Table of Contents
推荐系统05-多目标与多场景建模#
多场景&多目标建模简介#
多场景和多目标(任务)的区别?#
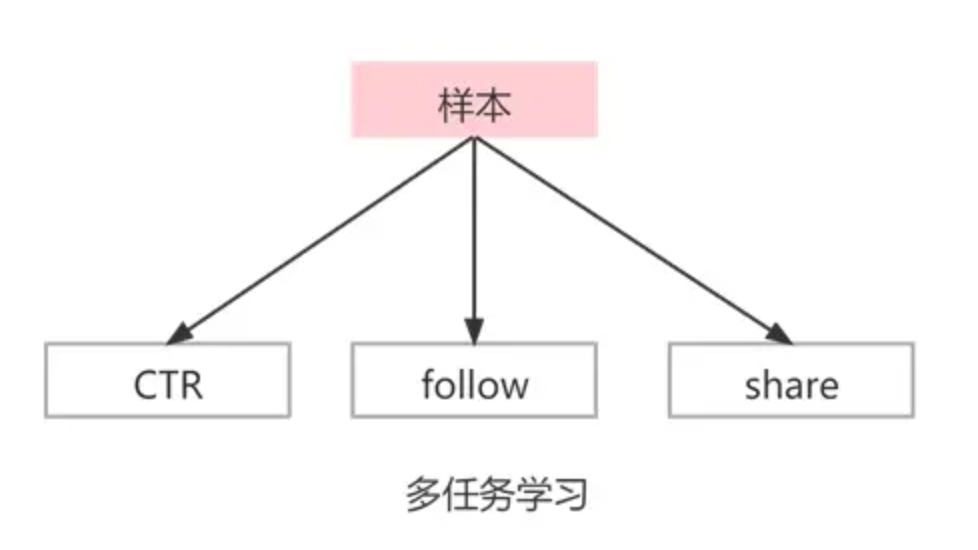
多目标学习:解决相同场景/分布下的不同任务,如推荐场景下的多任务学习通常是单个样本对于 CTR,CVR 等目标同时预估。
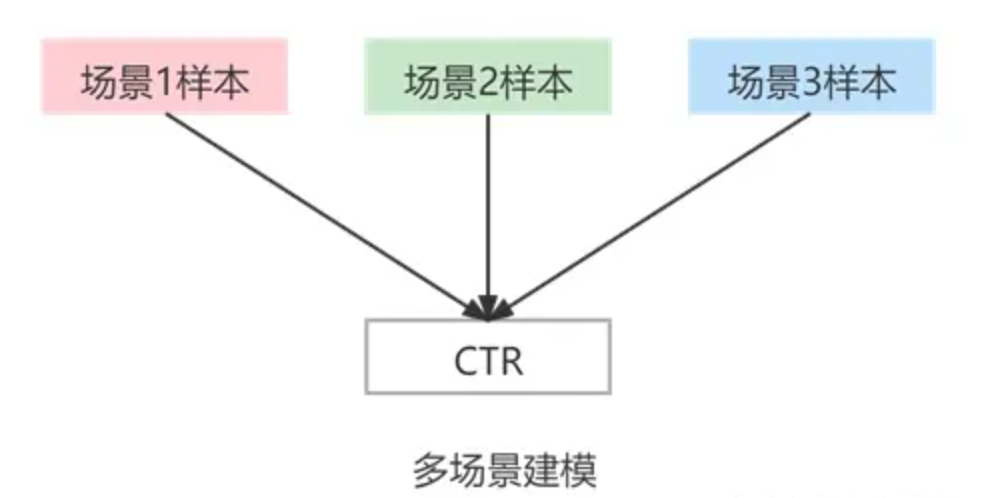
多场景建模:解决不同场景/分布下的相同任务,如对不同场景样本预估相同的 CTR 目标。
多场景建模的核心?#
如果每个场景独立建模,那每个场景都要维护一个模型,成本高,同时小场景样本少,也难以学好。如果将所有样本混在一起学习一个适用所有场景的共享模型,那每个场景间的差异就体现不出来,容易出现大场景主导小场景的问题(总结:场景数多且存在长尾问题、不同场景样本分布差异大、人力和资源的限制)。
什么情况适用多场景建模?#
不同用户群体(新老用户/按用户画像拆分)、同一APP的不同频道、不同客户端、不同厂商等,都可以看作不同场景。不同场景的用户分布存在差异,同一用户在不同场景下的行为也存在差异。
多场景建模的形式化定义?#
传统单场景 CTR 模型是对于样本 x 进行预估,数据从单个场景中采样得到,这背后的假设是样本独立同分布。但在多场景建模中,模型对于样本 x, p 进行预估,其中 p 是 domain indicator。在多场景建模中,数据是从多个相关但分布不同的场景中采样得到,样本只在场景内独立同分布。
