Table of Contents
推荐系统03-双塔模型优化思路#
DSSM#
DSSM双塔模型,因为效果不错并且对工业界十分友好,被各大厂广泛应用于推荐系统中,DSSM双塔模型是推荐领域中不得不会的重要模型。
DSSM(Deep Structured Semantic Models)也叫深度语义匹配模型,最早是微软发表的一篇应用于NLP领域中计算语义相似度任务的文章。模型原理很简单:获取搜索引擎中的用户搜索query和doc的海量曝光和点击日志数据,训练阶段分别用复杂的深度学习网络构建query侧特征的query embedding和doc侧特征的doc embedding,线上infer时通过计算两个语义向量的cos距离来表示语义相似度,最终获得语义相似模型。这个模型既可以获得语句的低维语义向量表达sentence embedding,还可以预测两句话的语义相似度。
具体模型结构如下图所示:
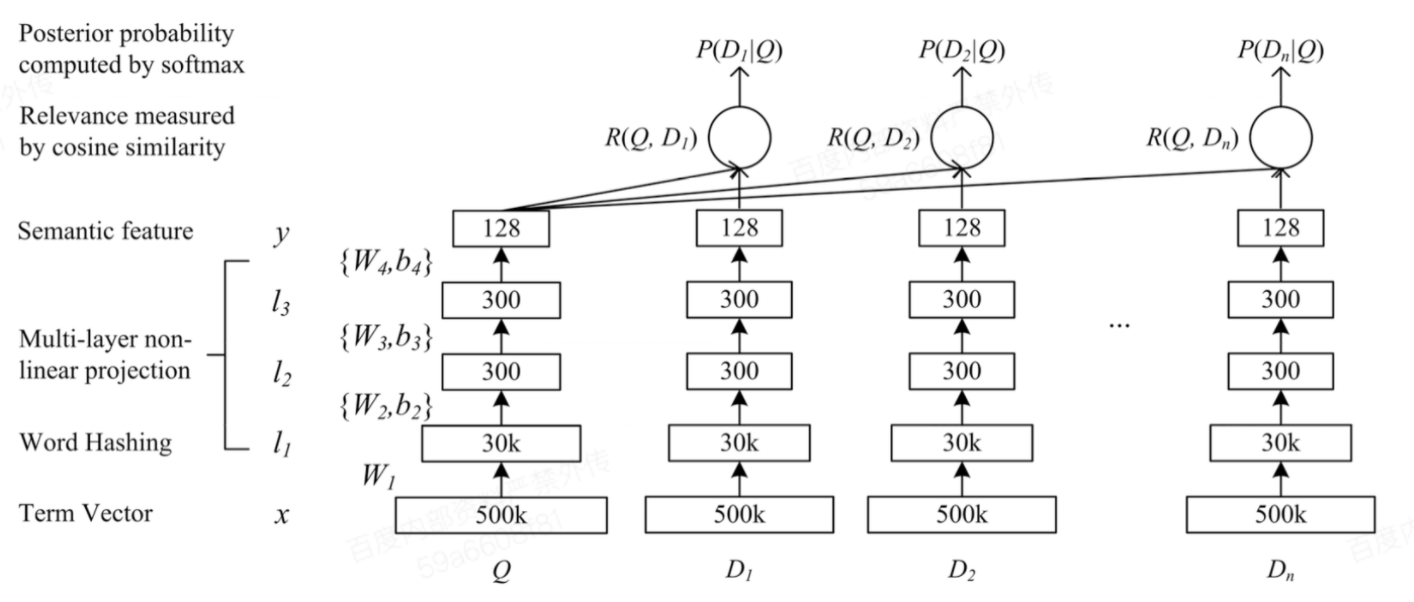
原始DSSM模型是针对英文的,做数据转换的时候使用了一个Word Hashing的小技巧,Word Hashing基于n-gram,比如一个单词good,使用Word Hashing技术进行拆分,首先在其两端补充标记符“#”,假设n=3,则“#good#”可以表示为:#go、goo、ood、od#。