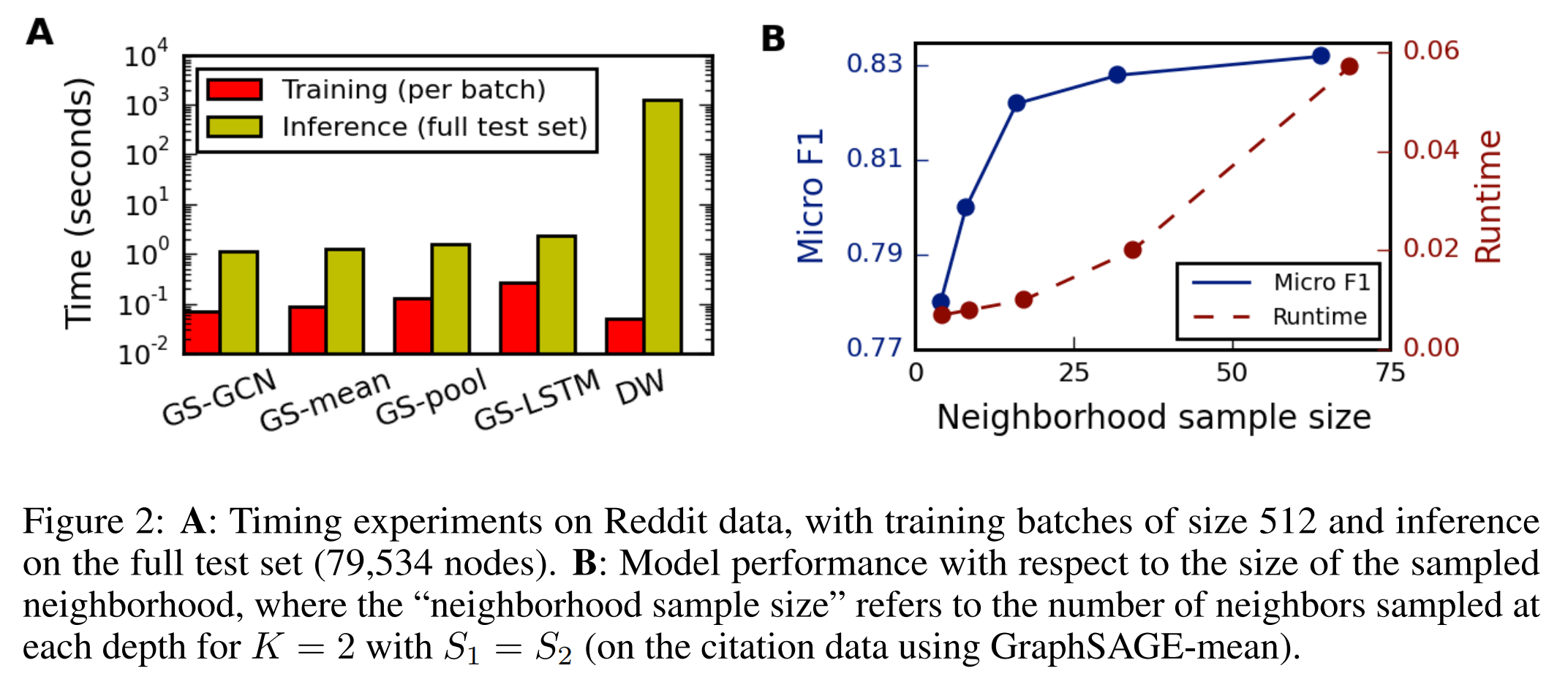
出于对计算效率的考虑,需要对每个节点的邻居节点进行采样,采样时主要包含两个要素:层数K(跳数)和每一层上每个节点要采样的数量,训练时可以认为每个batch的时空复杂度为\(\prod_{i}^{K}S_i\),实验发现,K不必取很大的值,当K=2时,以及两次扩展的邻居节点总数\(S_1 \cdot S_2\)小于等于500时,效果就很好了。
由于要对每个顶点采样一定数量的邻居节点,设需要的邻居节点数量为S,若顶点邻居节点数小于S,则采用有放回的抽样方法,直到采样出S个顶点,若顶点邻居数大于S,则采用无放回的抽样。

聚合函数#
这里主要对应红框部分。

mean aggregator#
先对邻居节点向量表示取平均,再与目标节点向量表示拼接。
convolutional aggergator#
直接对目标节点和邻居节点的向量表示取平均。
LSTM aggregator#
需要先获得邻居节点的顺序,再将邻居节点的向量表示序列作为LSTM网络的输入。
pooling aggregator#
其中max表示element-wise最大值操作,即取对应维度的最大值
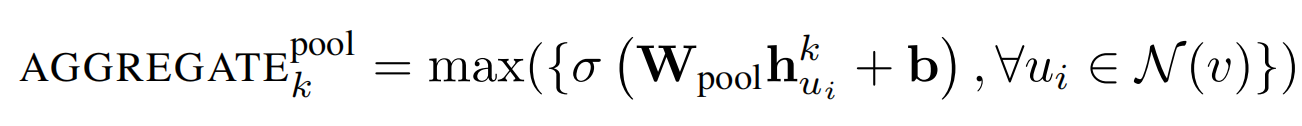
模型训练#