多目标与多场景建模的示意图#
多场景建模的思路#
场景相关特征作为输入#
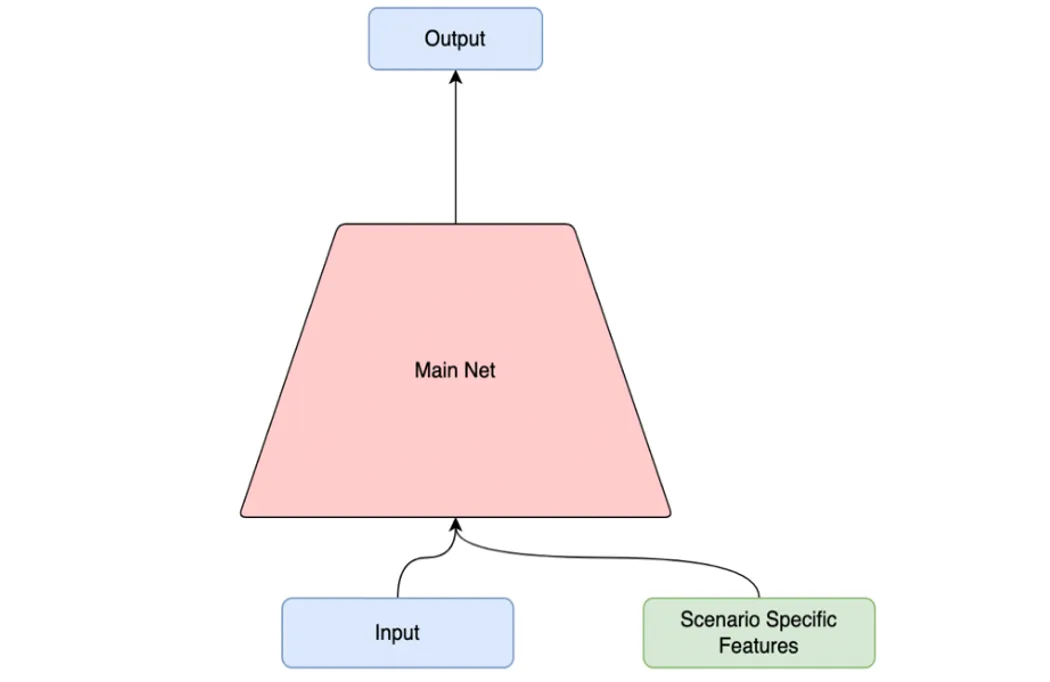
最简单的方法是把场景相关特征作为输入,场景特征维度一般较少,随着网络深度的增加,场景特征对最终预测结果影响有限。
将场景看作bias,构建辅助子网络#
将场景看作bias,构建辅助子网络,在输出层直接与主网络结果相加或相乘,这种方式能让场景特征直接影响到最终结果,但对主网络中间层影响有限。
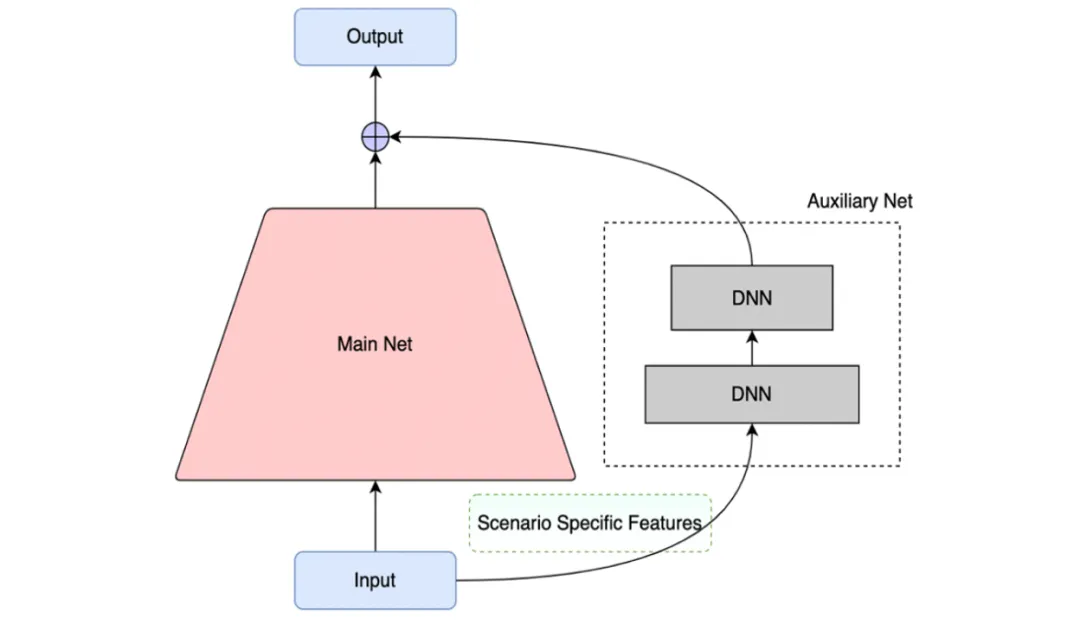
动态权重(经典代表:PPNET)#
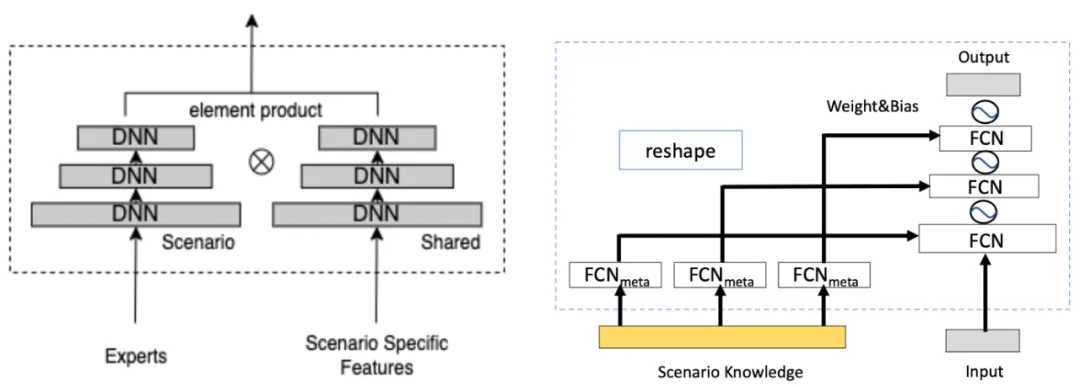
动态权重可以看作一种门控机制,以场景特征作为输入,通过多层DNN(左图)或者多组DNN(右图),生成与主网络每层维度相同的向量,然后与主网络中间层特征向量相乘,把场景信息融入主网络中间层。
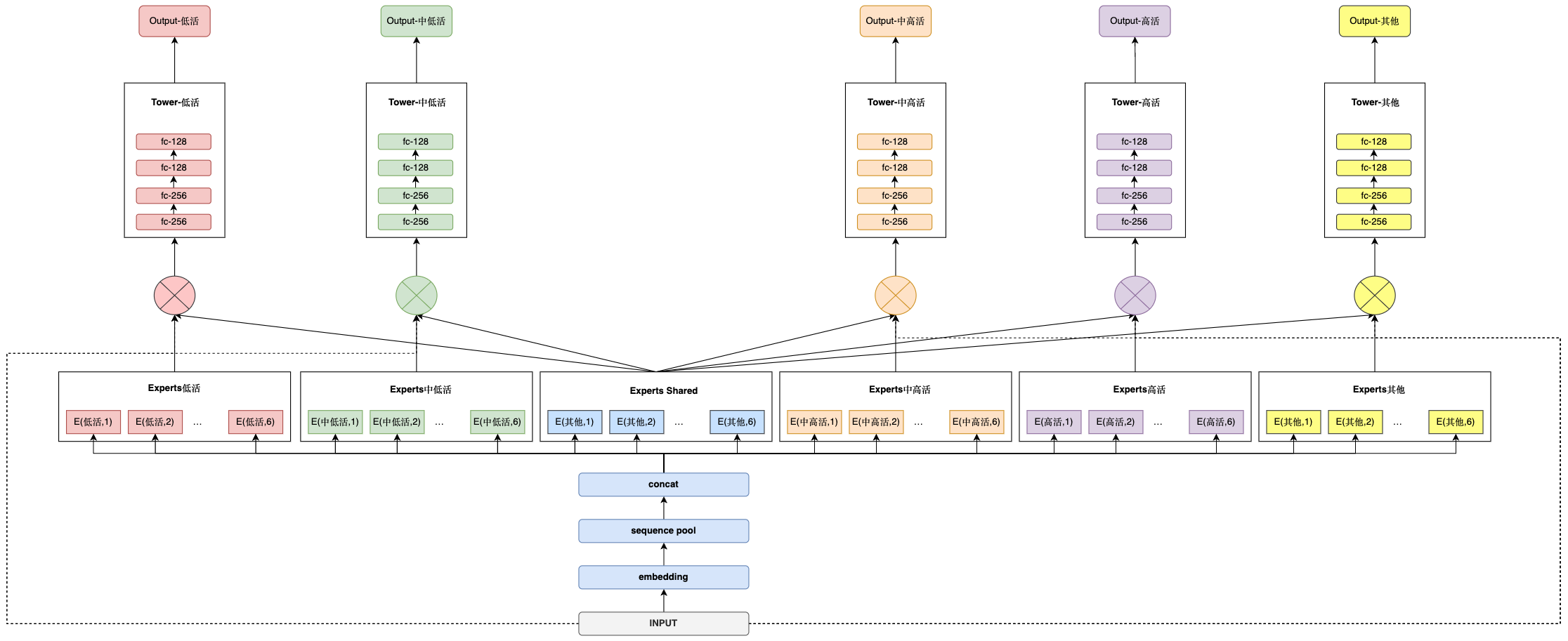
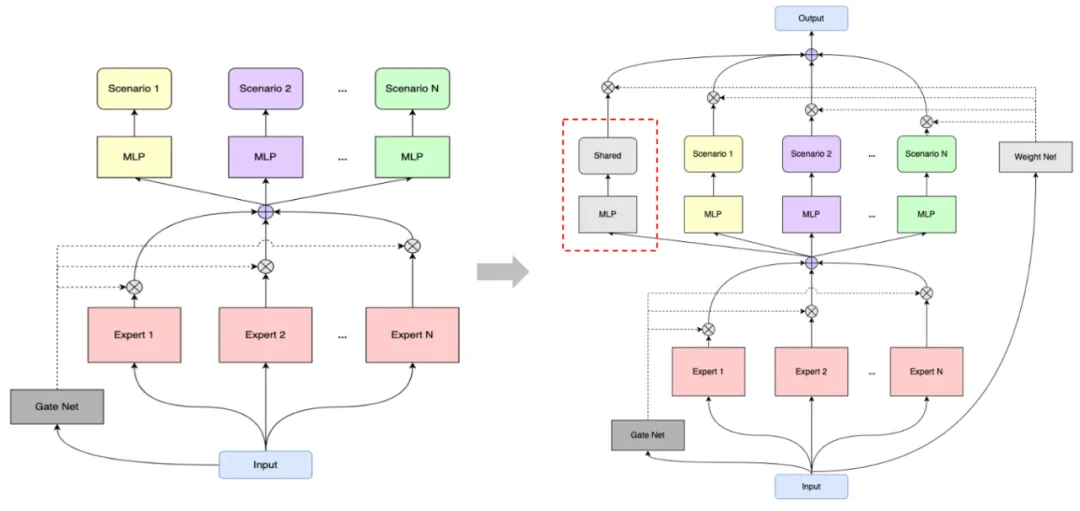
拆塔#