然后使用“#go、goo、ood、od#”来表示单词good,这样的话有2个好处:首先是压缩空间,500k个词的one-hot向量空间可以压缩为一个30k的向量空间,其次是增强泛化能力。之后使用BOW把所有词的30k向量加起来,表示Q或者D。然后加上几层DNN网络,最终变成一个128维的向量。最后计算128维向量之间的相似度(cosine距离),就表示Q和D的相似度。
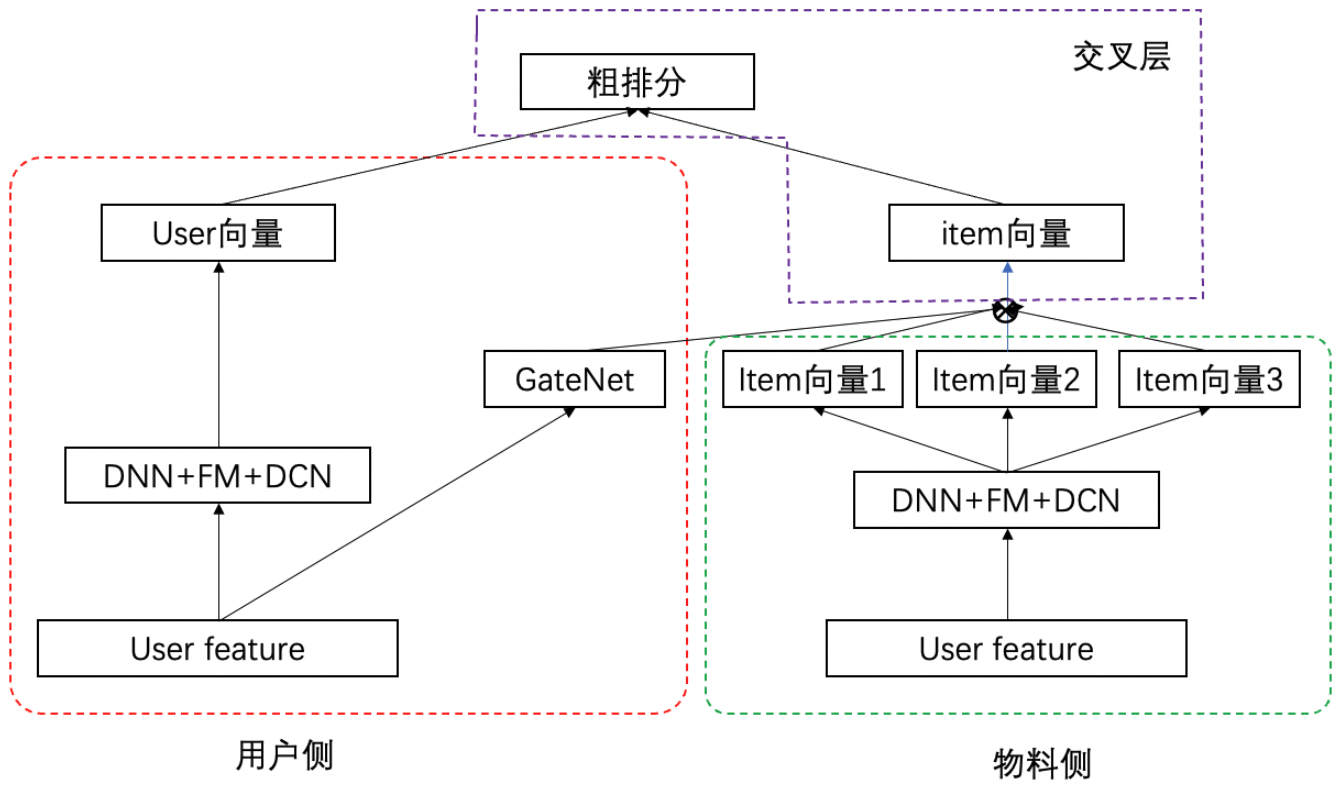
GateNN + 多物料向量#
物料侧特征粒度较粗的情况下,再叠加上头部效应的影响,物料侧生成适合所有人群的向量,存在一定局限性,可以将物料侧升级为多塔模型,用户侧生成门控(类似MMoE),不同人群选择不同物料向量,线上计算:
物料侧向量更新和现在基线一致,多个向量直接拼接成一个向量
用户侧+交叉层:统一封装到用户侧模型,交叉时通过reshape把物料向量恢复到多个,分别与用户向量交叉计算
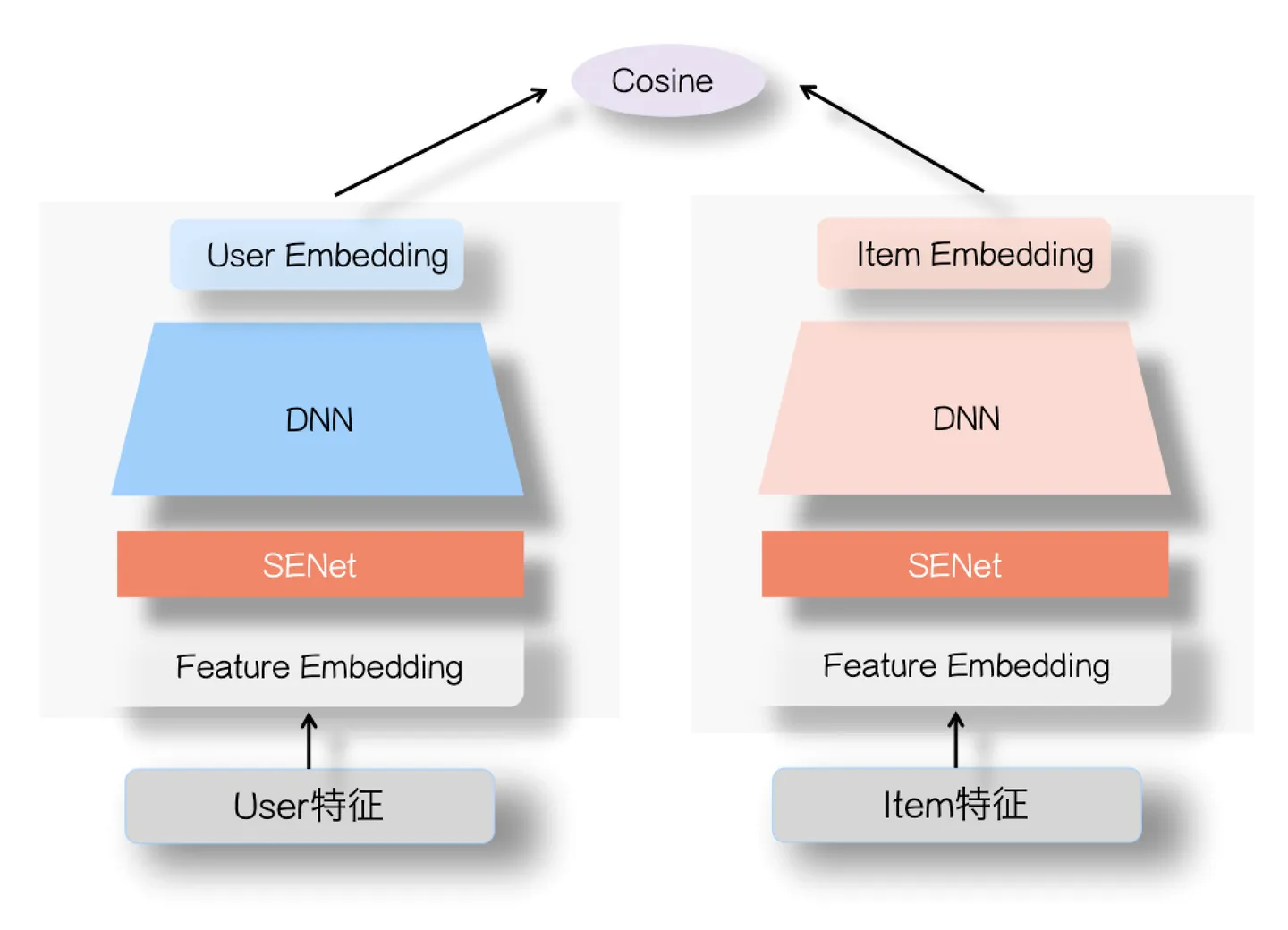
SENET双塔模型#
推荐阅读⭐️⭐️⭐️⭐️⭐️
在特征Embedding层上,各自加入一个SENet模块。两个SENet各自对User侧和Item侧的特征,进行动态权重调整,强化重要特征,弱化甚至清除掉不重要特征。
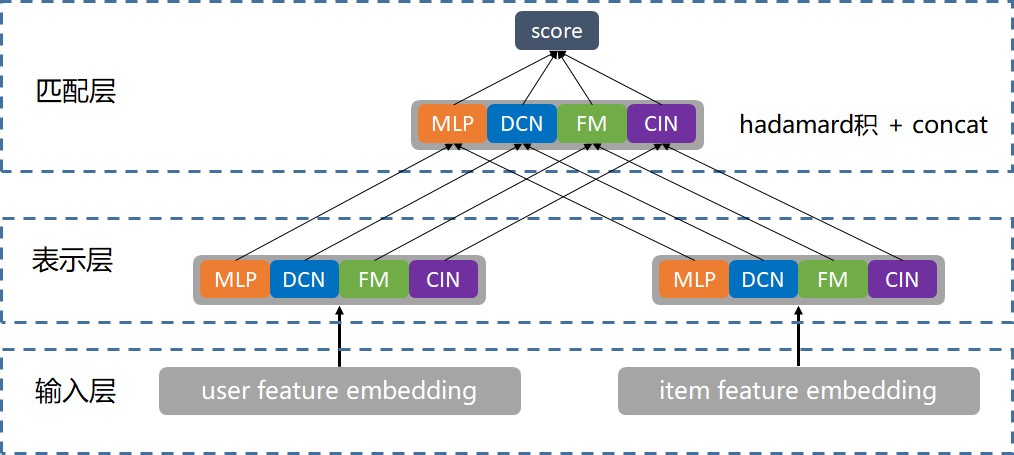
并联双塔#
推荐阅读⭐️⭐️⭐️⭐️⭐️