损失函数倾向于使得相邻节点的向量表示相似度高,互相远离的节点相似度低。
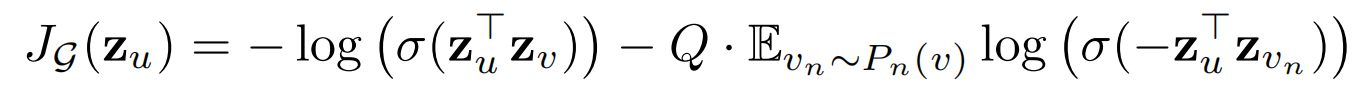
其中:
\(z_u\)表示节点\(u\)的向量表示
节点\(v\)是节点\(u\)随机游走到达的邻居
\(P_n(v)\)表示负采样概率分布
\(Q\)是负样本的数目
mini batch 版本#

假设节点 a 是当前 batch 内的一个节点,可以计算出,a 节点参与训练依赖的的节点集合为:{a, c, f, j, d, e, i, h, k, l},训练时只需要存储 a 以及训练 a 时依赖的节点,batch 内的其他节点依此类推。GraphSAGE 部分即正常的训练部分。
实验结论#
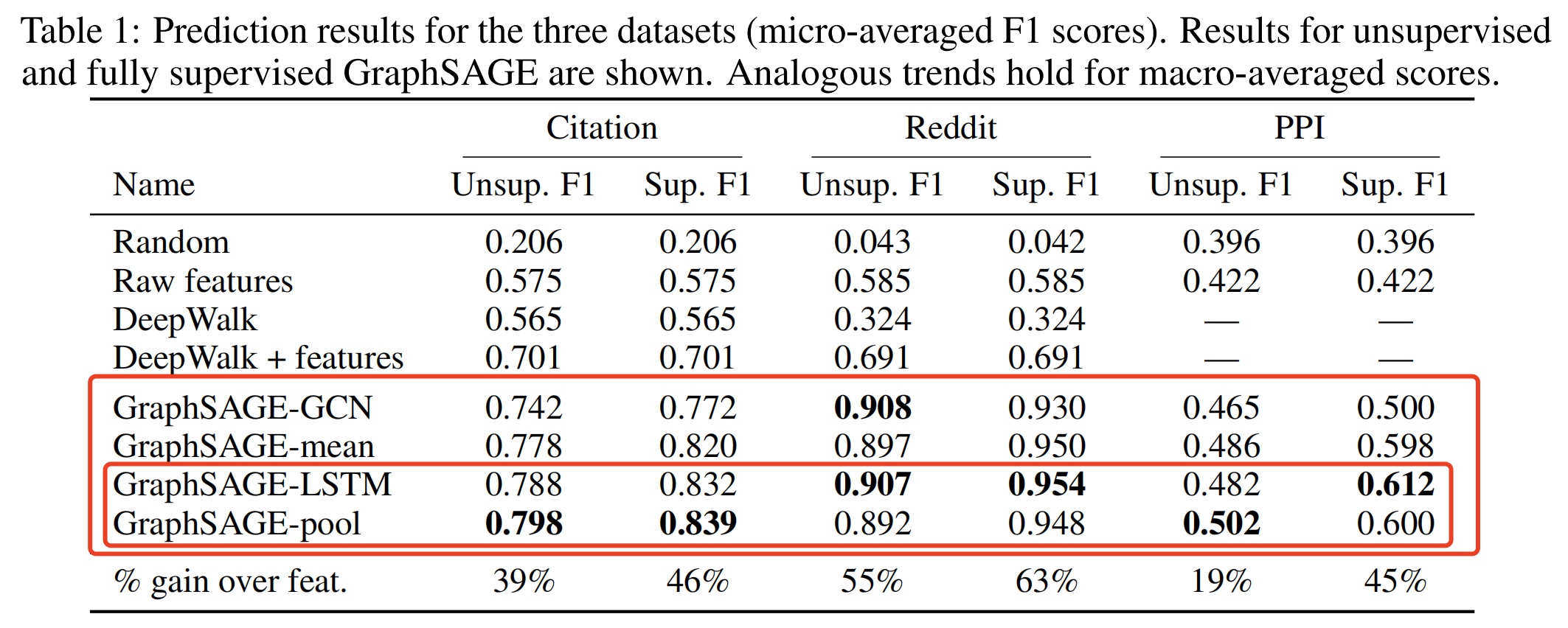
GraphSAGE相对于其他模型指标有较大幅度提升,LSTM aggregator与pooling aggregator效果较好,LSTM aggregator耗时最严重。
GAT#
推荐阅读⭐️⭐️⭐️⭐️⭐️
原文:《GRAPH ATTENTION NETWORKS》
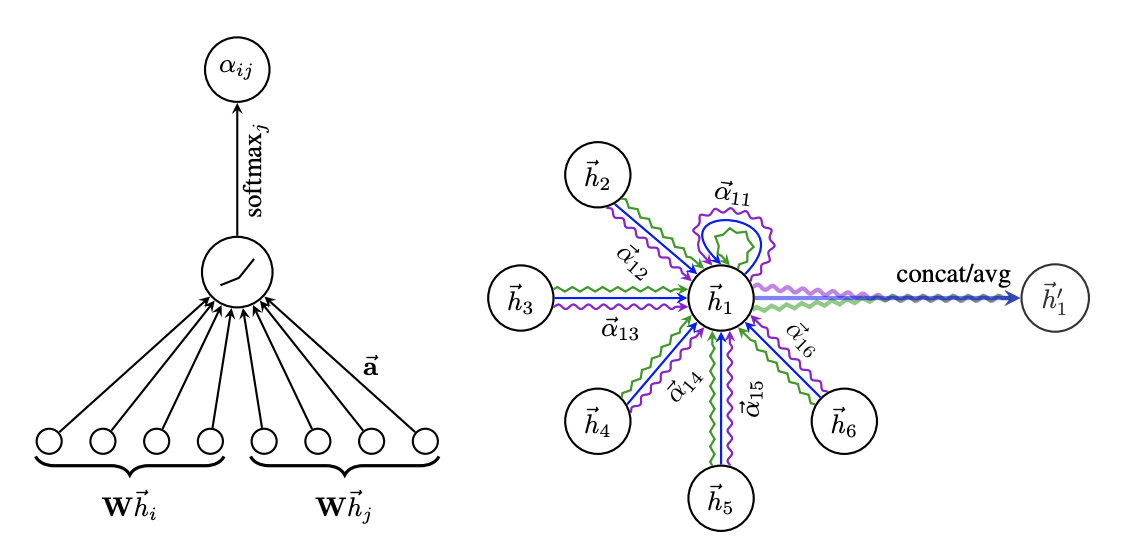
对邻居节点利用Attention机制来学习贡献度。
和所有的attention mechanism一样,GAT的计算也分为两步走:
(1)计算注意力系数:\(e_{ij} = a([Wh_i||Wh_j]),j\in \mathcal N_i\),首先一个共享参数W的线性映射对于顶点的特征进行了增维,当然这是一种常见的特征增强方法。\(||\)对于顶点\(i,j\)的变换后的特征进行了拼接(concatenate),最后\(a(\cdot)\)把拼接后的高维特征映射到一个实数上,论文中是通过single-layer feedforward neural network实现的。最后通过softmax做归一化得到注意力系数。
(2)加权求和:
根据计算好的注意力系数,把特征加权求和(aggregate)一下:\(h_{i}^{'}=\sigma(\sum_{j\in\mathcal N_i} \alpha_{ij}Wh_j)\),\(h_{i}^{'}\)就是GTA输出的对于每个顶点\(i\)的新特征(融合了邻域信息),\(\sigma(\cdot)\)是激活函数。
进一步使用multi-head的方式:\(h_{i}^{'}(K)=||_{k=1}^K \sigma(\sum_{j \in\mathcal N{i}} \alpha_{ij}^k W^{k} h_j) \)