每个场景对应一个塔,有各自独立的子空间,进一步提升了各场景个性化程度。如下图,相比原始的MMOE网络,可以增加共享塔,用于学习各场景之间的共性信息,缓解小场景学不好问题,通过权重子网络,学习 得到共享塔和特定场景塔融合权重,对场景间共性信息和特定场景信息融合。
多场景建模实践#
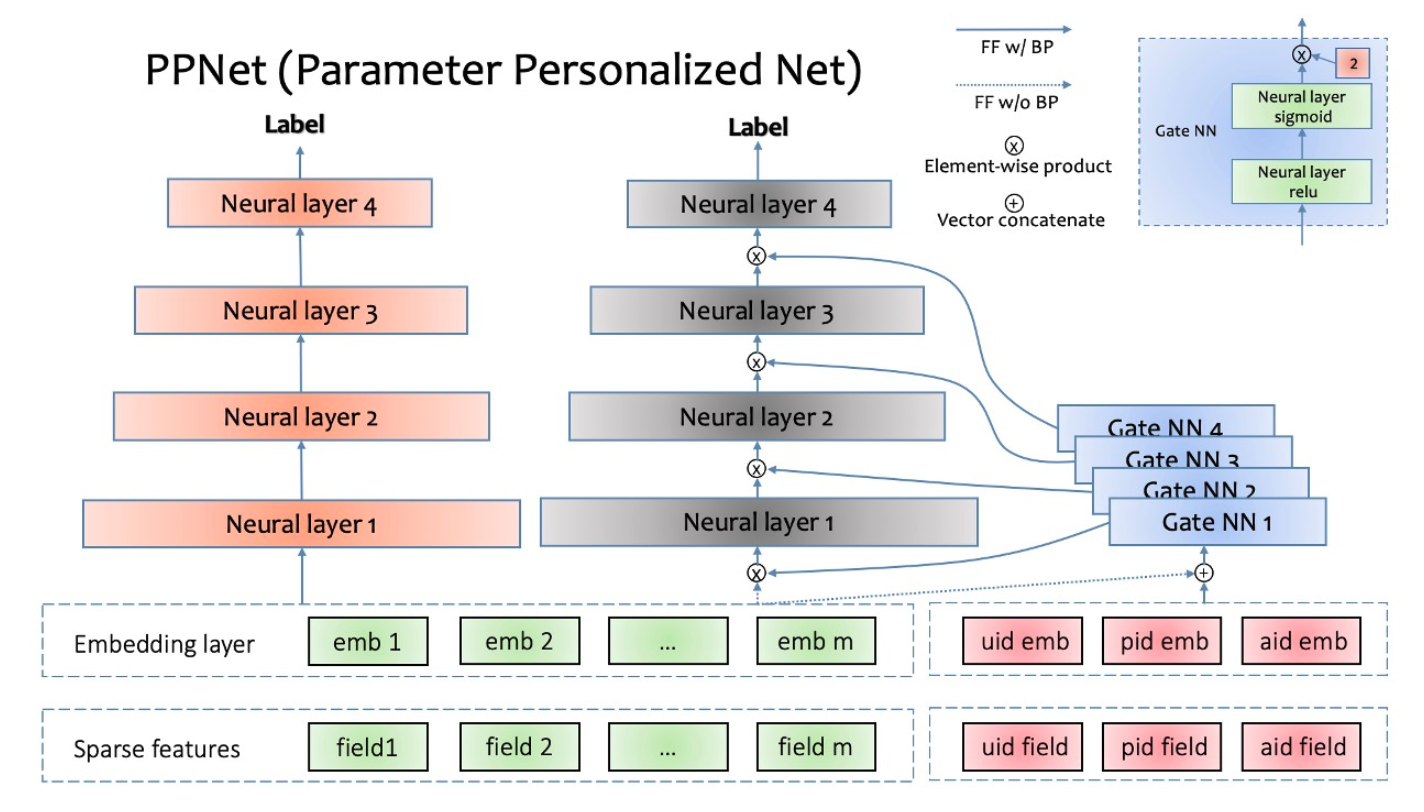
PPNet(快手)#
推荐阅读⭐️⭐️⭐️⭐️⭐️
引入门控机制,根据用户人群特征,学习门控参数,提高网络参数个性化和人群化。
PPNet(Parameter Personalized Net),增加 DNN 网络参数个性化。uid,pid,aid 分别表示 user id,photo id,author id。左侧的所有特征的 embedding 会同这 3 个 id 特征的 embedding 拼接到一起作为所有 Gate NN 的输入,左侧所有特征的 embedding 并不接受 Gate NN 的反传梯度,这样操作的目的是减少 Gate NN 对现有特征 embedding 收敛产生的影响。
GateNN的数量同左侧神经网络的层数一致,GateNN的输出与DNN每一层的输入做element-wise product,GateNN是一个两层的神经网络,其中第二层的激活函数是2 * sigmoid,默认值是1,左侧所有特征的embedding不接受GateNN的反传梯度。
模型拆塔(好看视频)#