输入层:将 user 和 item 特征映射成 feature embedding,方便在表示层进行网络构建,小说场景下的 user 特征包括用户 id、用户画像(年龄、性别、城市)、行为序列(点击、阅读、收藏)、外部行为(浏览器资讯、腾讯视频等)。item 特征包括小说内容特征(小说 id、分类、标签等)、统计类特征等。所有特征都经过离散化后再映射成embedding。
表示层:并联各种深度神经网络模块(MLP、DCN、FM、CIN 等)从多个角度学习输入层 feature 的融合和交互,生成并联的 user、item 向量用于匹配层计算。这里user-user 和 item-item 的特征交互直接在塔内的网络结构可以做到,而 user-item的特征交互只能通过顶层的内积操作实现,所以这里网络结构的设计重点是提升双塔结构的 user-item 的特征交互能力。
匹配层:将表示层得到的并联 user 和 item 向量进行 hadamard 积(相当于多个双塔拼接),再经过一个 LR 进行结果融合,在线 serving 阶段 LR 的每一维的权重可预先融合到 user embedding 里,从而保持在线打分仍然是内积操作。
在 QQ 浏览器小说推荐 CTR 预估上看训练效果,分别训练了各双塔结构的效果,然后再尝试“并联”多个双塔在一起的效果,如下表:

Google采样修正的双塔模型#
推荐阅读⭐️⭐️⭐️⭐️⭐️
《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》
简介#
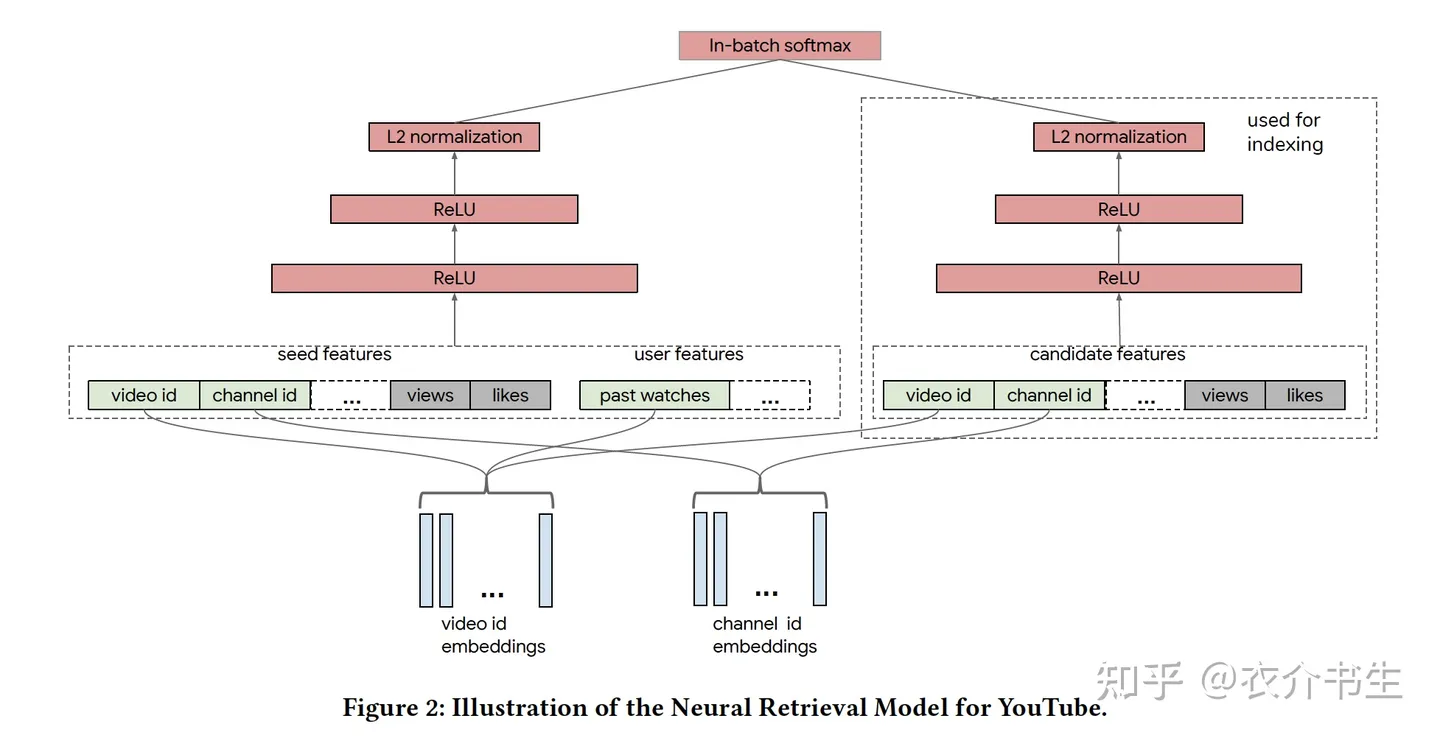
模型整体结构#
两个塔共用一个embedding层
用户侧特征主要基于用户的历史行为进行提取
物品侧特征既有类别特征,又有连续值特征,其中类别特征又分为单值特征和多值特征,对于多值特征,通常采用加权平均的方式计算得到最终的向量表示
label并不是点击即为1,未点击为0。当一个视频被完整看完时,label是1,当一个视频被点击但是观看时长非常短时,label是0
模型天级更新
主要的优化点#
负采样最常见的方式之一是batch内采样,这种采样方式的缺点就是会因随机采样偏差导致模型效果不好。简单来说热门物品被采样到的概率非常高,热门物品有更大的概率成为负样本,热门物品会被过度惩罚,论文采取streaming frequency estimation的方式对用户和物品的匹配度的计算结果进行修正,\(s^c(x_i, y_i) = s(x_i, y_i) - log(p_j)\),其中\(p_j\)表示物品j被采样到的概率,streaming frequency estimation的计算方式为:
定义词典A记录物品y上一次被采样到的训练时刻
定义词典B记录物品y的采样频率,B[y] = (1 - α) * B[y] + α(t - A[y])