推荐系统精排模型经常存在训练样本不均衡现象,eg:尾部5%用户仅提供了2%样本,而头部3%用户贡献了系统60%的样本,模型权重被少量高频重度用户主导,不利于低活用户推荐效果。可以通过用户分群多塔训练方式优化模型预估精度,并结合精排排序机制迭代,整体改善各活跃度用户的推荐体验。
以下模型为三塔模型,预估用户单次播放短点率、完成率与完播率。本次迭代将完成率目标训练方式升级为finetune network,进而区分不同活跃度用户群体,提升预估精度。
其中,finetune network结构借鉴迁移学习的方式,使用一个主塔训练全量样本,4个分塔训练不同活跃度的用户样本,并用于线上预估对应活跃度分群用户的完成率。主塔天级别同步小模型参数至各个分塔,保证各个分塔学习到全量用户的信号。
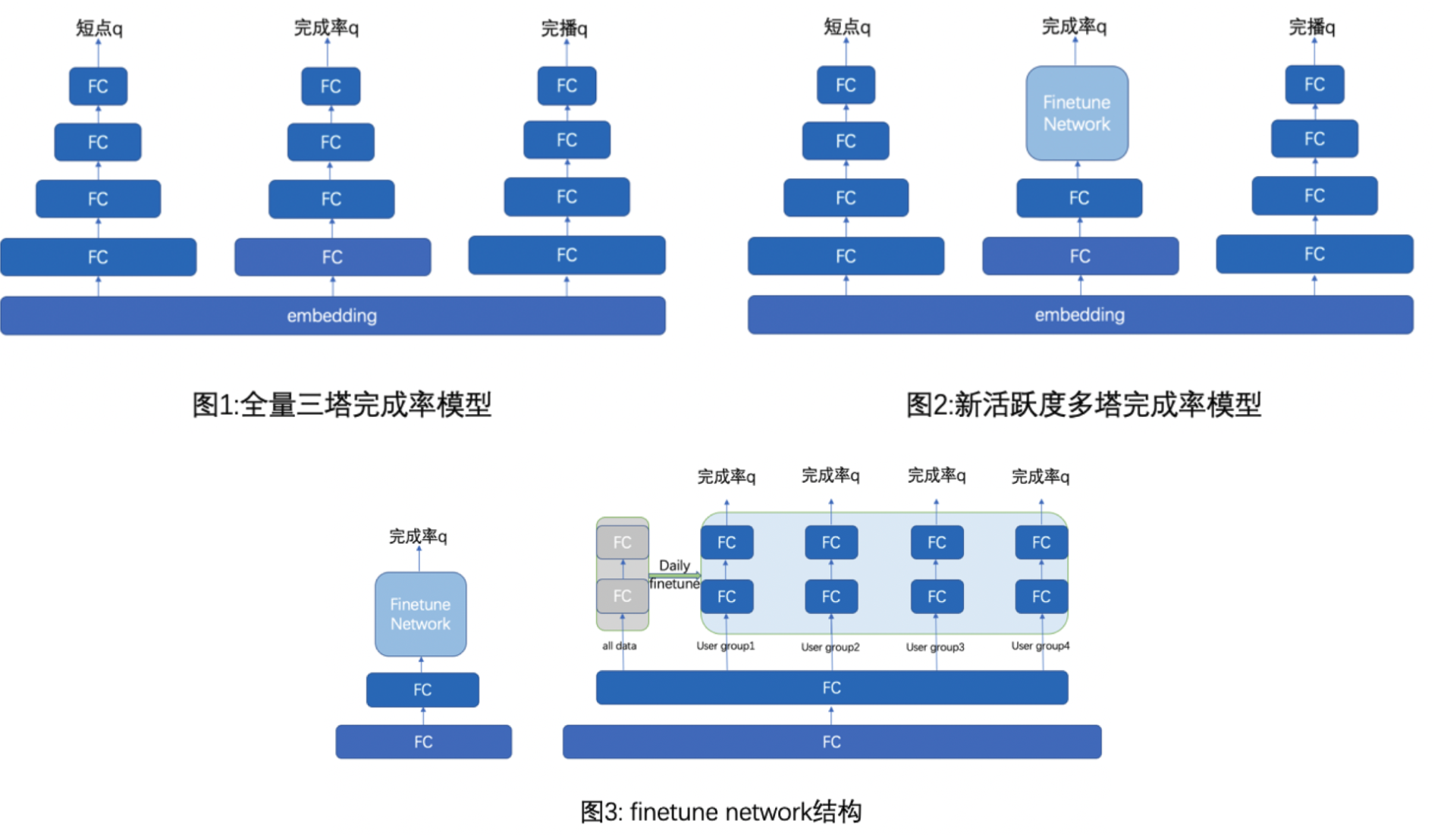
多场景建模-快手实践(需要进一步研究下)#
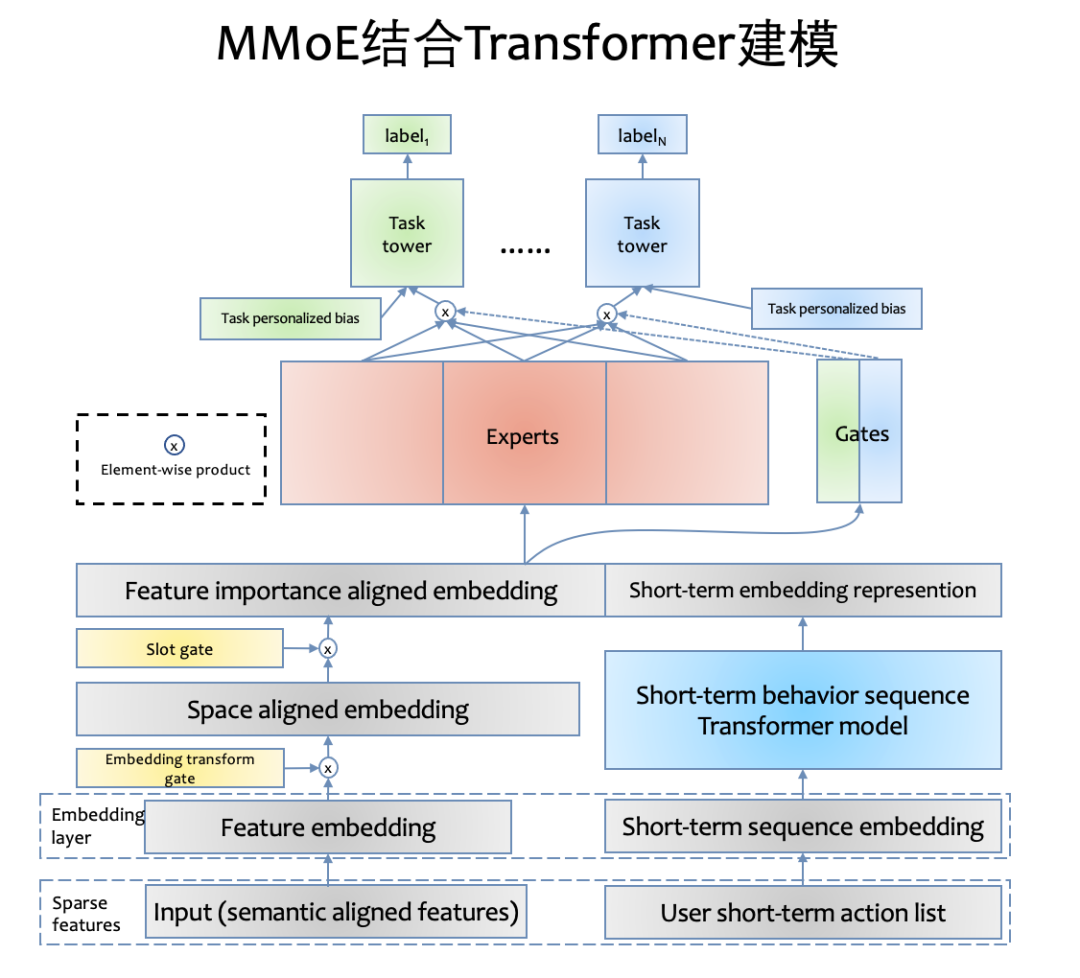
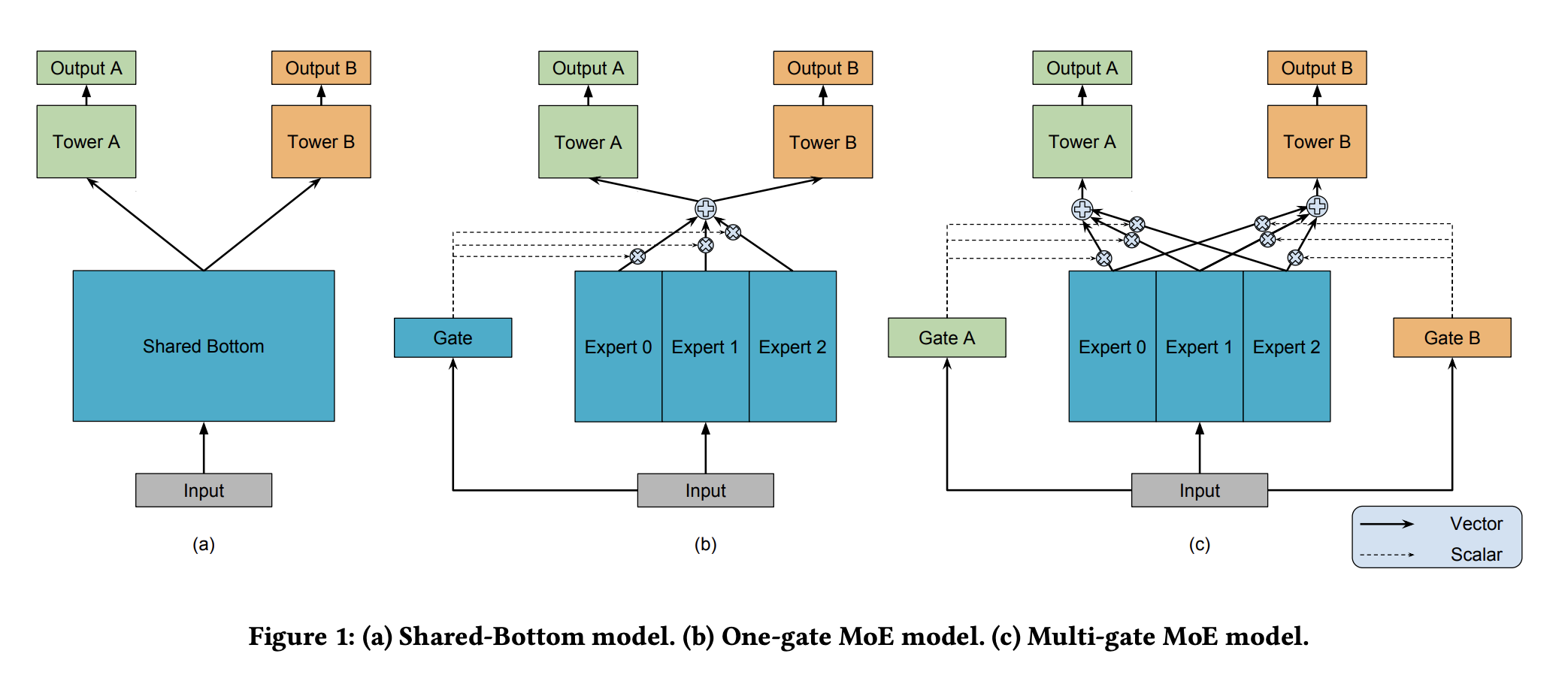
MMoE 是 Google 提出的一种经典多任务学习算法,其核心思想是把 shared-bottom 网络替换为 Expert 层,通过多个门控网络在多个专家网络上上分别针对每个目标学习不同专家网络权重进行融合表征,在此融合表征的基础上通过 task 网络学习每个任务。
特征统一 & embedding transform layer & slot-gating-layer#