Normalization: 对两侧embedding进行L2标准化
Temperature: 对内积计算结果,除以一个固定的超参
其他细节(可跳过该章节)#
损失函数 & batch softmax optimization#
假设训练集包含T条样本,物品数量为M:
其中x表示用户特征,y表示物品特征,r表示lable,x和y经过双塔模型分别得到对应的用户向量\(u(x, \theta)\)和物品向量\(v(y, \theta)\),通过计算用户向量和物品向量的内积表示用户和物品的匹配度:
模型将召回看做一个多分类问题,给定一个用户,可以通过以下softmax函数从M个物品中选出合适的物品:
损失函数如下:
上述损失函数存在的缺点就是当物品数量M非常巨大时,softmax函数计算量会非常大,常采用mini-batch的方式进行优化:
通过mini-batch的方式优化损失函数相当于把一个batch内的其他物品当做负样本,这种做法的缺点就是会因随机采样偏差导致模型效果不好。简单来说热门物品被采样到的概率非常高,热门物品有更大的概率成为负样本,热门物品会被过度惩罚,文章对用户和物品的匹配度的计算结果进行修正:
其中\(p_j\)表示物品j被采样到的概率,修正后的softmax函数如下:
修正后的损失函数如下:
模型训练流程#
模型训练流程可以简单归纳为以下几步:
从实时数据流中采样得到一个batch的样本
计算每个物品\(y_i\)被采样的概率\(p_i\)(streaming frequency estimation)
计算修正后的损失函数
利用SGD更新模型参数

streaming frequency estimation#
由于系统中会不断的有新物品出现,使用固定长度的词表不太合适,因此采用hash的方式来对物品的采样概率进行更新。假设有一个散列地址大小为H的hash函数h,对物品ID进行映射。同时使用两个长度为H的数组A和B,通过\(h(y)\)来得到其在数组A和B中下标。
\(A[h(y)]\)记录上一次物品y被采样到的训练时刻
\(B[h(y)]\)记录物品y采样的预估频率(预估频率的意思是预估每过多少步可以被采样到一次)
假设第t步物品y被采样到:
\(B[h(y)] \gets (1-\alpha) \cdot B[h(y)] + \alpha \cdot (t - A[h(y)])\),其中\(\alpha\)为学习率
\(A[h(y)]\)更新为当前的训练步骤t
预估物品y的采样概率为\(1/B[h(y)]\)。

既然是hash过程,当H<<M时,就会存在冲突,冲突会导致\(B[h(y)]\)较小,从而导致采样概率偏高。改进方案是使用multiple hashings。即使用多组hash方程和数组A和B。当训练完成时使用最大的一个\(B[h(y)]\)去计算采样概率。具体过程如下:

Normalization and Temperature#