推荐团队改造了 MMoE 算法并设计了一套新的多任务学习算法框架。具体体现在:
(1)在特征层⾯,进⾏了语义统⼀,修正在单双列业务中语义不⼀致特征;
(2)在 Embedding 层⾯,进⾏了空间重新映射,设计了 embedding transform layer,直接学习单双列 embedding 映射关系,帮助单双列 embedding 映射到统⼀空间分布
(3)在特征重要性层⾯,设计了 slot-gating layer,为不同业务做特征重要性选择
通过以上 3 点的改动,模型将输入层的 embedding 表示从特征语义,embedding 在不同业务分布,特征在不同业务重要性三个层面做了归一化和正则化,重新映射到统一的特征表征空间,使得 MMoE 网络在此空间上更好的捕捉多个任务之间后验概率分布关系。
transformer短期行为建模#
(1)快手推荐团队使用用户的视频播放历史作为行为序列。候选的序列有:⽤⼾⻓播历史序列、短播历史序列、用户点击历史序列等,此类列表详尽地记录了用户观看视频 id、作者 id、视频时长、视频 tag、视频观看时长、视频观看时间等内容,完整描述用户的观看历史。
(2)其次,对视频观看距今时间做 log 变换代替 position embedding。在快手的推荐场景下,用户短期的观看行为跟当次预估更相关,长时间观看行为更多体现用户的多兴趣分布,使用 log 变换更能体现这种相关性。
(3)替换 multi-head self-attention 为 multi-head target attention,并且使用当前 embedding 层的 输入作为 query。这样设计的目的有两点,首先当前用户特征,预估视频特征和 context 特征比单独的用户 行为序列提供更多信息。其次可以简化计算量,从 O(d*n*n*h)变换为 O(d*n*h + e*d),其中 d 为 attention 的维度,n 为 list 长度,h 为 head 个数,e*d 表征的是 embedding 层维度变换为 attention 维 度所需的复杂度。
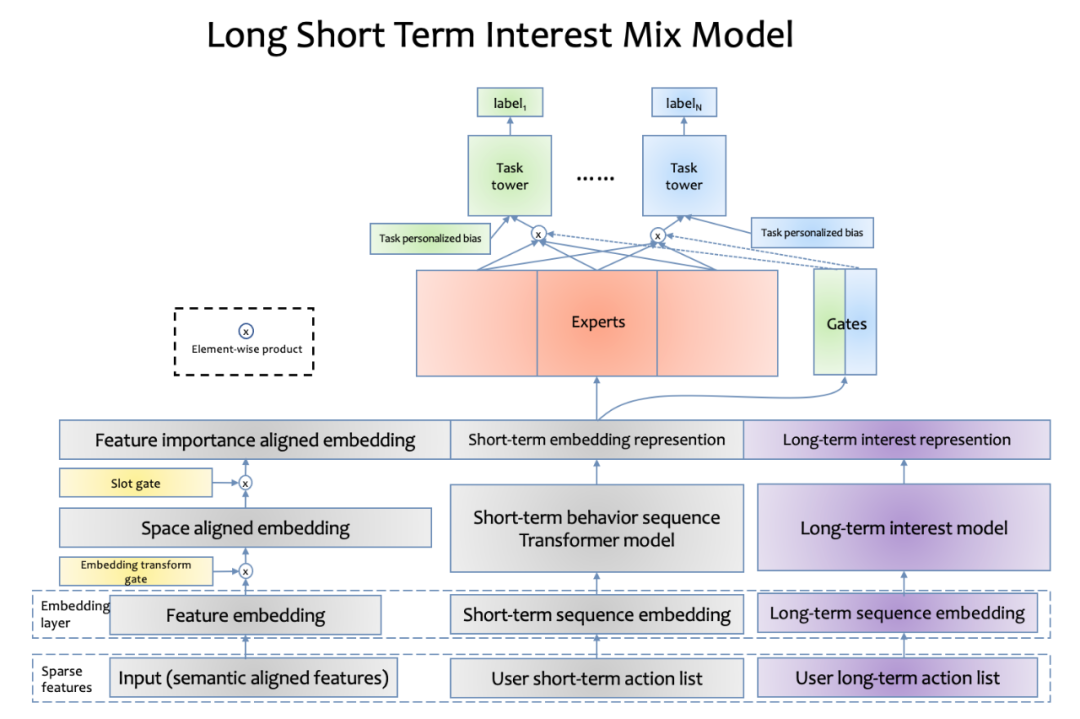
transformer长期行为建模#
短期建模的问题:长期以来,快手的精排模型都比较偏向于使用用户最近的行为。上面已经说到,通过采用 transformer 和 MMoE 模型,快手的精排模型对用户的短期兴趣进行了精确的建模,取得了非常大的收益。之前的模型里,采用了用户最近几十个历史行为进行建模。由于短视频行业的特点,最近几十个历史行为通常只能表示用户很短一段时间内的兴趣。这就造成了模型过度依赖用户的短期行为,而导致了对用户中长期兴趣建模的缺失。