文中还介绍了双塔模型的另外两个优化点:
对两侧输出的embedding进行L2标准化,如:
对于内积计算的结果,除以一个固定的超参:
阿里实践(粗排)#
推荐阅读⭐️⭐️⭐️⭐️⭐️
粗排的技术发展历史#
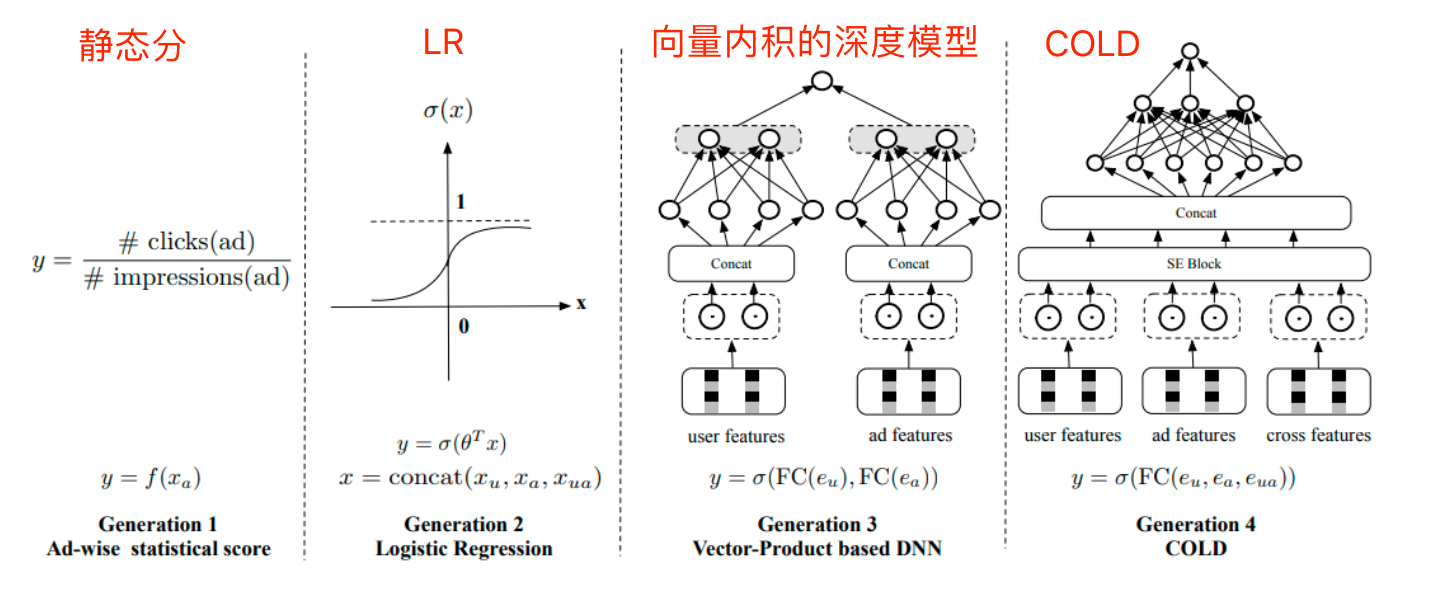
向量内积模型的优点和问题#
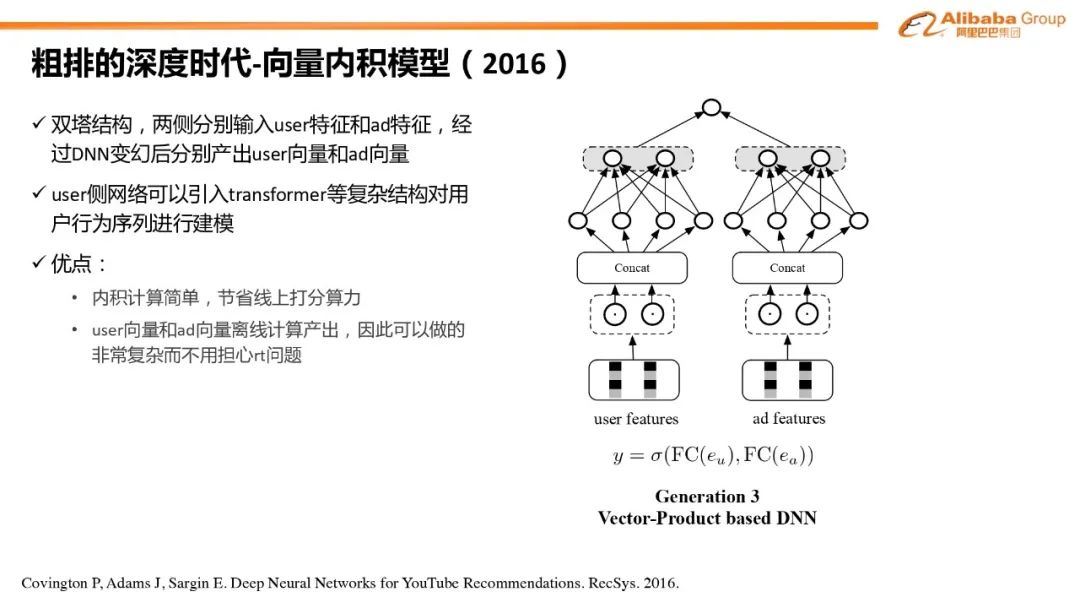
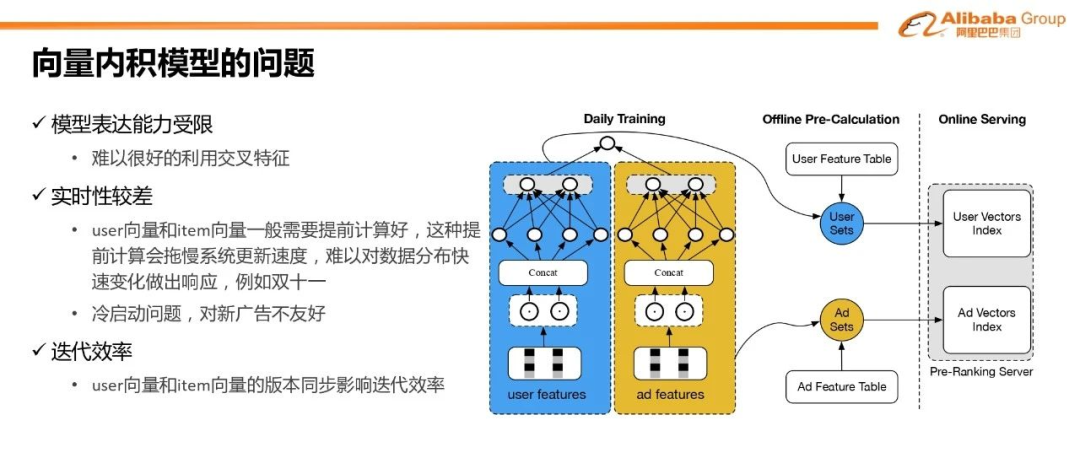
针对向量内积模型的改进方案#
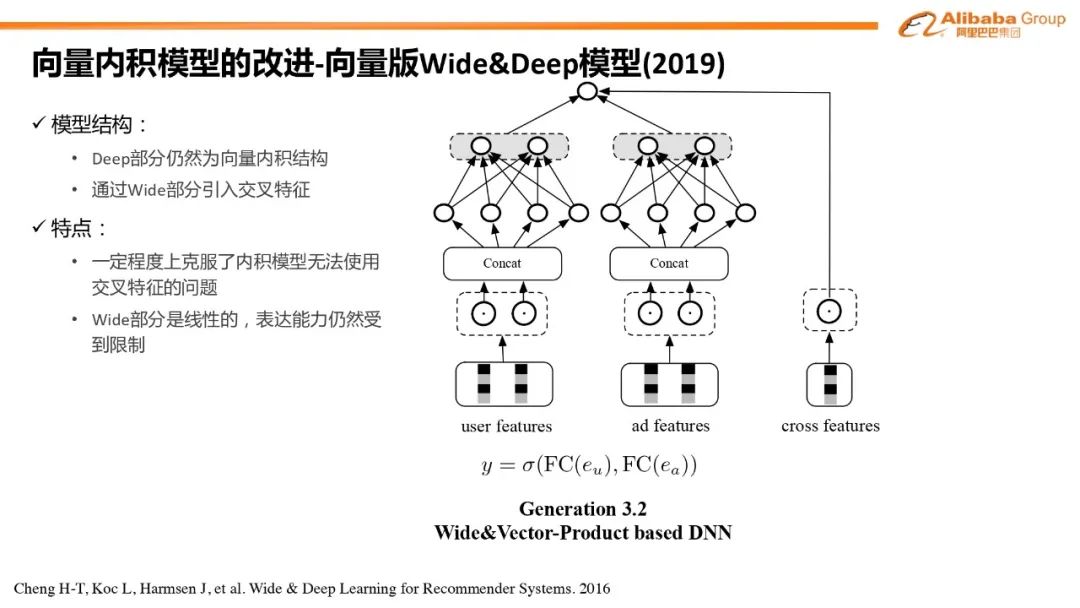
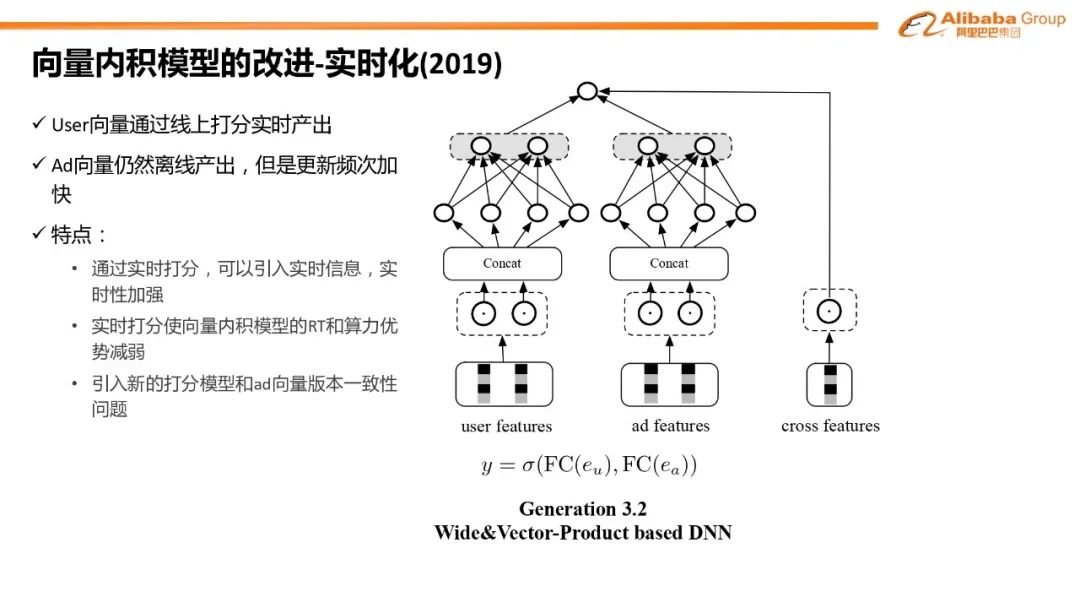
新一代粗排架构#
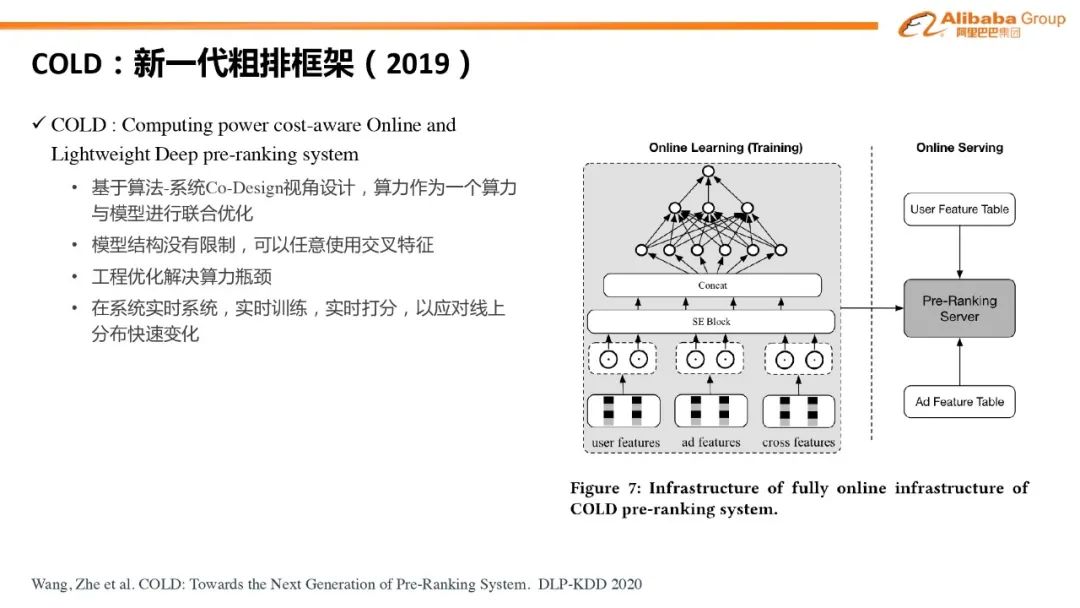
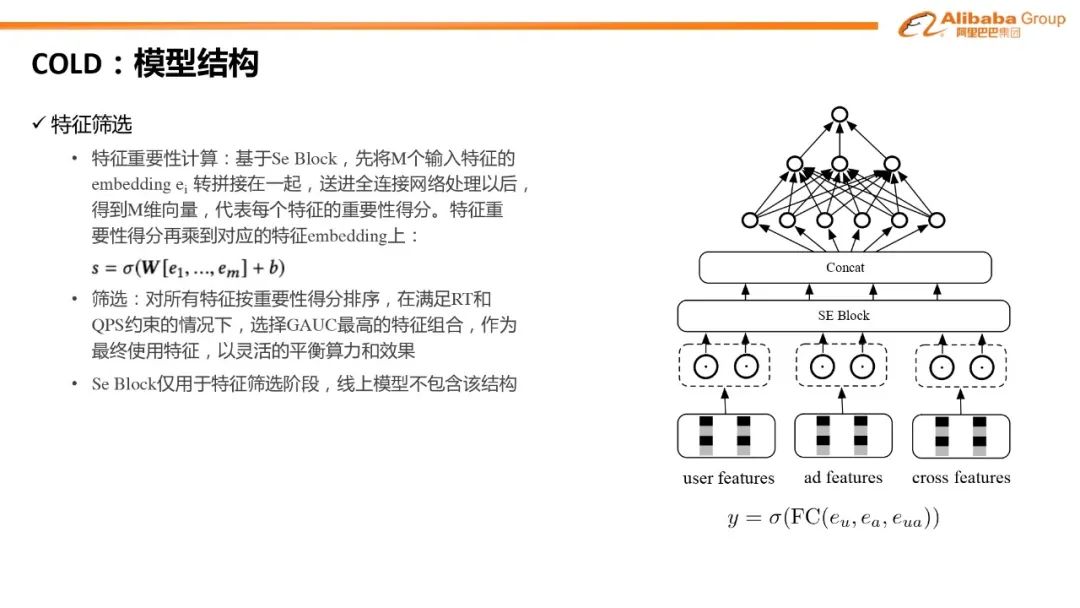

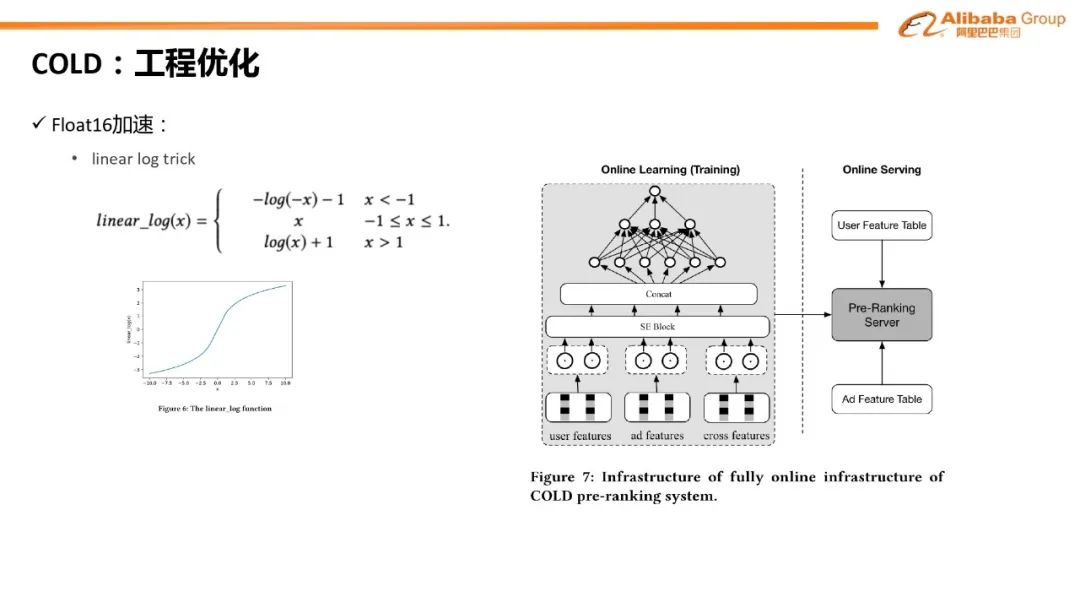
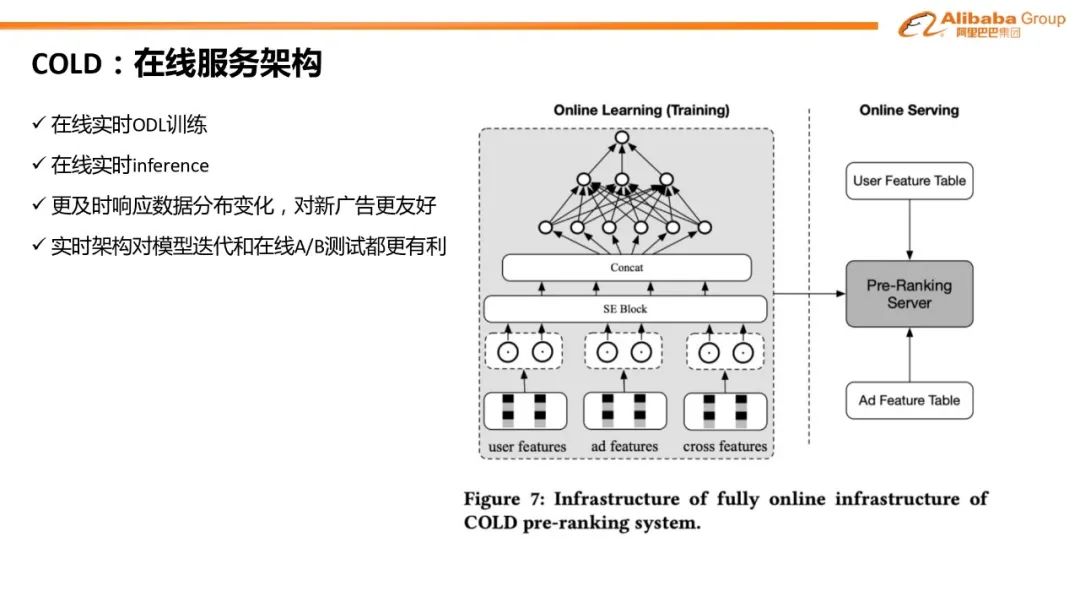
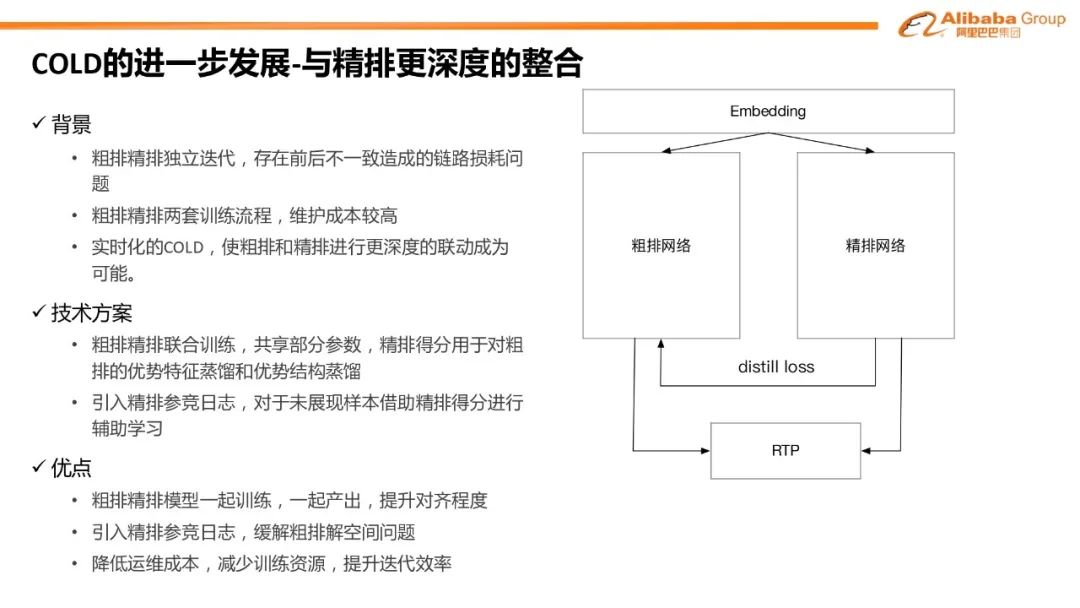
对比学习:双塔模型 item 侧引入对比学习辅助 loss#
推荐阅读⭐️⭐️⭐️⭐️⭐️
解决长尾问题#