长期建模的收益:针对快手的业务特点,快手推荐团队对于用户长期兴趣也进行了建模,使得模型能对于用户长期的历史记录 都有感知能力。快手推荐团队发现,将用户的交互历史序列(播放、点赞、关注、转发等)扩长之后,模型 能够更好的捕捉到一些潜在的用户兴趣,即使此类行为相对稀疏。针对该特点,推荐团队在之前的模型基础 上设计并改进了用户超长期兴趣建模模块,能够对用户几个月到一年的行为进行全面的建模,用户行为序列 长度能达到万级。此模型已经在全量业务推全并且取得了巨大的线上收益。
多目标建模实践#
多目标建模-MMOE#
MMOE是MOE的改进,相对于 MOE的结构中所有任务共享一个门控网络,MMOE的结构优化为每个任务都单独使用一个门控网络。这样的改进可以针对不同任务得到不同的 Experts 权重,从而实现对 Experts 的选择性利用,不同任务对应的门控网络可以学习到不同的Experts 组合模式,因此模型更容易捕捉到子任务间的相关性和差异性。
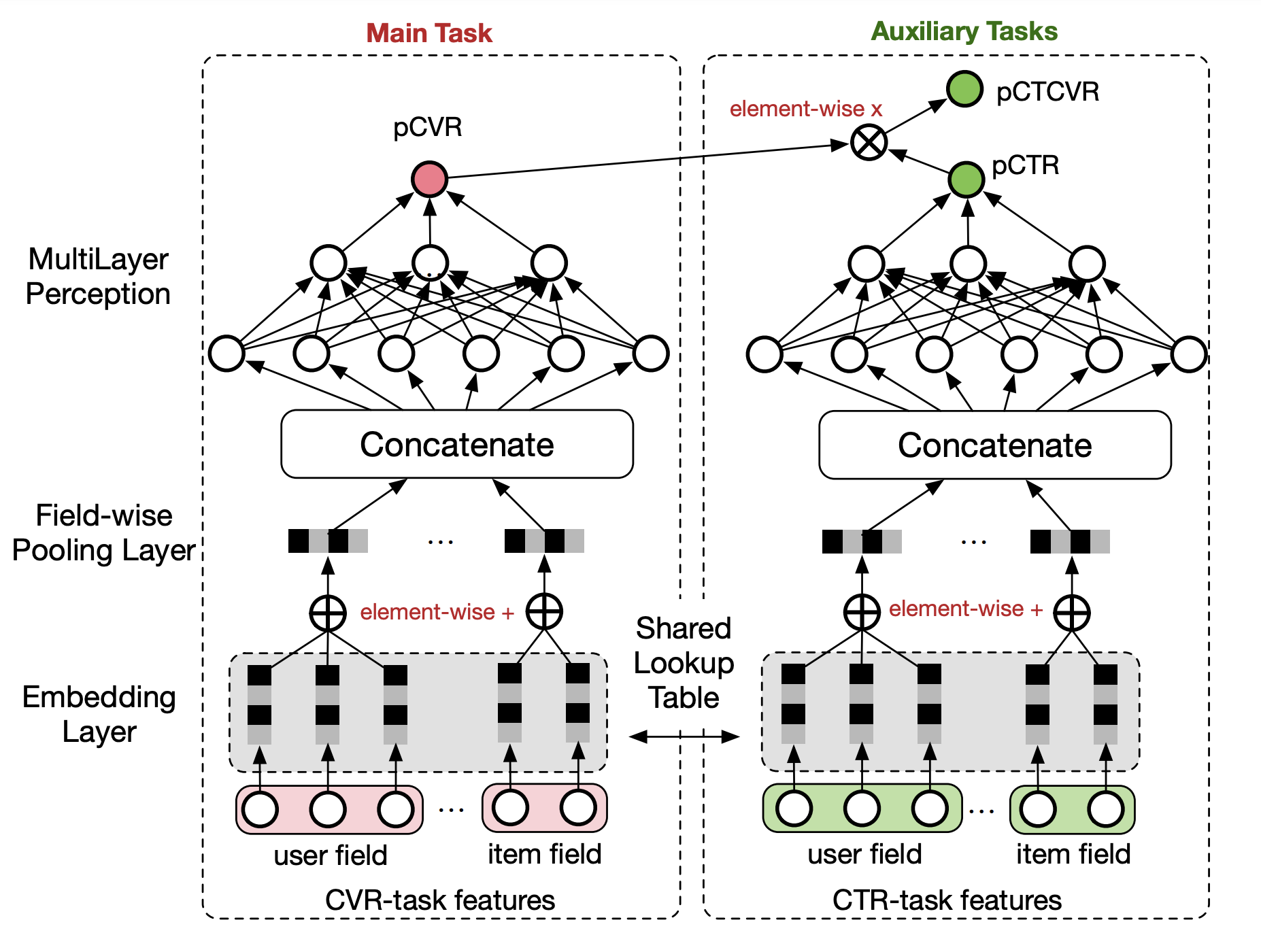
多目标建模-ESMM(ctr & cvr)#
ESMM(Entire Space Multi-Task Model)是针对任务依赖而提出,比如电商推荐中的多目标预估经常是ctr和cvr,其中转换这个行为只有在点击发生后才会发生。cvr任务在训练时只能利用点击后的样本,而预测时,是在整个样本空间,这样导致训练和预测样本分布不一致,即样本选择性偏差。同时点击样本只占整个样本空间的很小比例,比如在新闻推荐中,点击率通常只有不到10%,即样本稀疏性问题。