对比学习在召回和排序上的应用,主要解决的是长尾user或item如何学的更好的问题。因为长尾user和item在模型中的训练机会不多,因此通过拉近其与头部user或item向量的距离,可以让它们学的更充分。
如何构建负例#
我们一般采用batch内负采样,因为batch内包含的是所有样本,每个样本都有可能成为负例,这样负例的选择面更广、更均匀,训练后模型的uniformity会更大,因此可以防止模型的坍塌。其次,我们需要增加负采样的个数,显然负样本越多,模型的uniformity也越大。此外,batch内负采样可能引入了大量easy负样本,因此一般结合使用温度系数,可以让模型更关注hard负样本。
实例#
在item侧,将item特征随机dropout掉一部分,或者mask掉一部分,形成两个新的item特征,且这两个特征互相作为正例,学习一个新的对比loss。其中辅助任务item网络参数和主任务item网络参数是共享的,负样本同样使用batch内负采样实现,α用来控制辅助loss的权重。同样,在user侧也可以这样做,实验表明都是有效的。
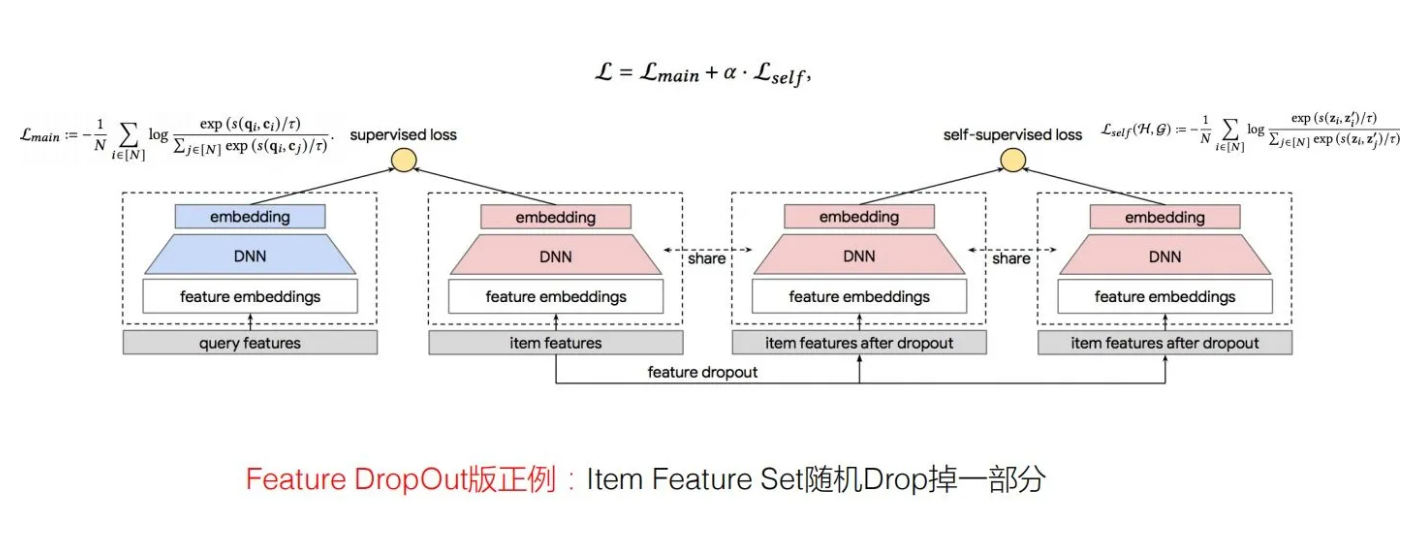
总结#
并联双塔:尝试通过"并联"多个双塔结构(MLP、DCN、FM、FFM、CIN)增加双塔模型的"宽度"来缓解双塔内积的瓶颈从而提升效果。
粗/精排联合训练
引入交叉特征
对比学习(特征mask)
网络结构优化