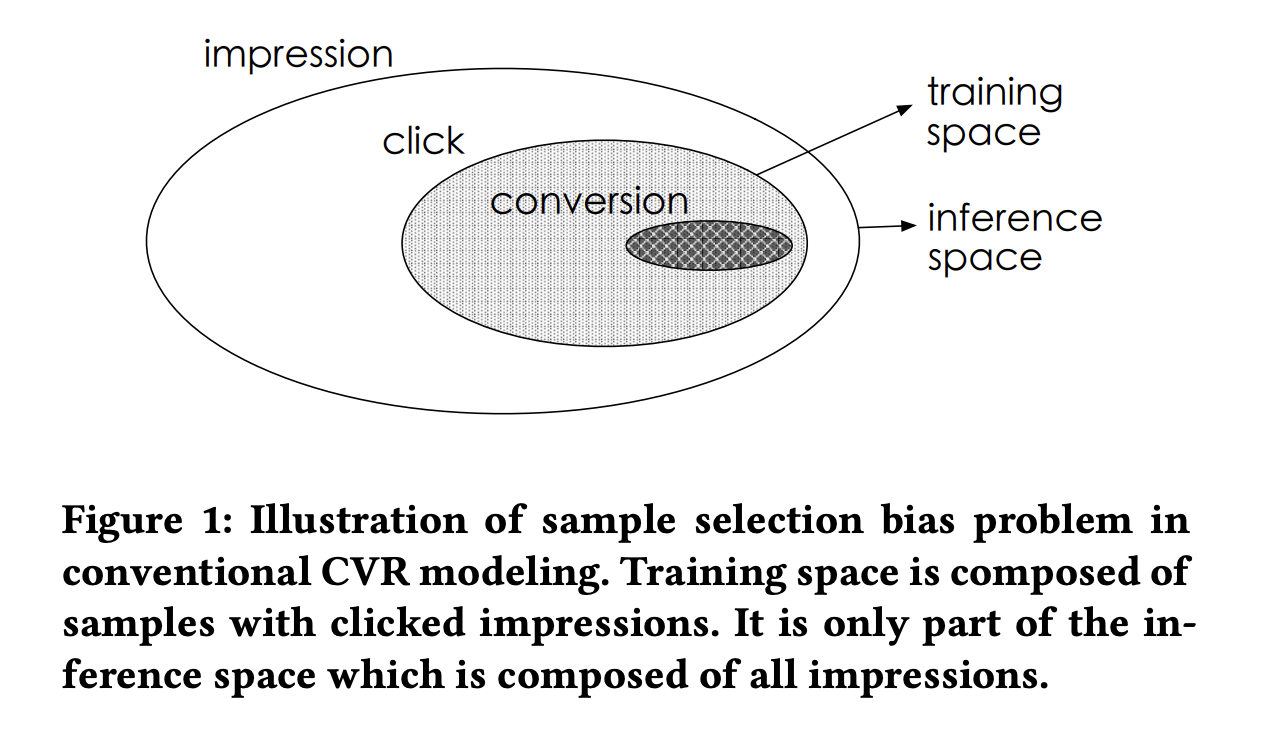
为了解决这个问题,ESMM提出了转化公式:
ESMM引入了pctr和pctcvr两个辅助任务,训练时,loss为两者相加:

网络结构为:
多目标建模-PLE#
推荐阅读⭐️⭐️⭐️⭐️⭐️
腾讯的PLE(Progressive Layered Extraction)模型,PLE相对于前面的MMOE和ESMM,主要解决以下问题:多任务学习中往往存在跷跷板现象,也就是说,多任务学习相对于多个单任务学习的模型,往往能够提升一部分任务的效果,同时牺牲另外部分任务的效果。即使通过MMoE这种方式减轻负迁移现象,跷跷板现象仍然是广泛存在的。
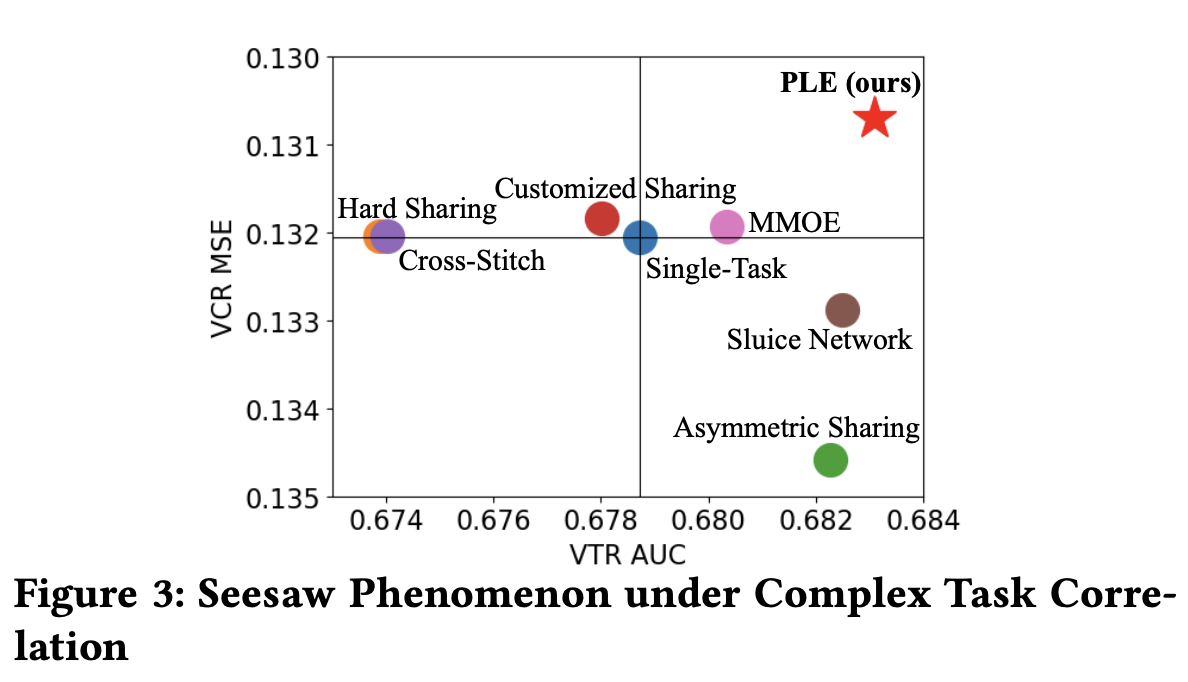
前面的MMOE模型存在以下两方面的缺点:
(1)MMOE中所有的Expert是被所有任务所共享的,这可能无法捕捉到任务之间更复杂的关系,从而给部分任务带来一定的噪声
(2)不同的Expert之间没有交互,联合优化的效果有所折扣
PLE针对上面第一个问题,每个任务有独立的Expert,同时保留了共享的Expert。

针对上面的第二个问题,通过堆叠的方式考虑不同Expert之间的交互。
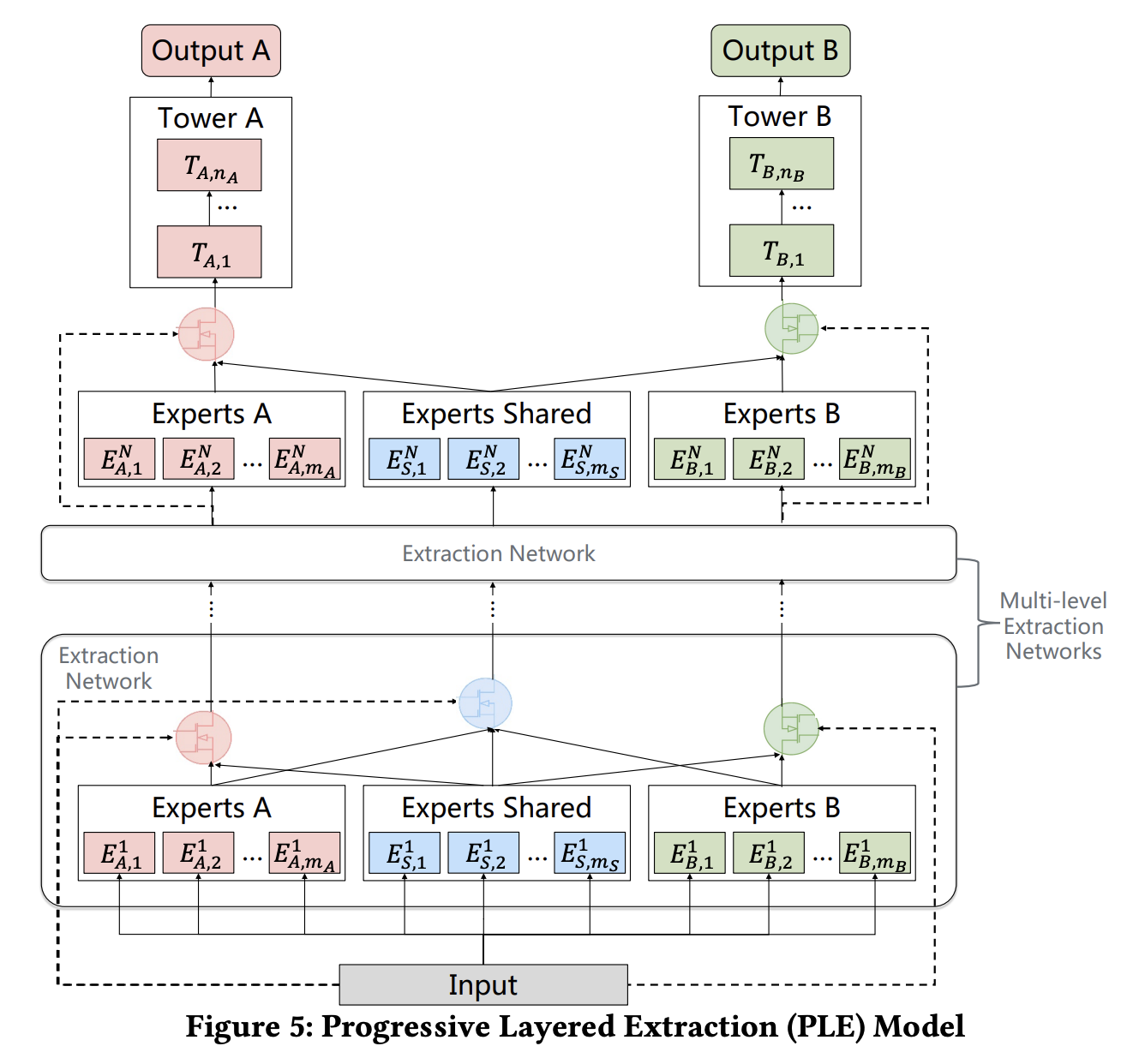
具体实例: